15336907
Description
Quiz by Andres Sanabria, updated more than 1 year ago
|
|
Created by Andres Sanabria
about 6 years ago
|
|
Question 1
Question
Este método de estimación suele ser más intuitivo y matemáticamente más sencillo.
A que método hace referencia el siguiente concepto general.
Answer
-
Máxima Verosimilitud
-
MCO
-
Mínima Verosimilitud
-
Máximos Cuadrados Ordinarios
Question 2
Question
El método de mínimos cuadrados presenta propiedades estadísticas muy atractivas que lo han convertido en uno de los más eficaces y populares del análisis de regresión.
Cual fue el autor de este método:
Answer
-
Carl Friedrich Gauss
-
Gujarati
-
Jhon Maynard Keynes
-
Jhon Arrow
Question 3
Question
Se pueden emplear en la función de regresión para poder analizar eficazmente datos estadísticos la función de regresión muestral.
A que hace referencia la siguiente formula:
Yi = B1+B2Xi+ ui
Answer
-
FRP de una variable
-
FRP de tres variables
-
FRP de cuatro variables
-
FRP de dos variables
Question 4
Question
Para poder determinar la FMR primero hay que establecer una ecuación que sea el paso inicial para poder realizar el respectivo desarrollo.
A que hace referencia esta fórmula:
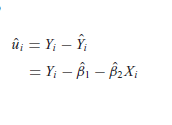{kind=link}
Answer
-
Muestra que los uˆi (los residuos) son simplemente las diferencias entre los valores observados y los estimados de Y.
-
Muestra que los uˆi (los residuos) son simplemente las diferencias entre los valores observados y los estimados de X.
-
No muestra que los uˆi (los residuos) son simplemente las diferencias entre los valores observados y los estimados de Y.
-
Muestra que los uˆi (los residuos) son simplemente las similitudes entre los valores observados y los estimados de Y.
Question 5
Question
Propiedades numéricas son las que se mantienen como consecuencia del uso de mínimos cuadrados ordinarios, sin considerar la forma como se generaron los datos
Seleccione las propiedades estadísticas de los estimadores MCO.
Answer
-
Los estimadores de MCO se expresan únicamente en términos de las cantidades (es decir, X y Y) observables (es decir, muestras). Por consiguiente, se calculan con facilidad.
-
Los estimadores de MCO se expresan diversamente en términos de las cantidades (es decir, X y Y) observables (es decir, muestras). Por consiguiente, se calculan con facilidad.
-
Son estimadores puntuales: dada la muestra, cada estimador proporciona un solo valor(puntual) del parámetro poblacional pertinente.
-
Son estimadores impuntuales: dada la muestra, cada estimador proporciona un solo valor (puntual) del parámetro poblacional pertinente.
Question 6
Question
El modelo econométrico es empírico (práctico, basado en la experiencia y en la observación de los hechos), no determinista (teórico, totalmente predecible en un momento dado si fuera posible conocer todos los datos).
¿Cuál es el estimador que se expresa en términos de las cantidades?
Answer
-
Máxima verosimilitud
-
Mínimos cuadrados ordinarios
-
Estimadores por intervalos
-
Mínima verosimilitud
Question 7
Question
Una vez obtenidos los estimadores de MCO de los datos de la muestra, se obtiene sin problemas la línea de regresión muestral.
Seleccione la serie de pasos para obtener la línea de regresión muestral.
Answer
-
Pasa a través de las medias muéstrales de Y y X. 2.- El valor medio de Y estimada Yˆi es igual al valor medio de Y real. 3.- El valor medio de los residuos uˆ1 es cero.4.- Los residuos uˆi no están correlacionados con el valor pronosticado de Yi 5.- Los residuos uˆi no están correlacionados con Xi; es decir, ˆu i Xi = 0.
-
El valor medio de Y estimada Yˆi es igual al valor medio de Y real. 2.- El valor medio de los residuos uˆ1 es cero. 3.- Los residuos uˆi no están correlacionados con el valor pronosticado de Yi 4.- Los residuos uˆi no están correlacionados con Xi; es decir, ˆu i Xi _ 0. 5.-Pasa a través de las medias muéstrales de Y y X.
-
El valor medio de Y estimada Yˆi es igual al valor medio de Y real. 2.- Los residuos uˆi no están correlacionados con el valor pronosticado de Yi 3.- El valor medio de los residuos uˆ1 es cero. 4.- Los residuos uˆi no están correlacionados con Xi; es decir, ˆu i Xi _ 0. 5.-Pasa a través de las medias muéstrales de Y y X.
Question 8
{kind=link}
Answer
-
Forma de desviación
-
Forma de correlación
-
Forma de estimación
-
Forma de auto desviación
Question 9
Question
El modelo de Gauss, modelo clásico o estándar de regresión lineal (MCRL), es el cimiento de la mayor parte de la teoría econométrica.
Cuál de estos supuestos pertenece al teorema de Gauss Markov
Answer
-
Modelo lineal en los parámetros.
-
Media nula y exogeneidad estricta
-
Homocedasticidad
-
Todas las anteriores
Question 10
Question
La inferencia estadística es el conjunto de métodos y técnicas que permiten inducir, a partir de la información empírica proporcionada por una muestra, cual es el comportamiento de una determinada población con un riesgo de error medible en términos de probabilidad y consta de dos ramas.
Cuáles son estas ramas en las que se divide.
Answer
-
Estimación y Prueba de hipótesis
-
Varianza y Estimación
-
Hipótesis y Varianza
-
Regresión Lineal y Estimación
Question 11
Question
Decimos que son estimadores y que sus valores cambiarán de muestra en muestra.
¿Cómo se les denomina?
Answer
-
Variables estimadas
-
Variables proyectadas
-
Variables aleatorias
-
Variables estadísticas.
Question 12
Question
El modelo clásico de regresión lineal normal puede dar solución a algo que los otros modelos.
A que se refiere:
Answer
-
El MCRLN hace suposiciones respecto a la naturaleza probabilística de ui.
-
Que trabaja con más variables.
-
Es más precisa que los otros modelos.
-
Engloba un amplio número de variables.
Question 13
Question
En el contexto de regresión se supone, por lo general, que las u tienen la distribución de probabilidad normal. Si a los supuestos del modelo clásico de regresión lineal (MCRL) se añade el supuesto de normalidad para ui
Que se obtiene de esto?
Answer
-
Obtenemos el MCO
-
Obtenemos el modelo clásico de regresión lineal normal (MCRLN).
-
Obtenemos el modelo clásico de regresión lineal.
-
Obtenemos el modelo de mínimos cuadrados.
Question 14
Question
El modelo clásico de regresión lineal normal supone que cada ui está normalmente distribuida con algunos supuestos.
Estos supuestos se expresan de manera más compacta como:
Answer
-
Image:4 (binary/octet-stream)
-
Image:5 (binary/octet-stream)
-
Image:3 (binary/octet-stream)
-
Image:6 (binary/octet-stream)
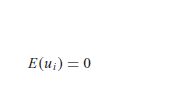{kind=link}
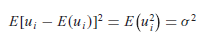{kind=link}
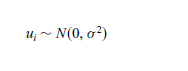{kind=link}
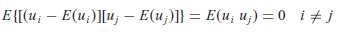{kind=link}
Question 15
Question
Teorema central del límite (TCL)
¿Que nos demuestra este teorema?
