14541802
Beschreibung
Mindmap von Jesus De La Torre, aktualisiert more than 1 year ago
|
|
Erstellt von Jesus De La Torre
vor mehr als 6 Jahre
|
|
ESTADISTICA INFERENCIAL
PARAMETRICA,NO PARAMETRICA
- 1 Introducción: Repaso de Estadística,
conceptos y definiciones.
- 1.1 ¿Para qué estudiamos esto?,
¿Cómo se come?, ¿Es un desperdicio
de mi tiempo el estudiar Estadística si
soy contador, administrador o
informático?
- Un primer impulso que todos los alumnos tienen es creer que, por el hecho de
estudiar para contadores, administradores o informáticos, la Estadística sirve
solo para rellenar la currícula que se ofrece en la universidad y que nunca la
utilizarán en su vida futura.
- Un primer impulso que todos los alumnos tienen es creer que, por el hecho de
estudiar para contadores, administradores o informáticos, la Estadística sirve
solo para rellenar la currícula que se ofrece en la universidad y que nunca la
utilizarán en su vida futura.
- 1.2 Repaso de conceptos y definiciones de
Estadística I
- La Estadística es una rama de la Matemática consistente en “El conjunto de técnicas de recolección,
presentación y correcto análisis de información numérica relacionada con facilitar la toma decisiones
frente a situaciones de riesgo (falta de certeza)”. Aquí usted podrá identificar un elemento y
circunstancia de la vida real: Los individuos, en lo cotidiano, estamos sujetos a tomar decisiones con
falta de certeza. Y aquí es donde hacemos un primer paréntesis.
- La Estadística es una rama de la Matemática consistente en “El conjunto de técnicas de recolección,
presentación y correcto análisis de información numérica relacionada con facilitar la toma decisiones
frente a situaciones de riesgo (falta de certeza)”. Aquí usted podrá identificar un elemento y
circunstancia de la vida real: Los individuos, en lo cotidiano, estamos sujetos a tomar decisiones con
falta de certeza. Y aquí es donde hacemos un primer paréntesis.
- 1.2.1 La probabilidad ¿Qué es y
cómo se cuantifica?
- Ya que se estableció el tipo de escenario en
donde usted tomará decisiones, es de
necesidad recordar un elemento de
importancia: La probabilidad. Esta se define
como “Una medida numérica que cuantifica
numéricamente la posibilidad de que un
resultado o evento se presente”.
- Ya que se estableció el tipo de escenario en
donde usted tomará decisiones, es de
necesidad recordar un elemento de
importancia: La probabilidad. Esta se define
como “Una medida numérica que cuantifica
numéricamente la posibilidad de que un
resultado o evento se presente”.
- 1.3 Medidas de tendencia central y medidas de dispersión. 1.3.1
La media, la mediana y la moda
- Por ejemplo, usted simplemente se dedica a medir el nivel llenado de todas las botellas de agua
producidas a lo largo de la vida de su fábrica y el conjunto de datos que logre de todas sus botellas se
llama población. Población: Conjunto de todas las observaciones posibles sobre una característica de
interés observada. La media o promedio ( ): Es la medida de tendencia central que se obtiene de sumar
los valores de todas las observaciones ( ) de la población y dividir dicha suma entre el número de
observaciones ( ). Fórmula 2: i x n La media (denotada por ) de la misma será: 1 4 2 3 4 4 5 6 3.625 8
La mediana: Es el valor de la observación que, una vez ordenada la población de la
menor observación a la mayor, que se encuentra exactamente a la mitad de la población. La condición
necesaria para que exista la mediana es que, al establecerse la misma, se cuente el mismo número de
observaciones arriba y debajo de la misma. Por ejemplo piense en la siguiente población
- Por ejemplo, usted simplemente se dedica a medir el nivel llenado de todas las botellas de agua
producidas a lo largo de la vida de su fábrica y el conjunto de datos que logre de todas sus botellas se
llama población. Población: Conjunto de todas las observaciones posibles sobre una característica de
interés observada. La media o promedio ( ): Es la medida de tendencia central que se obtiene de sumar
los valores de todas las observaciones ( ) de la población y dividir dicha suma entre el número de
observaciones ( ). Fórmula 2: i x n La media (denotada por ) de la misma será: 1 4 2 3 4 4 5 6 3.625 8
La mediana: Es el valor de la observación que, una vez ordenada la población de la
menor observación a la mayor, que se encuentra exactamente a la mitad de la población. La condición
necesaria para que exista la mediana es que, al establecerse la misma, se cuente el mismo número de
observaciones arriba y debajo de la misma. Por ejemplo piense en la siguiente población
- 1.3.2 La varianza y la desviación estándar ¿qué significan? y ¿Por qué la calculamos la varianza
elevando al cuadrado las diferencias respecto a la media?
- La varianza es, quizá, la medida de dispersión más empleada en la Estadística y en todo tipo de
aplicaciones. La misma simplemente se dedica a medir el tamaño promedio de separación que las
diferentes observaciones de la población tienen respecto a u media (). Varianza: La separación
promedio que tienen las observaciones de una población respecto a su media.
- La varianza es, quizá, la medida de dispersión más empleada en la Estadística y en todo tipo de
aplicaciones. La misma simplemente se dedica a medir el tamaño promedio de separación que las
diferentes observaciones de la población tienen respecto a u media (). Varianza: La separación
promedio que tienen las observaciones de una población respecto a su media.
