1117700
Beschreibung
Mindmap von Kristi Brogden, aktualisiert more than 1 year ago
|
|
Erstellt von Kristi Brogden
vor mehr als 10 Jahre
|
|
Basal ganglia reinforcement
- Reinforcement learning
- Reinforcement = selection bias
- Thorndikes law of effect
- “Any act which in a given situation produces
satisfaction becomes associated with that
situation so that when the situation recurs the
act is more likely than before to recur also"
- “Any act which in a given situation produces
satisfaction becomes associated with that
situation so that when the situation recurs the
act is more likely than before to recur also"
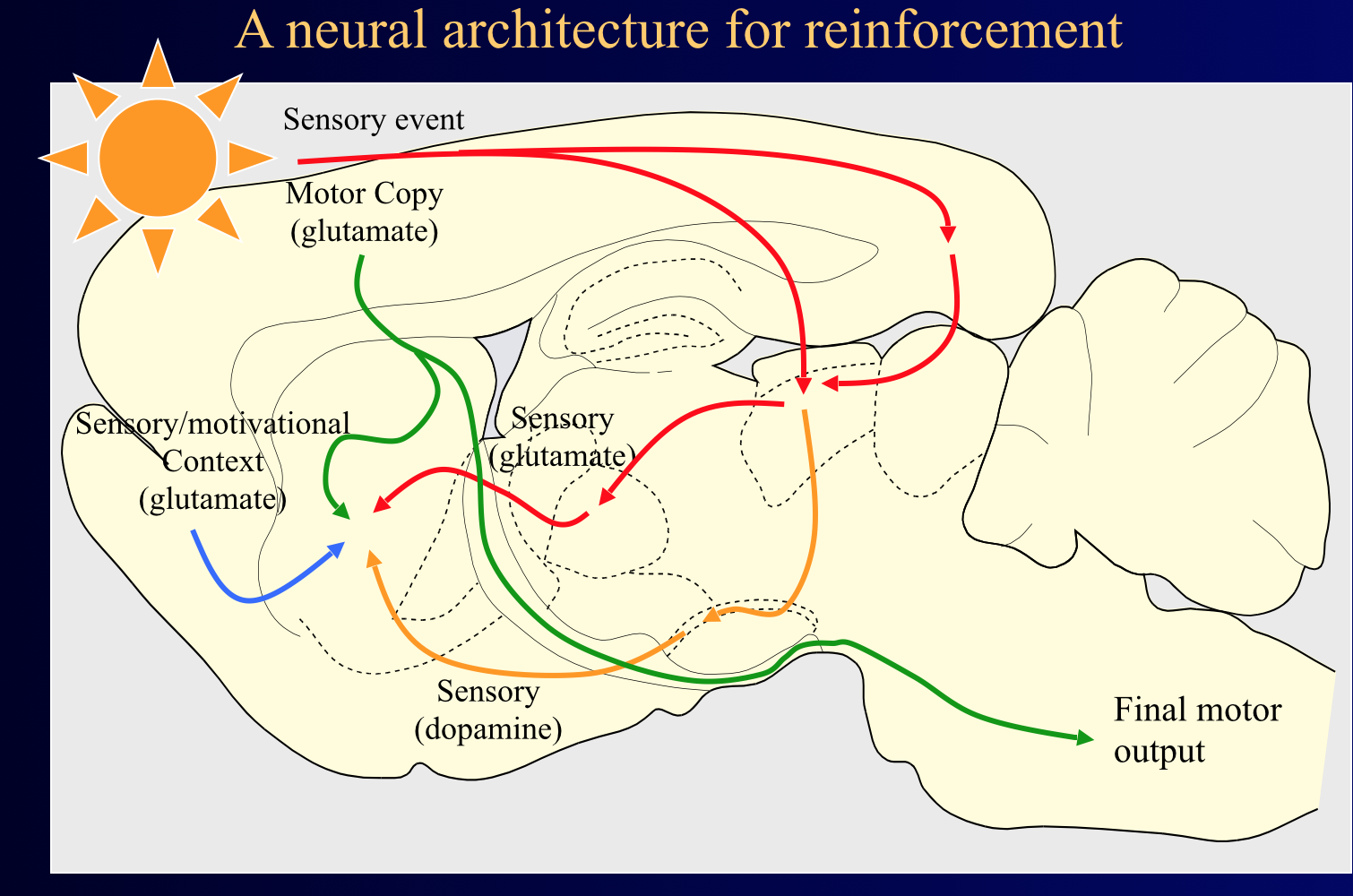
- In the basal ganglia
- Selective disinhibition in the
parallel looped architecture
component of basal ganglia =
selection mechanism
- Reinforcement learning are processes
which bias future selections
- Processes of reinforcement likely to
operate within a selection machine
- Phasic dopamine widely acknowledged
can provide a reinforcement signal
- Short latency (70-100ms)
- Short duration (~ 100ms) burst of impulses
- Elicited by biologically salient stimuli
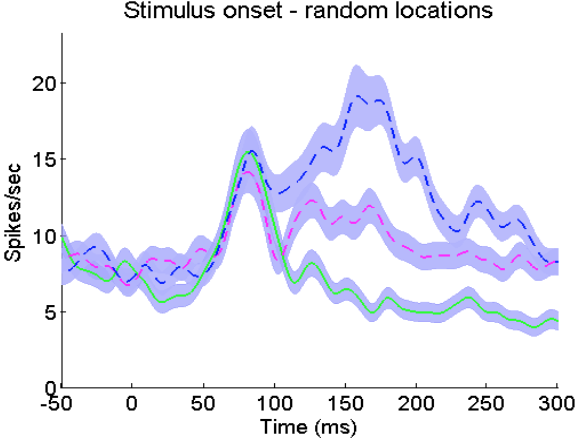
- Defining characteristics of phasic dopamine signals
- Fast and short
- Mono-phasic
- Bi-phasic
- Post-gaze shift
- Insight
- Sensory-evoked phasic
DA responses seem to
operate like a time-stamp
- What are the signals in DA target regions at the time
of the DA time-stamp ?
- …. these are the signals the timed dopamine input will be interacting with
- …. these are the signals the timed dopamine input will be interacting with
- What are the signals in DA target regions at the time
of the DA time-stamp ?
- Sensory-evoked phasic
DA responses seem to
operate like a time-stamp
- Fast and short
- Short latency (70-100ms)
- Selective disinhibition in the
parallel looped architecture
component of basal ganglia =
selection mechanism
- Reinforcement = selection bias
- Reward prediction errors
- Phasic DA signals similar to reward
prediction error term in the temporal
difference (TD) reinforcement learning
algorithm (Barto, Montague, Dayan)
- Reward prediction errors =
unexpected sensory events that are
‘better’ or ‘worse’ than predicted