Answer
-
a) Demuestra que si existe un gran número de variables aleatorias dependientes con idéntica distribución.
-
b) Demuestra la variación de las variables estimadas.
-
c) Demuestra la diferencia entre las variables estimadas y la correlación de las variables.
-
d) Demuestra que, si existe un gran número de variables aleatorias independientes con idéntica distribución, entonces, con pocas excepciones, la distribución de su suma tiende a ser normal a medida que se incrementa al infinito el número de tales variables
Question 16
Question
La distribución normal es una distribución comparativamente sencilla y requiere sólo dos parámetros.
Cuáles son?
Answer
-
a) La media y la varianza
-
b) La estimación y la media
-
c) La media y las correlaciones
-
a) Las correlaciones y la hipótesis
Question 17
Question
Si trabajamos con una muestra finita o pequeña, la suposición de normalidad desempeña un papel relevante
¿Cuantos datos u observaciones se necesitan para que se cumpla el papel relevante de la muestra?
Answer
-
a) 100 datos o mas
-
b) 300 datos o menos
-
c) 200 datos o mas
-
d) 100 datos o menos
Question 18
Question
Propiedades de los estimadores de MCO
según el supuesto de normalidad.
Seleccione la respuesta correcta.
Answer
-
a) Son insesgados.
-
b) Tienen varianza mínima.
-
c) Presentan consistencia
-
d) Todas las anteriores
Question 19
Question
Existe un método de estimación puntual con algunas propiedades teóricamente más fuertes que las del método de MCO.
¿Cómo se llama este método?
Answer
-
a) método de máxima verosimilitud (MV)
-
b) método de los mínimos cuadrados ordinarios
-
c) modelo clásico de regresión lineal
-
d) modelo clásico de regresión lineal normal.
Question 20
Question
A pesar de la tendencia de los padres de estatura alta a procrear hijos altos y los padres de estatura baja, hijos bajos, la estatura promedio de los niños de padres de una estatura determinada tendía a desplazarse.
Quien acuño el término de regresión.
Answer
-
A) Francis Galton
-
B) Francis Quesnay
-
C) Milton Friedman
-
D) Alfred Marshall
Question 21
Question
El análisis de regresión es el estudio de la dependencia de una variable dependiente respecto de una o más variables explicativas.
El objetivo que persigue es:
Answer
-
A) Estimar o predecir la media o valor promedio poblacional de la primera en términos de los valores conocidos o fijos (en muestras no repetidas) de las segundas.
-
B) Estimar o predecir la media o valor promedio poblacional de la primera en términos de los valores conocidos o fijos (en muestras repetidas) de las segundas.
-
C) Estimar o predecir la media o valor promedio muestral de la primera en términos de los valores conocidos o fijos (en muestras repetidas) de las segundas.
-
D) Estimar o predecir la media o valor promedio poblacional de la segunda en términos de los valores variables (en muestras repetidas) de las segundas.
Question 22
Question
En un ejemplo práctico, lo que interesa es predecir la estatura promedio de los hijos a partir de la estatura de sus padres.
Si esto, corresponde a un diagrama de dispersión, para su determinación se necesitara una línea recta.
Answer
-
A) Recta Oblicua
-
B) Recta semántica
-
C) Recta de regresión
-
D) Recta con dispersión
Question 23
Question
A un economista quizá le interese estudiar la dependencia del consumo personal respecto del ingreso personal neto disponible, después de
Impuestos.
Con un análisis de este tipo, en el diagrama de dispersión , se calcula:
Answer
-
A) la propensión marginal decreciente
-
A) la propensión marginal a producir
-
C) la propensión promedio de la demanda
-
D) la propensión marginal a consumir
Question 24
Question
En el análisis de regresión interesa lo que se conoce como dependencia estadística entre variables, no así la funcional o determinista, propia de la física clásica.
En las relaciones estadísticas, analizamos
Answer
-
A) Variables aleatorias o estocásticas
-
B) Variables explicativas o independientes
-
C) Variables dependientes
-
D) Variables de aquilatacion
Question 25
Question
A pesar de que el análisis de regresión tiene que ver con la dependencia de una variable respecto de otras variables, esto no implica causalidad necesariamente.
En otras palabras Kendall y Stuart manifiestan:
Answer
-
A) “Una relación estadística, por más fuerte y sugerente que sea, siempre podrá establecer una conexión causal: nuestras ideas de causalidad deben provenir de estadísticas externas y, en último término, de una u otra teoría”.
-
B) “Una relación estadística, por más fuerte y sugerente que sea, nunca podrá establecer una conexión causal: nuestras ideas de causalidad deben provenir de estadísticas externas y, en último término, de una u otra teoría”.
-
C) “Una relación estadística, por más fuerte y sugerente que sea, nunca podrá establecer una conexión informal: nuestras ideas de causalidad deben provenir de estadísticas externas y, en último término, de una u otra teoría”.
-
D) “Una relación estadística, por más fuerte y sugerente que sea, nunca podrá establecer una conexión informal: nuestras ideas de causalidad deben provenir de estadísticas internas y, en último término, de una u otra teoría”.
Question 26
Question
Se relaciona de manera estrecha con el de regresión, aunque conceptualmente los dos son muy diferentes.
En el análisis de correlación, el objetivo principal es
Answer
-
A) medir la fuerza o el grado de asociación no lineal entre dos variables
-
B) medir la relación inversa entre dos variables
-
C) medir la fuerza o el grado de asociación lineal entre dos variables
-
D) medir la fuerza o el grado de competitividad entre dos variables
Question 27
Question
Si se estudia la dependencia de una variable respecto de más de una variable explicativa, como el rendimiento de un cultivo, la lluvia, la temperatura, el Sol y los fertilizantes
A qué tipo de análisis se refiere
Answer
-
A) análisis de regresión múltiple
-
B) análisis de regresión simple
-
C) análisis de regresión aleatorio
-
D) análisis de regresión transversales
Question 28
Question
El éxito de todo análisis econométrico depende a final de cuentas de la disponibilidad de los datos recopilados.
Hay tres tipos de datos disponibles para el análisis empírico:
Answer
-
a) series de tiempo, series explicativas e información combinada
-
B) series de tiempo, series transversales e información múltiples
-
C) series de tiempo, series transversales
-
D) series de tiempo, series transversales e información combinada (combinación de series de tiempo y transversales).
Question 29
Question
Los datos recopilados por estas organizaciones pueden ser de naturaleza experimental o no experimental.
En los datos experimentales, frecuentes en las ciencias naturales, el investigador suele….
Answer
-
ecabar los datos con algunos factores constantes y evaluar el efecto de otros en un fenómeno dado.
-
Recabar los datos con algunos factores constantes y evaluar el efecto de otros en un fenómeno dado.
-
cabar los datos con algunos factores constantes y evaluar el efecto de otros en un fenómeno dado.
-
abar los datos con algunos factores constantes y evaluar el efecto de otros en un fenómeno dado.
Question 30
Question
La línea de regresión poblacional.
Desde el punto de vista geométrico, una curva de regresión poblacional.