- 1.3.3 Reglas de dedo
para calcular la
media y la
desviación
estándar:
- Ahora se le da la receta “de cocina” para calcular estas dos importantes medidas o estadísticas:
Media: 1. Tome todas las observaciones de su población (o muestra como se verá en breve) 2.
Sume los valores numéricos de las observaciones. 3. Cuente el número de observaciones que
tiene. 4. Divida la suma de valores numéricos de las observaciones entre el número de las
mismas. Desviación estándar: Varianza: 1. Recuerde que debe calcularse la varianza para
obtener este valor. Por tanto, debe calcularse primero la media. 2. A cada valor numérico de
cada observación se le resta el valor de la media (vea columna “diferencias respecto a la media”
en la tabla 2). Es decir, se calcula la diferencia entre cada valor numérico de cada observación
respecto a la media. -3 -2 -1 0 1 2 3 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 observaciones Media =
desviación estándar (raíz cuadrada de la varianza) que también representa el promedio de
diferencias respecto a la media pero, a diferncia de la varianza,
- Ahora se le da la receta “de cocina” para calcular estas dos importantes medidas o estadísticas:
Media: 1. Tome todas las observaciones de su población (o muestra como se verá en breve) 2.
Sume los valores numéricos de las observaciones. 3. Cuente el número de observaciones que
tiene. 4. Divida la suma de valores numéricos de las observaciones entre el número de las
mismas. Desviación estándar: Varianza: 1. Recuerde que debe calcularse la varianza para
obtener este valor. Por tanto, debe calcularse primero la media. 2. A cada valor numérico de
cada observación se le resta el valor de la media (vea columna “diferencias respecto a la media”
en la tabla 2). Es decir, se calcula la diferencia entre cada valor numérico de cada observación
respecto a la media. -3 -2 -1 0 1 2 3 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 observaciones Media =
desviación estándar (raíz cuadrada de la varianza) que también representa el promedio de
diferencias respecto a la media pero, a diferncia de la varianza,
- 1.4 Cálculo de probabilidades: los histogramas, las funciones y distribuciones de
probabilidad. 1.4.1 Mapa mental de lo hasta ahora visto
- 1.4.2 Eventos aleatorios (variables aleatorias) discretos y continuos
- Cuando la población de observaciones que se tiene es la de un experimento aleatorio sencillo como es el
lanzamiento de una o dos monedas, el lanzamiento de uno o dos dados, los resultados de un juego de
cartas o las calificaciones de un grupo de clase, es muy simple aplicar la fórmula 1: Probabilidad
Estadística Funciones y distribuciones de probabilidad Evento aleatorio Espacio muestral Experimento
aleatorio Observaciones Población Probabilidad: Media Varianza Desviación estándar: En poblaciones
chicas es fácil calcular pero, en poblaciones grandes o variables continua¿quése utilizapara calcular
Estadística II Notas del profesor para el alumno Página: 22 Derechos de autor: Dr. Oscar Valdemar De la
Torre Torres. (Registro en trámite) # . eventos aleatorios probabilidad p x Tamaño deesp muestral
Sin embargo, en poblaciones grandes o eventos continuos (ahorita conocerá el término), la forma de
hacer esto es diferente. Antes de hablar de ello, es necesario saber qué es un evento al
- Cuando la población de observaciones que se tiene es la de un experimento aleatorio sencillo como es el
lanzamiento de una o dos monedas, el lanzamiento de uno o dos dados, los resultados de un juego de
cartas o las calificaciones de un grupo de clase, es muy simple aplicar la fórmula 1: Probabilidad
Estadística Funciones y distribuciones de probabilidad Evento aleatorio Espacio muestral Experimento
aleatorio Observaciones Población Probabilidad: Media Varianza Desviación estándar: En poblaciones
chicas es fácil calcular pero, en poblaciones grandes o variables continua¿quése utilizapara calcular
Estadística II Notas del profesor para el alumno Página: 22 Derechos de autor: Dr. Oscar Valdemar De la
Torre Torres. (Registro en trámite) # . eventos aleatorios probabilidad p x Tamaño deesp muestral
Sin embargo, en poblaciones grandes o eventos continuos (ahorita conocerá el término), la forma de
hacer esto es diferente. Antes de hablar de ello, es necesario saber qué es un evento al
- 1.4.3 Cálculo de probabilidades en variables
aleatorias discretas: El histograma.
- Este ejercicio es sencillo pero ahora recordemos el ejemplo de los niveles de llenado de sus botellas de
agua ¿Se imagina la tabla que tendrá que calcular? Sería inmensa, al menos 1,000 celdas. Para
simplificar la tarea, los estadísticos idearon una técnica de organización llamada histograma de
frecuencias. Para dar una idea y recordar lo que es un histograma de frecuencias, piense usted las cajas
de verdura que pueden encontrarse en los mercados. En algunos comercios del mismo hay quienes
separan las cajas de aguacate en función del peso de los mismos.
- Este ejercicio es sencillo pero ahora recordemos el ejemplo de los niveles de llenado de sus botellas de
agua ¿Se imagina la tabla que tendrá que calcular? Sería inmensa, al menos 1,000 celdas. Para
simplificar la tarea, los estadísticos idearon una técnica de organización llamada histograma de
frecuencias. Para dar una idea y recordar lo que es un histograma de frecuencias, piense usted las cajas
de verdura que pueden encontrarse en los mercados. En algunos comercios del mismo hay quienes
separan las cajas de aguacate en función del peso de los mismos.