- Reward prediction errors reinforce the
selection of actions that will maximise
the future acquisition of reward
- Phasic DA signals similar to reward
prediction error term in the temporal
difference (TD) reinforcement learning
algorithm (Barto, Montague, Dayan)
- Action discovery problem
- Actions are multi-dimensional
- Where must
the action
take place?
- When must
the action
take place?
- What exactly
must be done
to what?
- How fast
and with
what force?
- How are critical
parameters of different
dimensions discovered?
- Development of novel actions
- Trial and error repetition
- DA makes agent "want" to
repeat/reselect preceding
movements in preceding contexts
- DA makes agent "want" to
repeat/reselect preceding
movements in preceding contexts
- Variation/exploration
- not all contextual/behavioural components in each iteration
- not all contextual/behavioural components in each iteration
- Mechanism
- LTP in the prescence of phasic DA
- LTD in the abscence of phasic DA
- provides reinforcement required
for system to converge on
critical causative components
- LTP in the prescence of phasic DA
- How do we test if its true?
- A behavioural paradigm to investigate
different aspects of action discovery
- 1) Mechanisms of reinforcement
- 2) Convergence on critical
parameters of the critical
3WH dimensions
- 1) Mechanisms of reinforcement
- Ideal task requirements
- 1) Must be able to discriminate
learning of WHERE, WHEN,
WHAT and HOW dimensions
- 2) Difficulty should be
continuously variable
- 3) Repeated measures
- 4) Same task used to investigate
comparative competences of a
range of subjects – rodent,
monkey, man and robot
- 5) Should be simple, practical and
efficient – different versions to suit
experimental context
- 1) Must be able to discriminate
learning of WHERE, WHEN,
WHAT and HOW dimensions
- A behavioural paradigm to investigate
different aspects of action discovery
- SEE PPT FOR EXAMPLES - IMPORTANT
- Trial and error repetition
- Development of novel actions
- Where must
the action
take place?
- Actions are multi-dimensional
Medienanhänge
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Möchten Sie kostenlos Ihre eigenen Mindmaps mit GoConqr erstellen? Mehr erfahren.