Answer
-
Es tan sólo el lugar geométrico de las medias condicionales de la variable dependiente para los valores fijos de las variables explicativas.
-
Es tan sólo el lugar geométrico de las medias condicionales de la variable independiente para los valores fijos de las variables explicativas.
-
Es tan sólo el lugar geométrico de las medias condicionales de la variable dependiente para los valores variables de las variables explicativas.
-
Es tan sólo el lugar geométrico de las medias condicionales de la variable dependiente para los valores fijos de las variables dependientes.
Question 31
Question
La función de esperanza condicional (FEC), función de regresión poblacional (FRP) o regresión poblacional (RP).
Simbólicamente
Answer
-
E(Y | Xi ) _ f (Yi )
-
E(Y | Xi ) _ f (Xi )
-
E(Y | Yi ) _ f (Xi )
-
E(Y | Xi ) _ f (YXi )
Question 32
Question
β1 y β2 son parámetros no conocidos pero fijos
Que se denominan
Answer
-
coeficientes de regresión
-
coeficientes de intersección y dependiente
-
Coeficientes independientes
-
Coeficientes lineales.
Question 33
Question
La relación sobre todo con modelos lineales en la estimación de FRP
El primer significado de Linealidad en las variables
Answer
-
Es aquel en que la esperanza condicional de X es una función lineal de Xi
-
Es aquel en que la esperanza condicional de Y es una función lineal de Yi
-
Es aquel en que la esperanza condicional de x es una función lineal de Yi
-
Es aquel en que la esperanza condicional de Y es una función lineal de Xi
Question 34
Question
La linealidad se presenta cuando la esperanza condicional de Y, E(Y | Xi), es una función lineal de los parámetros, los β; puede ser o no lineal en la variable X.
Es un modelo de regresión lineal en el parámetro
Answer
-
E(Y | Xi ) _ β1 + β2X2i
-
E(Y | Yi ) _ β1 + β2X2i
-
E(Y | Xi ) _ β1 + β2Y2i
-
E(Y | Xi ) _ β1 + β2X1i
Question 35
Question
La linealidad en los parámetros es pertinente para el desarrollo de la teoría de regresión
Mencione las dos interpretaciones de linealidad
Answer
-
Modelo de regresión lineal (en el parámetro) y modelo de regresión no lineal (en el parámetro)
-
Modelo de ascenso no lineal y modelo de regresión lineal
-
Modelo Semántico y modelo potencial
-
Modelo de regresión lineal (sin el parámetro) y modelo de regresión no lineal
Question 36
Question
A medida que aumenta el ingreso familiar, el consumo familiar, en promedio, también aumenta.
¿Qué sucede con el consumo de una familia en relación con su nivel de ingreso fijo?
Answer
-
El consumo de una familia en particular no necesariamente disminuye a medida que lo hace el nivel de ingreso
-
El consumo de una familia en particular no necesariamente aumenta a medida que lo hace el nivel de ingreso
-
El consumo de una familia en particular necesariamente aumenta a medida que lo hace el nivel de ingreso
-
El consumo de una familia no necesariamente es promedio a medida que lo hace el nivel de ingreso
Question 37
Question
Es una variable aleatoria no observable que adopta valores positivos o negativos.
Técnicamente, ui se conoce
Answer
-
Margen de aceptación
-
Margen de error
-
Desviación estándar
-
Perturbación estocástica o término de error estocástico.
Question 38
Question
¿Por qué no se crea un modelo de regresión múltiple con tantas variables como sea posible?
Las razones son:
Answer
-
Vaguedad de la teoría, falta de disponibilidad de datos
-
Variables centrales y variables periféricas, aleatoriedad intrínseca en el comportamiento humano, variables representantes (proxy) inadecuadas.
-
Principio de parsimonia, forma funcional incorrecta
-
Todas las anteriores
Question 39
Question
Conocido también como estadístico (muestral), no es más que una regla, fórmula o método para estimar el parámetro poblacional a partir de la información suministrada por la muestra disponible.
Este concepto de aleatoriedad, pertenece a:
Answer
-
Estimador
-
Estimación
-
Perturbación
-
Regresión
Question 40
Question
La regla básica de 2T
Señala que:
Answer
-
a) Si el número de grados de libertad es 20 o más, y si α, el nivel de significancia, se fi ja en 0.05, se rechaza la hipótesis nula β2 _ 0 si el valor de t [ _ β ˆ 2/ee (β ˆ 2)] es superior a 2 en valor absoluto.
-
b) Si el número de grados de libertad es 69 o más, y si α, el nivel de significancia, se fi ja en 0.10, se rechaza la hipótesis nula β2 _ 0 si el valor de t [ _ β ˆ 2/ee (β ˆ 2)] es superior a 6 en valor absoluto.
-
c) Si el número de grados de libertad es 10 o más, y si α, el nivel de significancia, se fi ja en 0.70, se rechaza la hipótesis nula β2 _ 0 si el valor de t [ _ β ˆ 2/ee (β ˆ 2)] es superior a 4 en valor absoluto.
-
d) Si el número de grados de libertad es 80 o más, y si α, el nivel de significancia, se fi ja en 0.30, se rechaza la hipótesis nula β2 _ 0 si el valor de t [ _ β ˆ 2/ee (β ˆ 2)] es superior a 7 en valor absoluto.
Question 41
Question
Si, con base en una prueba de significancia, por ejemplo, la prueba t, decidimos “aceptar” la hipótesis nula,
Todo lo que se afirma es que:
Answer
-
Con base en la evidencia dada por la muestra, existe razón para aceptarla; no se sostiene que la hipótesis nula sea falsa con absoluta certeza.
-
Con base en la evidencia dada por la muestra, no existe razón para rechazarla; no se sostiene que la hipótesis alternativa sea verdadera con absoluta certeza.
-
Con base en la evidencia dada por la muestra, no existe razón para aceptarla; no se sostiene que la hipótesis alternativa sea verdadera con absoluta certeza.
-
Con base en la evidencia dada por la muestra, no existe razón para rechazarla; no se sostiene que la hipótesis nula sea verdadera con absoluta certeza.
Question 42
Question
Construya un intervalo de confianza para β2 a 100(1 − α)%
LA Regla de decisión nos indica
Answer
-
Si el β2 en H1 se encuentra dentro de este intervalo de confianza, no rechace H1, pero si está fuera del intervalo, rechace H1.
-
Si el β2 en H1 se encuentra fuera de este intervalo de confianza, no rechace H0, pero si está fuera del intervalo, rechace H1.
-
Si el β2 en H0 se encuentra dentro de este intervalo de confianza, no rechace H0, pero si está fuera del intervalo, rechace H0.
-
Si el β2 en H1 se encuentra dentro de este intervalo de confianza, no acepte H1, pero si está fuera del intervalo, acepte H1.
Question 43
Question
En la hipótesis estadística .
Se denomina simple cuando:
Answer
-
Especifica los valores precisos de los parámetros de una función de densidad de probabilidad.
-
Especifica los valores inciertos de los parámetros de una función de densidad de probabilidad.
-
Especifica los valores imprecisos de los parámetros de una función de concentración de probabilidad.
-
No especifica los valores precisos de los parámetros de una función de densidad de probabilidad.