- 1.4.4 Distribuciones de
probabilidad.
- En la definición de histograma se acaba de identificar un término que será fundamental en la Estadística
inferencial: La distribución de frecuencias. Esta no es más que la forma en que se acomodan las
diferentes frecuencias de suceso de los eventos aleatorios dado un intervalo dado. Nótese en la gráfica 2
cómo las diferentes frecuencias se acomodan describiendo un fenómeno de interés para usted como
contador, administrador o informático: “El proveedor del comerciante solo produce aguacates de peso
alto ya que las mayores frecuencias se encuentran entre los 204 y los 407 gramos. Ya la mayor parte de
los aguacates se distribuye en estas cajas o intervalos.
- En la definición de histograma se acaba de identificar un término que será fundamental en la Estadística
inferencial: La distribución de frecuencias. Esta no es más que la forma en que se acomodan las
diferentes frecuencias de suceso de los eventos aleatorios dado un intervalo dado. Nótese en la gráfica 2
cómo las diferentes frecuencias se acomodan describiendo un fenómeno de interés para usted como
contador, administrador o informático: “El proveedor del comerciante solo produce aguacates de peso
alto ya que las mayores frecuencias se encuentran entre los 204 y los 407 gramos. Ya la mayor parte de
los aguacates se distribuye en estas cajas o intervalos.
- 1.4.5 Funciones de densidad de
probabilidad
- Hasta ahora se ha hablado de una distribución de probabilidad obtenida totalmente de los datos de la
población y vemos que se debe seguir la siguiente receta: 1. Obtener todos los datos u observaciones
de la población. 2. Organizarlos de menor a mayor. 3. Definir una cantidad de grupos o intervalos que
se acomode a su análisis (2,3,10,100, etc.) 4. La diferencia entre el valor máximo y el mínimo divídala
entre el número de intervalos que desee calcular y con eso logra el rango:
- Hasta ahora se ha hablado de una distribución de probabilidad obtenida totalmente de los datos de la
población y vemos que se debe seguir la siguiente receta: 1. Obtener todos los datos u observaciones
de la población. 2. Organizarlos de menor a mayor. 3. Definir una cantidad de grupos o intervalos que
se acomode a su análisis (2,3,10,100, etc.) 4. La diferencia entre el valor máximo y el mínimo divídala
entre el número de intervalos que desee calcular y con eso logra el rango:
- 1.4.5.1 Cálculo de probabilidades con función de densidad de probabilidad normal o
gaussiana.
- 1.4.6 La función de densidad de probabilidad normal estándar.
- En Estadística hay una acción llamada “estandarizar” que consiste en hacer comparables variables
aleatorias que, por naturaleza o escala de medida, son diferentes. Por tanto, lo que se hace es ajustar
los datos del inventario de aguacates en las diferentes escalas a valores que sean comparables al
aplicar el siguiente ajuste o estandarización
- En Estadística hay una acción llamada “estandarizar” que consiste en hacer comparables variables
aleatorias que, por naturaleza o escala de medida, son diferentes. Por tanto, lo que se hace es ajustar
los datos del inventario de aguacates en las diferentes escalas a valores que sean comparables al
aplicar el siguiente ajuste o estandarización
- 1.4.6.1 Regla de dedo para comprender por qué utilizar una distribución normal estándar:
- 1. Cuando se desean comparar dos poblaciones cuyas unidades de medida no sean las mismas o, peor
aún, cuando no se tienen desviaciones estándar comparables, se debe utilizar ya no una función de
densidad de probabilidad normal común y corriente; sino una estandarizada. 2. Para poder utilizar una
distribución normal estándar, es necesario ya no utilizar los valores originales de nuestro inventario
sino más bien hacer una operación que se conoce como “Estandarizar los valores de la variable
- 1. Cuando se desean comparar dos poblaciones cuyas unidades de medida no sean las mismas o, peor
aún, cuando no se tienen desviaciones estándar comparables, se debe utilizar ya no una función de
densidad de probabilidad normal común y corriente; sino una estandarizada. 2. Para poder utilizar una
distribución normal estándar, es necesario ya no utilizar los valores originales de nuestro inventario
sino más bien hacer una operación que se conoce como “Estandarizar los valores de la variable
- 1.4.7 El cálculo de la probabilidad utilizando la normal estándar y las tablas
correspondientes.
- Ahora usted ha visto la principal función de densidad de probabilidad que se utiliza en la Estadística para
ciencias administrativas: La distribución normal estándar. Ya que usted estandarice los valores de sus
variables aleatorias, estará usted en capacidad de saber cómo se calculan probabilidades de eventos
cuando se tienen solamente los datos de las observaciones de la población con que se trabaja al utilizar la
distribución de probabilidad normal estándar.
- 1.4.7.1 Diferentes formas de calcular una probabilidad. Los valores de probabilidad
acumulada.
- En base a lo revisado, se puede apreciar que el valor de la probabilidad es muy puntual si solo se desea
saber cuánto vale la probabilidad de un valor determinado como puede ser un nivel de llenado
específico de 970 ml. Sin embargo, en la vida cotidiana, las probabilidades se determinan en base a
intervalos de datos. Esto implica que lo que en realidad nos está dando la tabla es la probabilidad de
que la siguiente botella de agua tenga un nivel de llenado de 910 ml (valor medio) a 970 ml. Esto es así
ya que la fórmula de cálculo de la función de densidad de probabilidad así lo pide.