Question 44
Question
UNA O VARIAS variables explicativas son una combinación lineal aproximada de otra(s)
Se refiere a:
Answer
-
Multicolinealidad aproximada
-
Multicolinealidad exacta
-
Multicolinealidad continua
-
Multicolinealidad dispersa
Question 45
Question
La implicación que produce la multicolinealidad aproximada
¿Qué problemas genera en la estimación?
Answer
-
Cuanta mayor relación lineal entre X1 y el resto mayor varianza de β1. Estimación imprecisa e intervalos de confianza muy pequeñas.
-
Cuanta mayor relación lineal entre X0 y el resto mayor varianza de β0. Estimación imprecisa e intervalos de confianza muy pequeñas.
-
Cuanta mayor relación lineal entre X1 y el resto mayor varianza de β1.Estimación imprecisa e intervalos de confianza muy grandes.
-
Cuanta mayor relación lineal entre X0 y el resto mayor varianza de β0. Estimación imprecisa e intervalos de confianza muy grandes.
Question 46
Question
En esta sección estudiamos el análisis de regresión desde el punto de vista del análisis de varianza, y nos introduciremos en una forma complementaria de mirar el problema de la inferencia estadística.
como se denominan estos componentes.
Image:
7 (binary/octet-stream)
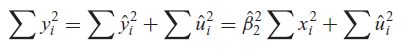{kind=link}
Answer
-
análisis de varianza
-
análisis de factores
-
análisis de estimación.
-
análisis de varianza.
Question 47
Question
Para “predecir” o “pronosticar” el salario promedio futuro Y correspondiente
a algún nivel dado de escolaridad X. Ahora, hay dos clases de predicciones
Señale la opción correcta:
Answer
-
Predicción individual y predicción muestral
-
Predicción múltiple y predicción media
-
Predicción media y predicción múltiple
-
Predicción media y predicción individual.
Question 48
Question
En el método clásico de la prueba de hipótesis
A la probabilidad se la conoce como valor p. Con que otro nombre se le conoce.
Answer
-
Nivel estimado
-
Nivel clásico
-
Nivel observado
-
Nivel probabilístico
Question 49
Question
La predicción del valor de la media condicional de Y correspondiente a un valor escogido X, por ejemplo, X0, que es el punto sobre la línea de regresión poblacional misma.
a que predicción hace referencia la siguiente formula.
Image:
8 (binary/octet-stream)
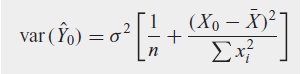{kind=link}
Answer
-
Predicción media.
-
Predicción individual.
-
Predicción múltiple.
-
Predicción de la varianza.
Question 50
Question
La hipótesis del ingreso permanente de Milton Friedman
Afirma que:
Answer
-
Que el consumo permanente es proporcional al ingreso permanente.
-
Que el consumo estático es proporcional al ingreso estático.
-
El consumo no permanente es proporcional al ingreso permanente.
-
El consumo inversamente proporcional al ingreso.
Question 51
Question
Aunque generalmente la hipótesis se formula sin mencionar el carácter condicional de la varianza.
Defina que es la Heterocedasticidad.
Answer
-
Es el análisis de regresión es un análisis de regresión condicional de “y” sobre “x”.
-
El modelo básico de regresión lineal exige, como hipótesis básica, que la varianza de las perturbaciones aleatorias, condicional a los valores de los regresores X
-
En un plano puramente analítico, la matriz de varianzas-covarianzas de las perturbaciones
-
Es una matriz de varianzas-covarianzas no escalar de las perturbaciones aleatorias, la estimación máximo verosímil de los parámetros del modelo
Question 52
Question
Lo que se conoce como el r 2 simple, es para el modelo de regresión a través del origen
Image:
9 (binary/octet-stream)
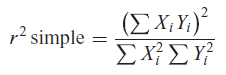{kind=link}
Answer
-
A pesar de que este r 2 simple satisface la relación 0 < r2 < 1, no es directamente comparable con el valor r 2 convencional.
-
Con estos resultados es fácil establecer relaciones entre estos dos conjuntos de parámetros estimados.
-
Los resultados de regresión basados en una escala de medición
-
la transformación de la escala (Y, X) a la escala (Y ∗, X ∗) no afecta las propiedades de los estimadores de MCO
Question 53
Question
La presencia de Heterocedasticidad sobre el MBRL
estimado con Mínimos Cuadrados Ordinarios
Los efectos, son:
Answer
-
El estimador de Mínimos Cuadrados Ordinarios sigue siendo lineal, insesgado y consistente, pero deja de ser eficiente (varianza mínima).
-
Las varianzas del estimador de Mínimos Cuadrados Ordinarios, además de no ser mínimas, no pueden calcularse con la expresión utilizada en presencia de homocedasticidad modelización de fenómenos que con tienen un mecanismo de auto - aprendizaje en función de los errores (desajustes) previos.
-
menor tamaño del error, sino además una varianza progresivamente inferior.
Question 54
Question
El poder explicativo del conjunto de variables Z sobre la representación de la varianza de las perturbaciones aleatorias es escaso.
Cuanto más cerca se encuentre de cero, las probabilidades del modelo son:
Answer
-
operatividad
-
Heterocedasticidad
-
homocedasticidad
-
Covarianza
Question 55
Question
La R*2, como proporción de la varianza de la endógena real que queda explicada por la estimada, debiera ser muy pequeña si la capacidad explicativa de los regresores considerados también es muy pequeña
Para encontrar el valor crítico en la HETEROCEDASTICIDAD
Answer
-
Expresión deducida por Brucsh y Pagan como producto del coeficiente u
-
Expresión deducida por Brucsh y Pigou como producto del coeficiente O
-
Expresión deducida por Breusch y Pagan como producto del coeficiente R*2
-
Expresión deducida por Bawek y Pagan como producto del coeficiente R*2
Question 56
Question
Como el coeficiente de la pendiente, β2, es tan sólo la tasa de cambio, ésta se mide en las unidades de la razón
a que se refiere, esta formula:
Image:
10 (binary/octet-stream)
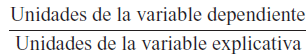{kind=link}
Answer
-
Advertencia sobre la Interpretación.
-
Perturbación
-
Regresión sobre variables Estandarizadas
-
Cambios en las unidades de medición
Question 57
Question
Variables estandarizadas
Se define como:
Answer
-
Una variable es estandarizada si se resta el valor de la media de esta variable de sus valores individuales y se divide esa diferencia entre la desviación estándar de la variable.
-
Una variable es estandarizada si se suma el valor de la media de esta variable de sus valores individuales y se divide esa diferencia entre la desviación estándar de la variable.
-
Una variable es estandarizada si se multiplica el valor de la media de esta variable de sus valores individuales y se divide esa diferencia entre la desviación estándar de la variable.
-
Una variable es estandarizada si se divide el valor de la media de esta variable de sus valores individuales y se divide esa diferencia entre la desviación estándar de la variable.
Question 58
Question
En la regresión de las variables la regresión de Y y X, si las redefinimos como:
A que variable hace referencia la siguiente formula
Image:
11 (binary/octet-stream)
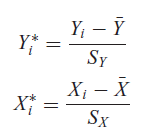{kind=link}
Answer
-
Variables fijas
-
Variables estandarizadas
-
Variables estimadas
-
Variables proporcionales
Question 59
Question
En las secciones que siguen consideraremos algunos modelos de regresión muy comunes, que pueden ser no lineales en las variables, pero sí lineales en los parámetros, o que pueden serlo mediante transformaciones apropiadas de
las variables.