- En base a lo revisado, se puede apreciar que el valor de la probabilidad es muy puntual si solo se desea
saber cuánto vale la probabilidad de un valor determinado como puede ser un nivel de llenado
específico de 970 ml. Sin embargo, en la vida cotidiana, las probabilidades se determinan en base a
intervalos de datos. Esto implica que lo que en realidad nos está dando la tabla es la probabilidad de
que la siguiente botella de agua tenga un nivel de llenado de 910 ml (valor medio) a 970 ml. Esto es así
ya que la fórmula de cálculo de la función de densidad de probabilidad así lo pide.
- Ahora usted ha visto la principal función de densidad de probabilidad que se utiliza en la Estadística para
ciencias administrativas: La distribución normal estándar. Ya que usted estandarice los valores de sus
variables aleatorias, estará usted en capacidad de saber cómo se calculan probabilidades de eventos
cuando se tienen solamente los datos de las observaciones de la población con que se trabaja al utilizar la
distribución de probabilidad normal estándar.
- 1.4.5.1 Cálculo de probabilidades con función de densidad de probabilidad normal o gaussiana
- 1.4.7 El cálculo de la probabilidad utilizando la normal estándar y las tablas
correspondientes
- En base a lo previamente descrito, en la vida cotidiana se pueden tener los siguientes casos de cuantificación de
probabilidades (sigamos con el ejemplo del nivel de llenado de botellas): 1. La probabilidad de que el valor del
evento aleatorio sea menor o igual a b (por ejemplo que sea mayor o igual a 970 ml). 2. La probabilidad de que el
valor del evento aleatorio sea mayor o igual a b por ejemplo que sea menor o igual a 970 ml). 3. La probabilidad
de que el valor del evento se encuentre entre a y b (por ejemplo que el valor futuro se encuentre entre el valor
medio de 910 ml y 970 ml).
- En base a lo previamente descrito, en la vida cotidiana se pueden tener los siguientes casos de cuantificación de
probabilidades (sigamos con el ejemplo del nivel de llenado de botellas): 1. La probabilidad de que el valor del
evento aleatorio sea menor o igual a b (por ejemplo que sea mayor o igual a 970 ml). 2. La probabilidad de que el
valor del evento aleatorio sea mayor o igual a b por ejemplo que sea menor o igual a 970 ml). 3. La probabilidad
de que el valor del evento se encuentre entre a y b (por ejemplo que el valor futuro se encuentre entre el valor
medio de 910 ml y 970 ml).
- 1.1 ¿Para qué estudiamos esto?,
¿Cómo se come?, ¿Es un desperdicio
de mi tiempo el estudiar Estadística si
soy contador, administrador o
informático?
- 2 Teoría del muestreo
- 2.1 Tipos de muestreo
- En este tema simplemente se explorarán las características relacionadas a la forma de hacer muestras. En el
siguiente tema: la inferencia, se observará que el cálculo de parámetros como la media y la desviación estándar
cambian en una muestra respecto a una población. Una parte de importancia a observar es que una muestra,
según el tipo de estudio que se haga, se realiza de diferentes formas. Por ejemplo, la muestra de un grupo de
aguacates en inventario o la que se obtiene con las botellas de agua extraídas de una línea de producción se
forma de manera diferente a la que emplea una empresa de mercadotecnia para probar la demanda de un
producto. Esta diferencia radica en el uso que se dará a los datos. Por ejemplo, el tener que saber cuántas
botellas de agua no satisfacen los estándares de calidad es una aplicación diferente a saber ¿cuál es la demanda
de bebidas alcohólicas en el sector de clase media de una sociedad tanto en mujeres como en hombres? En
virtud de esto, se tienen cuatr
- En este tema simplemente se explorarán las características relacionadas a la forma de hacer muestras. En el
siguiente tema: la inferencia, se observará que el cálculo de parámetros como la media y la desviación estándar
cambian en una muestra respecto a una población. Una parte de importancia a observar es que una muestra,
según el tipo de estudio que se haga, se realiza de diferentes formas. Por ejemplo, la muestra de un grupo de
aguacates en inventario o la que se obtiene con las botellas de agua extraídas de una línea de producción se
forma de manera diferente a la que emplea una empresa de mercadotecnia para probar la demanda de un
producto. Esta diferencia radica en el uso que se dará a los datos. Por ejemplo, el tener que saber cuántas
botellas de agua no satisfacen los estándares de calidad es una aplicación diferente a saber ¿cuál es la demanda
de bebidas alcohólicas en el sector de clase media de una sociedad tanto en mujeres como en hombres? En
virtud de esto, se tienen cuatr
- 2.2 Muestreo aleatorio simple
- Como su nombre lo indica, consiste en seleccionar, de manera aleatoria, una
serie de observaciones, objetos o datos de una población sin seguir algún
tipo de agrupamiento específico. Un ejemplo simple, retomando el caso de
los niveles de llenado de las botellas, sería ir una directamente de la línea de
producción, luego dos y luego una y así sucesivamente hasta llegar a un
número determinado de botellas u observaciones.
- Como su nombre lo indica, consiste en seleccionar, de manera aleatoria, una
serie de observaciones, objetos o datos de una población sin seguir algún
tipo de agrupamiento específico. Un ejemplo simple, retomando el caso de
los niveles de llenado de las botellas, sería ir una directamente de la línea de
producción, luego dos y luego una y así sucesivamente hasta llegar a un
número determinado de botellas u observaciones.
- 2.3 Muestreo sistemático
- Este tipo de muestreo consiste en elegir a un objeto en función de intervalos predeterminados. Por ejemplo,
piense usted que tiene 2,000 cajas de aguacate foliadas todas y listas para empacarse a Estados Unidos. Ahora
elige primero la caja número 20, luego la 40 y así sucesivamente hasta la 2,000. Esto le deja con una muestra de
100 cajas a las que le puede realizar el estudio estadístico que necesita.
- Este tipo de muestreo consiste en elegir a un objeto en función de intervalos predeterminados. Por ejemplo,
piense usted que tiene 2,000 cajas de aguacate foliadas todas y listas para empacarse a Estados Unidos. Ahora
elige primero la caja número 20, luego la 40 y así sucesivamente hasta la 2,000. Esto le deja con una muestra de
100 cajas a las que le puede realizar el estudio estadístico que necesita.
- 2.4 Muestreo estratificado.
- En este tipo de muestreo, se divide la población de datos en grupos homogéneos (mujeres y hombres, intervalo
de pesos, etc.) y se determina qué proporción representa cada estrato o grupo. Cuando se analizan las
características y parámetros como media, desviación estándar, etc., se ponderan los mismos en función de su
representación o proporción de peso respecto la población total y con esa ponderación se obtienen los
parámetros y probabilidades totales de dicha población con este tipo de muestra
- En este tipo de muestreo, se divide la población de datos en grupos homogéneos (mujeres y hombres, intervalo
de pesos, etc.) y se determina qué proporción representa cada estrato o grupo. Cuando se analizan las
características y parámetros como media, desviación estándar, etc., se ponderan los mismos en función de su
representación o proporción de peso respecto la población total y con esa ponderación se obtienen los
parámetros y probabilidades totales de dicha población con este tipo de muestra
- 2.5 Muestreo de racimo
- Esta forma de muestrear se parece a la anterior, con la diferencia de que primero se hacen estratos y luego se
seleccionan miembros, datos u observaciones de cada uno de los estratos de una manera aleatoria. Por
ejemplo, usted desea saber cuántas televisiones existen en la ciudad de Morelia. Entonces, usted divide la
ciudad en colonias y elige, de cada colonia y de manera aleatoria, una serie de casas, toca la puerta y pregunta
el número de televisiones que hay en cada una. Con esto toma muestras aleatorias no de la totalidad de la
población sino de cada uno de los grupos que usted formó.
- Esta forma de muestrear se parece a la anterior, con la diferencia de que primero se hacen estratos y luego se
seleccionan miembros, datos u observaciones de cada uno de los estratos de una manera aleatoria. Por
ejemplo, usted desea saber cuántas televisiones existen en la ciudad de Morelia. Entonces, usted divide la
ciudad en colonias y elige, de cada colonia y de manera aleatoria, una serie de casas, toca la puerta y pregunta
el número de televisiones que hay en cada una. Con esto toma muestras aleatorias no de la totalidad de la
población sino de cada uno de los grupos que usted formó.
- 2.6 Diferencias operativas en cada uno de los tipos de muestreo y determinación del empleado en Estadística
Inferencial.
- 2.7 Diseño de un experimento: el proceso que se sigue
para tomar decisionesl.
- En Estadística aplicada a los negocios, es importante conducir de manera apropiada la toma de decisiones. Si
usted a esta altura ya llevó una clase de Métodos de investigación o metodología de la investigación,
recordará el método científico. Aunque éste último es más apropiado para la generación de conocimiento
científico, la forma en cómo se llega a una conclusión y a la toma de decisiones en los negocios es muy
similar.
- En Estadística aplicada a los negocios, es importante conducir de manera apropiada la toma de decisiones. Si
usted a esta altura ya llevó una clase de Métodos de investigación o metodología de la investigación,
recordará el método científico. Aunque éste último es más apropiado para la generación de conocimiento
científico, la forma en cómo se llega a una conclusión y a la toma de decisiones en los negocios es muy
similar.
- 2.8 Distribuciones de probabilidad muestrales
- Hasta ahora, se ha trabajado con el supuesto de que los datos que se han estudiado pertenecen a una
población. Es decir, se ha supuesto que los datos con que se trabaja es la totalidad que se pueden tener. Sin
embargo, al introducirnos en este nuevo tema de Teoría del muestreo, hemos visto que, en la mayoría de las
ocasiones, es difícil obtener y manipular todos los datos de una población. Por ejemplo, a los comerciantes les
era costoso y tedioso hacer un análisis estadístico de la totalidad de su inventario de aguacates con miles de
piezas. Más bien, lo que hicieron es tomar unos cuantos (una muestra) para hacer inferencias sobre las
propiedades del resto de la población.