Señale las formas funcionales de los modelos de regresión.
Answer
-
1. El modelo log-cuadratico.2. Modelos semilogarítmicos 3. Modelos recíprocos.4 El modelo logarítmico recíproco.
-
1. El modelo lineal .2. Modelos logarítmicos 3. Modelos recíprocos.4 El modelo logarítmico recíproco.
-
1. El modelo log-lineal.2. Modelos semilogarítmicos 3. Modelos recíprocos.4 El modelo logarítmico lineal.
-
1. El modelo log-lineal.2. Modelos semilogarítmicos 3. Modelos recíprocos.4 El modelo logarítmico recíproco.
Question 60
Question
Desde el principio conviene hacer una advertencia: el tema de la regresión con datos de panel es muy amplio, y parte de las matemáticas y las estadísticas que implica son muy complejas.
¿Cuál es una de las ventajas de los datos de panel respecto de los datos de corte transversal o de series de tiempo? Según Baltagi
Answer
-
Al combinar las series de tiempo de las observaciones de corte transversal, los datos de panel proporcionan “una mayor cantidad de datos informativos, más variabilidad, menos colinealidad entre variables, más grados de libertad y una mayor eficiencia”.
-
Los datos de panel permiten estudiar modelos de comportamiento más complejos, al hacer disponibles datos para varios miles de unidades.
-
Al remplazar las observaciones en unidades de corte transversal repetidas, los datos de panel resultan más adecuados para estudiar la dinámica del cambio. Los conjuntos de datos respecto del desempleo, la rotación en el trabajo y la movilidad laboral se estudian mejor con datos de panel.
-
La regresión con datos de paneles muy amplio, y parte de las matemáticas y las estadísticas que implica son muy complejas.
Question 61
Question
Las variables explicativas no son estocásticas. Si lo son, no están correlacionadas con el término de error.
¿Qué son las variables explicativas?
Answer
-
regresiones
-
estrictamente exógenas
-
series de tiempo
-
heterogeneidad
Question 62
Question
Advertencias sobre el modelo MCVD de efectos fijos
Un análisis precedente indica que el modelo MCVD presenta algunos problemas que es necesario tener en cuenta:
Answer
-
Si se introducen demasiadas variables dicótomas, puede presentarse el problema de los grados de libertad, con tantas variables dicótomas en el modelo, tanto individuales como interactivas o multiplicativas, siempre está presente la posibilidad de la multicolinealidad, que puede dificultar la estimación precisa de uno o más parámetros y en algunas situaciones, es posible que el modelo de MCVD no identifique el efecto de las variables que no cambian con el tiempo.
-
Podemos suponer que la varianza del error es la misma para todas las unidades de corte transversal, o que la varianza del error es heteroscedástica.
-
Para cada individuo, podemos suponer que no existe autocorrelación a través del tiempo.
-
en un determinado tiempo es posible que, el termino de error de una unidad no esté correlacionado con el termino de error de otra unidad.
Question 63
Question
En el método DG se expresa a cada variable como una desviación del valor medio de dicha variable.
¿Cuál es una desventaja de este estimador?
Answer
-
analiza estimaciones de regresión inadecuadas
-
obtener estimaciones directas de los intercepto
-
agregación variables no relacionadas
-
puede distorsionar los valores de los parámetros y desde luego eliminar los efectos de largo plazo
Question 64
Question
Al comentar sobre los MCVD, Kmenta escribe: Una pregunta obvia en conexión con el modelo de covarianza [es decir, MCVD] es si de verdad es necesario incluir variables dicótomas —con la consecuente pérdida de grados de libertad—.
El fundamento del modelo de covarianza es que:
Answer
-
Al especificar el modelo de regresión, no hemos podido incluir variables explicativas relevantes que no varíen con el tiempo
-
En los valores del intercepto de cada unidad se reflejan en el término de error
-
En el modelo de componentes de error
-
las unidades se muestran en forma de un universo
Question 65
Question
En un proceso estacionario, la velocidad de la reversión media depende de las autocovarianzas: es rápida si las autocovarianzas son pequeñas y lenta cuando son grandes, como veremos en breve.
¿Cuándo una serie de tiempo es estacionaria?
Answer
-
Cuando tenga una media que varía con el tiempo o una varianza que cambia con el tiempo, o ambas.
-
cuando sólo podemos estudiar su comportamiento durante el periodo en consideración.
-
cuando su media, su varianza y su autocovarianza (en los diferentes rezagos) permanecen iguales sin importar el momento en el cual se midan; es decir, son invariantes respecto del tiempo.
-
cuando su media, su varianza y su autocovarianza (en los diferentes rezagos) permanecen diferentes
Question 66
Question
Aunque la mayoría de las veces el interés se centra en las series de tiempo estacionarias, a menudo nos encontramos con series de tiempo no estacionarias, cuyo ejemplo clásico es el modelo de caminata aleatoria (MCA).
Hay dos tipos de caminatas aleatorias:
Answer
-
caminata aleatoria sin deriva o sin desvió
-
caminata aleatoria con deriva o con desvió
-
caminata aleatoria sin error
-
caminata aleatoria con correlación
Question 67
Question
Una prueba sencilla de estacionariedad se basa en la denominada función de autocorrelación (FAC).
La FAC en el rezago k, denotada por p_k, se define como:
Answer
-
p_k=y_k/y_0Image:P1 (binary/octet-stream)
-
p_0=y_k/y_0Image:P2 (binary/octet-stream)
-
p_ko=y_k/y_0Image:P3 (binary/octet-stream)
-
p_k=y_0/y_kImage:P4 (binary/octet-stream)
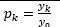{kind=link}
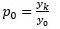{kind=link}
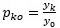{kind=link}
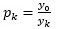{kind=link}
Question 68
Question
La autocorrelación se puede definir como la correlación entre miembros de series de observaciones ordenadas en el tiempo (información de series de tiempo) o en el espacio (información de corte de transversal).
Causa de la Autocorrelación:
Answer
-
Trabajo con datos de serie temporal: cuando se trabaja con datos de corte longitudinal, resulta bastante frecuente que el término de perturbación en un instante dado siga una tendencia marcada por los términos de perturbación asociados a instantes anteriores. Este hecho da lugar a la aparición de autocorrelación en el modelo.
-
Omisión de variables estimadoras:
-
Especificación incorrecta de los datos
-
Transformaciones de los datos con tendencia errónea
Question 69
Question
El mecanismo de corrección de errores (MCE), utilizado por primera vez por Sargan y popularizado más tarde por Engle y Granger, corrige el desequilibrio. Un importante teorema, conocido como teorema de representación de Granger.
¿Qué afirma este teorema?
Answer
-
los datos poseen tendencia determinista
-
relaciona la estocacidad de las variables
-
si dos variables Y y X están cointegradas, la relación entre las dos se expresa como MCE.
-
Y y X son valores rezagados de la ecuación
Question 70
Question
Los pronósticos a menudo son utilizados para poder predecir la demanda del consumidor de productos o servicios
En términos generales, hay cinco enfoques de los pronósticos económicos basados en series de tiempo.