- Hasta ahora, se ha trabajado con el supuesto de que los datos que se han estudiado pertenecen a una
población. Es decir, se ha supuesto que los datos con que se trabaja es la totalidad que se pueden tener. Sin
embargo, al introducirnos en este nuevo tema de Teoría del muestreo, hemos visto que, en la mayoría de las
ocasiones, es difícil obtener y manipular todos los datos de una población. Por ejemplo, a los comerciantes les
era costoso y tedioso hacer un análisis estadístico de la totalidad de su inventario de aguacates con miles de
piezas. Más bien, lo que hicieron es tomar unos cuantos (una muestra) para hacer inferencias sobre las
propiedades del resto de la población.
- 2.8.1 Las estadísticas necesarias para calcular la
distribución normal muestral
- Hasta ahora se ha revisado cómo se genera una función de probabilidad normal estándar y se ha hecho
énfasis en observar que esta se revisó suponiendo que los datos con que se trabaja son poblaciones. Sin
embargo, usted tendrá en su poder para trabajar, y salvo que el problema que usted resuelva sea
diferente, muestras. Se ha visto también que, para calcular probabilidades a través de una función de
densidad, usted debe tener la media y la desviación estándar que son una medida de tendencia central
y de dispersión respectivamente. Cuando usted trabaja con poblaciones, las medidas que son insumos
necesarios para el cálculo de probabilidades se llaman Parámetros. Es decir, si los datos que usted tiene
para analizar son la media y la desviación estándar. A estos dos se les denomina parámetros de su
función de probabilidad. Sin embargo, para una función de probabilidad cuando usted tiene muestras,
los insumos son los mismos y se llaman ahora estadísticas o medidas estadísticas. Y estas esta
- Hasta ahora se ha revisado cómo se genera una función de probabilidad normal estándar y se ha hecho
énfasis en observar que esta se revisó suponiendo que los datos con que se trabaja son poblaciones. Sin
embargo, usted tendrá en su poder para trabajar, y salvo que el problema que usted resuelva sea
diferente, muestras. Se ha visto también que, para calcular probabilidades a través de una función de
densidad, usted debe tener la media y la desviación estándar que son una medida de tendencia central
y de dispersión respectivamente. Cuando usted trabaja con poblaciones, las medidas que son insumos
necesarios para el cálculo de probabilidades se llaman Parámetros. Es decir, si los datos que usted tiene
para analizar son la media y la desviación estándar. A estos dos se les denomina parámetros de su
función de probabilidad. Sin embargo, para una función de probabilidad cuando usted tiene muestras,
los insumos son los mismos y se llaman ahora estadísticas o medidas estadísticas. Y estas esta
- 2.8.2 Media muestral
- Como puede apreciar, la función de probabilidad normal estándar sigue utilizándose. Lo único que
cambian son la forma de calcular la media y la desviación estándar. Para el caso de la media muestral,
que ahora se denota como x , simplemente se calcula igual para todos los datos repitiendo la fórmula
- Como puede apreciar, la función de probabilidad normal estándar sigue utilizándose. Lo único que
cambian son la forma de calcular la media y la desviación estándar. Para el caso de la media muestral,
que ahora se denota como x , simplemente se calcula igual para todos los datos repitiendo la fórmula
- 2.8.3 Error estándar
- En el sub tema anterior se dijo que el tamaño de la muestra
no influía en el cálculo de la media muestral y que sería la
misma media para población que para muestra. Sin embargo,
en el caso de la desviación estándar aplicable a una muestra,
mejor conocida como error estándar, la cosa cambia. Para
ilustrar la idea, observe primero la gráfica 21 en donde se
generan 30 muestras diferentes con diferentes tamaños. Es
decir, una muestra de 30 aguacates, otra de 55 y así
sucesivamente
- En el sub tema anterior se dijo que el tamaño de la muestra
no influía en el cálculo de la media muestral y que sería la
misma media para población que para muestra. Sin embargo,
en el caso de la desviación estándar aplicable a una muestra,
mejor conocida como error estándar, la cosa cambia. Para
ilustrar la idea, observe primero la gráfica 21 en donde se
generan 30 muestras diferentes con diferentes tamaños. Es
decir, una muestra de 30 aguacates, otra de 55 y así
sucesivamente
- 2.8.4 Cálculo de probabilidades con muestras.
- Para calcular la probabilidad en una muestra se sigue utilizando la misma tabla de distribución normal
estándar y se siguen los mismos métodos de cálculo previamente vistos. Lo único que cambia es la fórmula 6
a la que se le sustituye la desviación estándar por el error estándar. Esto es:
- Para calcular la probabilidad en una muestra se sigue utilizando la misma tabla de distribución normal
estándar y se siguen los mismos métodos de cálculo previamente vistos. Lo único que cambia es la fórmula 6
a la que se le sustituye la desviación estándar por el error estándar. Esto es:
- 2.9 El teorema del límite central y una primera forma de determinar el tamaño adecuado de la
muestra
- Hasta ahora se ha trabajado con el supuesto de que las variables aleatorias que se estudian están
normalmente distribuidas. Sin embargo puede darse el caso de que esto no sea así. Cuando usted, con
técnicas de las que se revisarán algunas en temas posteriores, detecta que los datos con que trabaja no
están normalmente distribuidos, puede seguir manejando el supuesto de normalidad si incrementa el
número de datos de su muestra.
- Hasta ahora se ha trabajado con el supuesto de que las variables aleatorias que se estudian están
normalmente distribuidas. Sin embargo puede darse el caso de que esto no sea así. Cuando usted, con
técnicas de las que se revisarán algunas en temas posteriores, detecta que los datos con que trabaja no
están normalmente distribuidos, puede seguir manejando el supuesto de normalidad si incrementa el
número de datos de su muestra.