Answer
-
1) Métodos de Suavizamiento Exponencial, 2) Modelos de Regresión Uniecuacionales, 3) Modelos de Regresión de Ecuaciones Simultáneas, 4) Modelos Autorregresivos Integrados de Promedios Móviles (ARIMA) y 5) Modelos de Vectores Autorregresivos (VAR).
-
1) Métodos de Suavizamiento Exponencial, 2) Modelos de Regresión Ecuacionales, 3) Modelos de Regresión de Ecuaciones Simultáneas, 4) Modelos Regresivos Integrados de Promedios Móviles (ARIMA) y 5) Modelos de Vectores Autorregresivos (VAR).
-
1) Método Exponencial, 2) Modelos de Regresión Uniecuacionales, 3) Modelos de Regresión de Ecuaciones Simultáneas, 4) Modelos Integrados de Promedios Móviles (ARIMA) y 5) Modelos de Vectores Autorregresivos (VAR).
-
1) Métodos de Suavizamiento Exponencial, 2) Modelos de Regresión Uniecuacionales, 3) Modelos de Regresión de Ecuaciones, 4) Modelos Autorregresivos de Promedios Móviles (ARIMA) y 5) Modelos de Vectores Autorregresivos (VAR).
Question 71
Question
Estos métodos eliminan las fluctuaciones aleatorias de la serie de tiempo, proporcionando datos menos distorsionados del comportamiento real de misma.
En los Métodos de Suavizamiento Exponencial existen diversos tipos identifique cuales son:
Answer
-
Suavizamiento Exponencial Simple, Método Lineal de Holt y el Método de Holt-Winters, Metodo Autorregresivo.
-
Suavizamiento Exponencial Simple, Método Lineal de Holt y el Método de Holt-Winters.
-
Suavizamiento Exponencial Simple, Método Lineal de Holt.
-
Suavizamiento Exponencial Simple, Método Lineal de Holt y el Método de Holt-Winters, Metodo Autorregresivo, Metodo de Variacion.
Question 72
Question
Para utilizar la metodología Box-Jenkins, debemos tener una serie de tiempo estacionaria o una serie de tiempo que sea estacionaria después de una o más diferenciaciones.
Identifique cuál de las opciones pertenece al objetivo de BJ [Box-Jenkins]
Answer
-
Identificar y estimar un modelo de regresión de una serie de tiempo.
-
Identificar y estimar un modelo estadístico que se interprete como una serie de tiempo.
-
Identificar y estimar un modelo estadístico que se interprete como generador de los métodos exponenciales.
-
Identificar y estimar un modelo estadístico que se interprete como generador de los datos muestrales.
Question 73
Question
La Metodología de Box-Jenkins de previsión consiste en encontrar un modelo matemático que represente el comportamiento de una serie temporal de datos.
Cuáles son los cuatro pasos que considera la Metodología de Box-Jenkins:
Answer
-
Identificación, Estimación, Examen de diagnóstico, Modelo Econométrico.
-
Identificación, Estimación, Examen de diagnóstico, Autocorrelación.
-
Identificación, Estimación, Examen de diagnóstico, Pronóstico.
-
Identificación, Estimación, Examen de diagnóstico, Método Exponencial.
Question 74
Question
Engle propuso el modelo ARCH, que significa modelo auto regresivo condicionalmente heterocedástico.
Determine en qué fecha se descubrió el modelo GARCH
Answer
-
1988
-
1982
-
1984
-
1994
Question 75
Question
La publicación de G. P. E. Box y G. M. Jenkins Time Series Analysis: Forecasting and Control, op. cit., marcó el comienzo de una nueva generación de herramientas de pronóstico.
La metodología de Box-Jenkins (BJ) también es conocida como:
Answer
-
Metodología PREDICTIVA
-
Metodología UNIECUACIONALES
-
Metodología ARIMA
-
Parámetros ESTIMADOS
Question 76
Question
En pocas palabras, la media y la varianza de una serie de tiempo débilmente estacionaria son………… y su………… es invariante en el tiempo.
Complete el siguiente enunciado:
Answer
-
Constantes-Covarianza
-
Integradas-Covarianza
-
Autorregresivos-Covarianza
-
Integradas- Autorregresivo
Question 77
Question
Proceso autorregresivo integrado de promedios móviles (ARIMA) utiliza variaciones y regresiones de datos estadísticos con el fin de encontrar patrones para una predicción hacia el futuro.
Cuál es el punto importante para utilizar la metodología Box-Jenkins
Answer
-
debemos tener una serie de tiempo estacionaria o una serie de tiempo que sea estacionaria después de cero diferenciaciones.
-
debemos tener una serie de tiempo estacionaria o una serie de tiempo que sea autorregresiva después de una o más diferenciaciones.
-
debemos tener una serie de tiempo estacionaria o una serie de tiempo que sea integrada después de una o más diferenciaciones.
-
debemos tener una serie de tiempo estacionaria o una serie de tiempo que sea estacionaria después de una o más diferenciaciones.
Question 78
Question
Después de seleccionar un modelo ARIMA particular y de estimar sus parámetros, tratamos de ver si el modelo seleccionado se ajusta a los datos en forma razonablemente buena, pues es posible que exista otro modelo ARIMA que también lo haga.
La Metodología de Box-Jenkins (BJ) considera cuatro pasos. Determinar a que paso corresponde el enunciado.
Answer
-
Examen de diagnóstico.
-
Estimación
-
Identificación.
-
Pronóstico
Question 79
Question
La esencia de los modelos VAR se propone un sistema de ecuaciones, con tantas ecuaciones como series a analizar o predecir, pero en el que no se distingue entre variables endógenas y exógenas.
Los modelos de vectores autorregresivos el término “autorregresivo” se refiere:
Answer
-
A la aparición del valor rezagado de la variable dependiente en el lado izquierdo, y el término “vector” se atribuye a que tratamos con un vector de dos (o más) variables.
-
A la aparición del valor rezagado de la variable dependiente en el lado derecho, y el término “vector” se atribuye a que tratamos con un vector de cero variables.
-
A la aparición del valor rezagado de la variable dependiente en el lado perpendicular, y el término “vector” se atribuye a que tratamos con un vector de dos (o más) variables.
-
A la aparición del valor rezagado de la variable dependiente en el lado derecho, y el término “vector” se atribuye a que tratamos con un vector de dos (o más) variables.