- 2.10El multiplicador de población finita
- Este cálculo es el que casi siempre se utilizará. Esto es así porque muchos fenómenos que estudiamos
en las Ciencias Administrativas tienen poblaciones cuyos tamaños desconocemos. Es decir, son
poblaciones infinitas. Ejemplos de esto son el nivel de llenado de las botellas de agua que produce, la
temperatura de Morelia, los precios de una acción, el inventario que tuvo, tiene y tendrá de aguacates,
etc. Sin embargo, habrá casos en los que usted conozca muy bien el tamaño de su población y tenga
que verse en la necesidad de hacer un muestreo dado lo costoso que le resulta sacar datos del total de
su población. Un ejemplo puede ser un estudio de mercado como el que hizo Steve Jobs. Por ejemplo, él
sabía cuántos arquitectos había en Estados Unidos. Por tanto, tuvo que hacer un ajuste adicional al
error estándar para poder calcularlo bien y determinar la distribución de probabilidad:
- Este cálculo es el que casi siempre se utilizará. Esto es así porque muchos fenómenos que estudiamos
en las Ciencias Administrativas tienen poblaciones cuyos tamaños desconocemos. Es decir, son
poblaciones infinitas. Ejemplos de esto son el nivel de llenado de las botellas de agua que produce, la
temperatura de Morelia, los precios de una acción, el inventario que tuvo, tiene y tendrá de aguacates,
etc. Sin embargo, habrá casos en los que usted conozca muy bien el tamaño de su población y tenga
que verse en la necesidad de hacer un muestreo dado lo costoso que le resulta sacar datos del total de
su población. Un ejemplo puede ser un estudio de mercado como el que hizo Steve Jobs. Por ejemplo, él
sabía cuántos arquitectos había en Estados Unidos. Por tanto, tuvo que hacer un ajuste adicional al
error estándar para poder calcularlo bien y determinar la distribución de probabilidad:
- 2.1 Tipos de muestreo
- 3 Estimaciones puntuales y de intervalo. La base de la inferencia
estadística.
- 3.1 Consideraciones para calcular verdaderas estimaciones de
intervalo
- En la gráfica 24 se expusieron 30 muestras diferentes las cuales tienen diferentes medias muestrales x y
diferentes intervalos dados por lim.sup x erior x y lim.inf x erior x . Si se recuerda que la media
muestral x puede fluctuar respecto a la poblacional , se aprecia en la siguiente gráfica en la que se
exponen las 30 muestras aleatorias en comparación a la media poblacional.
- En la gráfica 24 se expusieron 30 muestras diferentes las cuales tienen diferentes medias muestrales x y
diferentes intervalos dados por lim.sup x erior x y lim.inf x erior x . Si se recuerda que la media
muestral x puede fluctuar respecto a la poblacional , se aprecia en la siguiente gráfica en la que se
exponen las 30 muestras aleatorias en comparación a la media poblacional.
- 3.1.1 El verdadero cálculo del error muestral cuando
se desconoce la desviación estándar de la población
- Sin embargo, algo que se mencionó al inicio de este tema es que se está suponiendo que se conoce la
desviación estándar de la población y en realidad lo que se está calculando la de una muestra. En el caso
de muestras, lo que debe de hacerse es hacer un pequeño ajuste para calcular la desviación estándar
muestral que ahora se denota como s
- Sin embargo, algo que se mencionó al inicio de este tema es que se está suponiendo que se conoce la
desviación estándar de la población y en realidad lo que se está calculando la de una muestra. En el caso
de muestras, lo que debe de hacerse es hacer un pequeño ajuste para calcular la desviación estándar
muestral que ahora se denota como s
- 3.1.2 La estimación de
intervalo
- Ya que tiene usted la estimación puntual ( x ) del precio de la acción, que reconoce que este valor
puede cambiar de muestra en muestra y que tiene el cálculo del error estándar de la muestra
calculado con la fórmula 11, procederá usted a hacer una afirmación de este tipo: “El precio de la
acción se estima que sea de $26.4666 y, con un 95% de confianza, se espera que ese valor oscile
entre $26.6533 y $28.2802.” Si usted observa la gráfica 26, quizá no le sea muy preciso el pronóstico
en el sentido de que el precio esperado y su intervalo están muy abajo. Con el análisis de regresión
podremos mejorar la precisión. Baste con suponer, de momento, que la media muestral es buen
pronóstico del valor futuro.
- Ya que tiene usted la estimación puntual ( x ) del precio de la acción, que reconoce que este valor
puede cambiar de muestra en muestra y que tiene el cálculo del error estándar de la muestra
calculado con la fórmula 11, procederá usted a hacer una afirmación de este tipo: “El precio de la
acción se estima que sea de $26.4666 y, con un 95% de confianza, se espera que ese valor oscile
entre $26.6533 y $28.2802.” Si usted observa la gráfica 26, quizá no le sea muy preciso el pronóstico
en el sentido de que el precio esperado y su intervalo están muy abajo. Con el análisis de regresión
podremos mejorar la precisión. Baste con suponer, de momento, que la media muestral es buen
pronóstico del valor futuro.