Question 80
Question
En el presente caso, en el que la variable explicativa es el uso de celulares en un 100%, donde las variables dependientes Y son el uso de internet, mismo que han variado por los cambios en el uso o no uso de celulares, desde un 9.198% a 19.408%, y la otra variable que no ha variado por el efecto de contribución del PIB es el del Ingreso de 10 mil USD
En términos matemáticos se representa como:
Answer
-
Y_i=β_0 X_i^1+β_1 X_i^2+〖β_2 X〗_i^3+u_i
-
Y_i=β_0+β_1 X_i^1+〖β_2 X〗_i^2+u_i
-
Y_i=β_0+β_1 X_i^1+〖β_2 X〗_i^2
-
Y_i=β_0+β_1 X_i^1+〖β_2 X〗_i^2+u_i X_i^3
Question 81
Question
Una medida que indique el grado de ajuste de la recta de regresión muestral con los datos se denomina medida de bondad del ajuste. Su medida más conocida es: el coeficiente de determinación o R cuadrado (R^2)
Esta medida se define de la siguiente manera:
Answer
-
R^2=(∑_(i=1)^n▒〖〖(y ̂〗_i-y ̂ ̅)〗^2 )/(∑_(i=1)^n▒〖〖(y〗_i-y ̅)〗^2 )Image:R1 (binary/octet-stream)
-
R^2=SE/ST=(∑_(t=1)^T▒〖〖(y ̂〗_t-y ̅)〗^2 )/(∑_(t=1)^T▒〖〖(y〗_t-y ̅)〗^2 )Image:R2 (binary/octet-stream)
-
R^2=ST/SE=(∑_(t=1)^T▒〖〖(y ̂〗_t-y ̅)〗^2 )/(∑_(t=1)^T▒〖〖(y〗_t-y ̅)〗^2 )Image:R3 (binary/octet-stream)
-
R^2=SE/ST=(∑_(i=1)^n▒〖〖(y ̂〗_i-y ̂ ̅)〗^2 )/(∑_(i=1)^n▒〖〖(y〗_i-y ̅)〗^2 )Image:R4 (binary/octet-stream)
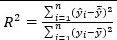{kind=link}
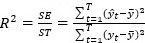{kind=link}
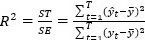{kind=link}
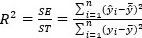{kind=link}
Question 82
Question
El Software Eviews permite calcular directamente la significatividad conjunta de los parámetros estimados del modelo a través del p-valor del contraste de la F siempre y cuando se introduzca la ecuación que define el modelo.
¿Qué sucede al pulsar aceptar?
Answer
-
al pulsar Aceptar se observa un p-valor de la F pequeño
-
al pulsar Aceptar se observa un p-valor de la F muy pequeño
-
al pulsar Aceptar se observa un p-valor de la F mediano
-
al pulsar Aceptar se observa un p-valor de la F grande
Question 83
Question
Otra forma de eliminar la heteroscedasticidad es aplicado logaritmo natural al modelo de la ecuación
Dado el modelo y_i=β_1 X_1i+β_2 X_2i+u_i encontrar su forma de logaritmo natural
Answer
-
ln〖.log(y_i )〗=ln(β_1 X_1i+β_2 X_2i+u_i)
-
ln(y_i )=log(β_1 X_1i+β_2 X_2i+u_i)
-
log(y_i )=ln(β_1 X_1i+β_2 X_2i+u_i)
-
ln(y_i )=ln(β_1 X_1i+β_2 X_2i+u_i)
Question 84
Question
La prueba general de heteroscedasticidad propuesta por White no se apoya en el supuesto de normalidad y es fácil aplicarla. Como ilustración de la idea básica, considere el siguiente modelo de regresión:
y_i=β_1+β_2 X_2i+β_3 X_3i+u_i
Para realizar la prueba de White se procede de la siguiente forma:
Answer
-
Paso 1. Dada la información, estime) y obtenga los residuos u ̂_i Paso 2. Efectúe la siguiente regresión (auxiliar):u ̂_i^2=a_1+a_2 x_2i+a_3 x_3i+a_4 x_2ⅈ^2+a_5 x_3ⅈ^2+a_6 x_2i x_3i+v_i
-
Paso 3. Según la hipótesis nula de que no hay heteroscedasticidad,n⋅R_(asin) ̃^2 〖 X〗_gl^2 Paso 4. Si el valor ji cuadrada obtenido en (el paso 3) excede al valor ji cuadrada crítico en el nivel de significancia seleccionado, la conclusión es que hay heteroscedasticidad.
-
Paso 1. Dada la información, estime) y obtenga los residuos u ̂_i Paso2.Según la hipótesis nula de que no hay heteroscedasticidad,n⋅R_(asin) ̃^2 〖 X〗_gl^2
-
Paso 3. Efectúe la siguiente regresión (auxiliar):u ̂_i^2=a_1+a_2 x_2i+a_3 x_3i+a_4 x_2ⅈ^2+a_5 x_3ⅈ^2+a_6 x_2i x_3i+v_i Paso 4. Si el valor ji cuadrada obtenido en (el paso 3) excede al valor ji cuadrada crítico en el nivel de significancia seleccionado, la conclusión es que hay heteroscedasticidad.
Question 85
Question
Las técnicas de estimación dependen de que se cuente con un panel corto o uno largo.
Existen cuatro posibilidades.
Answer
-
Modelo de MCO agrupados. Modelo de mínimos cuadrados con variable dicótoma (MCVD) de efectos fijos. Modelo de efectos fijos dentro del grupo. Modelo de efectos aleatorios (MEFA).
-
Modelo de MCO. Modelo de mínimos cuadrados con variable dicótoma (MCVD) de efectos fijos. Modelo de efectos fijos dentro del grupo. Modelo de efectos aleatorios (MEFA).
-
Modelo de MCO agrupados. Modelo de mínimos cuadrados con variable dicótoma (MCVD) de efectos reales. Modelo de efectos fijos dentro del grupo. Modelo de While
-
Modelo de MCO separados. Modelo de mínimos cuadrados con variable dicótoma (MCVD) de efectos fijos. Modelo de efectos de regresión. Modelo de efectos aleatorios (MEFA).
Question 86
Question
Para ver cómo el término de error se correlaciona con las regresoras, considere la siguiente revisión del modelo〖C 〗_it=β_1+β_2 〖PF〗_it+β_3 〖LF〗_it+β_4 M_it+u_it
Donde la variable adicional M filosofía de la administración o calidad de la administración. De las variables en la ecuación (dada), sólo la variable M es ______ o ______ porque varía entre sujetos, pero es constante a través del tiempo para un sujeto dado.
Answer
-
invariante en el tiempo o regresora
-
invariante en el tiempo o constante en el tiempo
-
serie de tiempo o constante en el tiempo
-
invariante en el tiempo o MCO
Question 87
Question
En el MEF se permite que el intercepto en el modelo de regresión difiera entre individuos, a manera de reconocimiento de que cada unidad individual, o transversal, pueda tener algunas características especiales por sí mismas. A fin de tomar en cuenta los distintos intercepto, se pueden utilizar variables dicótomas.
El MEF que emplea esas variables se conoce como:
Answer
-
MCDV
-
MEFA
-
MCE
-
MCO
Question 88
Question
El modelo de caminata aleatoria es un ejemplo de lo que se conoce como proceso de raíz unitaria.
Como este término es ya muy común en las referencias de series de tiempo, a continuación, explicaremos lo que es un proceso de raíz unitaria, como se escribe el MCA:
Answer
-
Y_t=pY_(i-1)+u_t −1 ≤ ρ ≤ 2
-
Y_t=pY_(t-2)+u_t −1 ≤ u ≤ 1
-
y_t=pY_(t-t)+u_t −1 ≤ t ≤ 1
-
Y_t=pY_(t-1)+u_t −1 ≤ ρ ≤ 1
Question 89
Question
Cointegración significa que, a pesar de no ser estacionarias en un nivel individual, una combinación lineal de dos o más series de tiempo puede ser estacionaria.
sirven para averiguar si dos o más series de tiempo están cointegradas.
Answer
-
Engle-Granger (EG)
-
Dickey-Fuller (DF)
-
Dickey-Fuller Aumentada (DFA)
-
Engle-Granger aumentada (EGA)
Question 90
Question
ˆi = 0.2033 + 0.6560Xt
ee = (0.0976) (0.1961)
r 2 = 0.397 SCR = 0.0544 SCE = 0.0358
donde Y = tasa de participación de la fuerza laboral (TPFL) de las mujeres en 1972 y X _=TPFL de las mujeres en 1968. Los resultados de la regresión se obtuvieron de una muestra de 19 ciudades de Estados Unidos.
Considere el siguiente resultado de una regresión:†
Answer
-
No hay asociación positivas en la misma fecha en 1972 y 1968, lo que no es sorprendente en vista de la realidad desde la segunda guerra mundial se ha producido un aumento constantes en las mismas fechas de la mujer.
-
No hay asociación negativas en la misma fecha en 1972 y 1968, lo que no es sorprendente en vista de la realidad desde la segunda guerra mundial se ha producido un aumento constantes en las mismas fechas de la mujer.
-
No hay asociación positivas en la misma fecha en 1972 y 1968, lo que no es sorprendente en vista de la realidad desde la primera guerra mundial se ha producido un aumento constantes en las mismas fechas de la mujer.
-
No hay asociación positivas en la misma fecha en 1972 y 1968, lo que no es sorprendente en vista de la realidad desde la segunda guerra mundial se ha producido una disminución constantes en las mismas fechas de la mujer.
Question 91
Question
¿Sería apropiado ajustar un modelo de regresión de dos variables a los datos? ¿Por qué? Si la respuesta es negativa, ¿qué tipo de modelo de regresión se ajustaría a los datos? ¿Cuenta con las herramientas necesarias para ajustar dicho modelo?
Determine la respuesta correcta del siguiente enunciado
Answer
-
Como resultado de ello, si sería conveniente que se ajuste a un modelo de regresión lineal bivariado de los datos.
-
Como resultado de ello, no sería conveniente que se ajuste a un modelo de regresión lineal bivariado de los datos.
-
Como resultado de ello, tal vez sería conveniente que se ajuste a un modelo de regresión lineal bivariado de los datos.
-
Como resultado de ello, no sería conveniente que se ajuste a un modelo de regresión exponencial bivariado de los datos.
Question 92
Question
Tal como se presenta, ¿es un modelo de regresión lineal? Si no es así, ¿qué “truco” podría utilizar, si acaso, para convertirlo en un modelo de regresión lineal? ¿Cómo interpretaría el modelo resultante? ¿En qué circunstancias sería adecuado dicho modelo?
Considere el siguiente modelo:
Yi = eβ1+β2Xi
1 + eβ1+β2Xi
Answer
-
Tal como está, el modelo si es lineal en el parámetro.
-
Tal como está, el modelo tal vez es lineal en el parámetro.
-
Tal como está, el modelo no es lineal en el parámetro.
-
Tal como está, el modelo no es exponencial en el parámetro.
Question 93
Question
Una hipótesis nula es una suposición que se utiliza para negar o afirmar un suceso en relación a algún o algunos parámetros de una población o muestra.
De acuerdo con la hipótesis nula afirma que:
Answer
-
los residuos están normalmente no distribuidos.
-
los residuos están normalmente distribuidos.
-
los residuos están normalmente lineales.
-
los residuos están normalmente autoregresivos.
Question 94
Question
Un enfoque alterno pero complementario al de intervalos de confianza para probar hipótesis estadísticas es el método de la prueba de significancia.
En el lenguaje de las pruebas de significancia se dice que:
Answer
-
Un estadístico es estadísticamente significativo si el valor del estadístico de prueba no cae en la región crítica.
-
Un estadístico es estadísticamente significativo si el valor del estadístico de prueba pasa en la región crítica.
-
Un estadístico es estadísticamente significativo si el valor del estadístico de prueba se acerca en la región crítica.
-
Un estadístico es estadísticamente significativo si el valor del estadístico de prueba cae en la región crítica.
Question 95
Question
Un enfoque alterno pero complementario al de intervalos de confianza para probar hipótesis estadísticas es el método de la prueba de significancia.
¿Cuál es la idea básica de las pruebas de significancia?
Answer
-
Es la de un estadístico de prueba (una variable) y su distribución muestral según la hipótesis nula.
-
Es la de un estadístico de prueba (un autoregresor) y su distribución muestral según la hipótesis nula.
-
Es la de un estadístico de prueba (una determinante) y su distribución muestral según la hipótesis nula.
-
Es la de un estadístico de prueba (un estimador) y su distribución muestral según la hipótesis nula.
Question 96
Question
La econometría se define como la ciencia que aplica herramientas de teoría económica, matemáticas e inferencia estadística al análisis de fenómenos económicos
En estadística, cuando se rechaza la hipótesis nula, se dice que el hallazgo es:
Answer
-
estadísticamente insignificante
-
estadísticamente reciproco
-
estadísticamente determinante
-
estadísticamente significativo
Question 97
Question
la multicolinealidad, el interrogante natural es:
Determine cuál de las siguientes opciones se refiere a una de las advertencia de Kmenta:
Answer
-
La multicolinealidad es una cuestión de grado y no de clase La distinción importante no es entre presencia o ausencia de multicolinealidad, sino entre sus diferentes grados.
-
Como la multicolinealidad se refiere a la condición de las variables explicativas que son no estocásticas por supuestos, es una característica de la muestra y no de la población.
-
Como la multicolinealidad se refiere a la condición de las determinantes explicativas que son no estocásticas por supuestos, es una característica de la muestra y no de la población.
-
La multicolinealidad es la distinción importante no es entre presencia o ausencia de multicolinealidad, sino entre sus diferentes grados
Question 98
Question
Se dice que un modelo de regresión lineal presenta heterocedasticidad cuando la varianza de las perturbaciones no es constante a lo largo de las observaciones.
La heteroscedasticidad también surge por la presencia de:
Answer
-
datos atípicos o aberrantes
-
datos atípicos o significativos
-
datos atípicos o lineales
-
datos atípicos o regresión
Question 99
Question
El modelo de regresión lineal supone que no debe existir autocorrelación en los errores.
El término autocorrelación se define como:
Answer
-
la “correlación entre miembros de unidades de observaciones ordenadas en el tiempo
-
la “correlación entre miembros de series de observaciones ordenadas en las variables
-
la “negación entre miembros de series de observaciones ordenadas en el tiempo
-
la “correlación entre miembros de series de observaciones ordenadas en el tiempo
Question 100
Question
Dado dos valores cualesquiera de X, Xi y Xj (i= j), la correlación entre dos ui y uj cualesquiera (i no es igual a j) es cero. En pocas palabras estas observaciones se muestran de manera independiente.
A que supuesto hace referencia este enunciado
Answer
-
No hay auto correlación entre las perturbaciones
-
Si hay auto correlación entre las perturbaciones
-
Hay relación entre las perturbaciones
-
No hay relación entre las variables
Want to create your own Quizzes for free with GoConqr? Learn more.