- 3.2 ¿Qué pasa cuando nuestra muestra de datos no es
grande? La distribución t-Student
- Hasta ahora se ha trabajado con el supuesto de que los datos (sean de población o de muestra) están
normalmente distribuidos ya sea porque así nos conviene o porque hemos trabajado con muestras con
más de 30 datos, situación que satisface el Teorema del Límite Central previamente revisado. Sin
embargo, no siempre se tiene la posibilidad de tener muestras de 30 datos sino más pequeñas. Un
ejemplo muy claro puede estar en la contabilidad de una empresa. Suponga que usted desea hacer un
análisis estadístico y calcular la distribución de probabilidad del ROI11 y que solo tiene 12 trimestres
de información. Claramente la distribución normal estándar no es de utilidad porque viola el Teorema
del límite central. ¿Qué se hace entonces? ¿Qué función de probabilidad se puede utilizar? Muy
simple: Hay un tipo de función de probabilidad, de los cuatro que revisaremos en el curso, que sirve
para este fin. Esta se llama distribución t-Student o simplemente distribución t. Esta distribución fue
propu
- Hasta ahora se ha trabajado con el supuesto de que los datos (sean de población o de muestra) están
normalmente distribuidos ya sea porque así nos conviene o porque hemos trabajado con muestras con
más de 30 datos, situación que satisface el Teorema del Límite Central previamente revisado. Sin
embargo, no siempre se tiene la posibilidad de tener muestras de 30 datos sino más pequeñas. Un
ejemplo muy claro puede estar en la contabilidad de una empresa. Suponga que usted desea hacer un
análisis estadístico y calcular la distribución de probabilidad del ROI11 y que solo tiene 12 trimestres
de información. Claramente la distribución normal estándar no es de utilidad porque viola el Teorema
del límite central. ¿Qué se hace entonces? ¿Qué función de probabilidad se puede utilizar? Muy
simple: Hay un tipo de función de probabilidad, de los cuatro que revisaremos en el curso, que sirve
para este fin. Esta se llama distribución t-Student o simplemente distribución t. Esta distribución fue
propu
- 3.2.1 Los parámetros para calcular la distribución t-Student y su empleo para el cálculo de
estimaciones de intervalo.
- visto previamente que la distribución normal, a parte del valor de la variable aleatoria i x , necesita
solo dos simples parámetros o estadísticas12 que son la media y la desviación estándar. Para el caso
de la distribución t-Student se siguen utilizando estos dos más uno llamado Grados de libertad
(denotado como GL o ). Este último (los grados de libertad) será el número de mayor importancia
para calcular probabilidades.
- visto previamente que la distribución normal, a parte del valor de la variable aleatoria i x , necesita
solo dos simples parámetros o estadísticas12 que son la media y la desviación estándar. Para el caso
de la distribución t-Student se siguen utilizando estos dos más uno llamado Grados de libertad
(denotado como GL o ). Este último (los grados de libertad) será el número de mayor importancia
para calcular probabilidades.
- 3.3 Estimaciones de intervalo para comparar medias
- 3.3.1 estimaciones de intervalo para muestras apareadas grandes y
peqeñas
- 3.3.1.1 Estimación de intervalo para muestras apareadas
grandes
- Recuerde usted que, por el Teorema del Límite central, se puede considera una muestra como “grande” si
tiene más de 30 observaciones e incluso se puede suponer que está distribuida si el tamaño de dicha
muestra es menor al 5% del tamaño de la población total, si es que se sabe. Si usted ve detenidamente, se
tienen 4 grupos de 20 individuos que dan un total de 80 diferencias o diferencias de calificaciones entr
aceptar el supuesto de que es muestra grande y de que está normalmente distribuida. con lo hasta ora
revisado usted p esta técnica de estimación o inferencia Recordemos al Sr. Steve Jobs con quien iniciamos
estas notas del profesor ¿Qué hizo el Sr. Jobs para determinar que su computadora es mejor que la otra? Al
principio de las notas, se menciono que probablemente el Sr. Jobs primero hizo un muestreo de racimo.
Recordando la nota legal, se mencionó que esta es una mera suposición y resulta ser lo que muchos
analistas de mercado o mercadólogos harían por su empresa para saber la
- que probablemente el Sr. Jobs primero hizo un muestreo de racimo. Recordando la nota legal, se mencionó
que esta es una mera suposición y resulta ser lo que muchos analistas de mercado o mercadólogos harían
por su empresa para saber la superioridad de su producto respecto al de la competencia. Recordando los
comentarios iniciales del muestreo de racimo, se observó que este consiste en separar una población en
diferentes grupos de interés y luego tomar una muestra de cada segmento, estrato o grupo de interés para
tomar una muestra aleatoria de cada uno. ¿Qué pudo hacer el Sr. Jobs? De entrada separó su población
objetivo (usuarios de computadoras) en cuatro grupos o estratos de interés: 1. Arquitectos ingenieros,
matemáticos, físicos, investigadores y profesionistas que ocupen procesamiento de cálculo. 2. Diseñadores
gráficos, artistas de medios, músicos y gente que ocupe procesamiento gráfico. 3. Amas de casa,
estudiantes y gente mayor. 4. Contadores, abogados, economistas, financieros
- Recuerde usted que, por el Teorema del Límite central, se puede considera una muestra como “grande” si
tiene más de 30 observaciones e incluso se puede suponer que está distribuida si el tamaño de dicha
muestra es menor al 5% del tamaño de la población total, si es que se sabe. Si usted ve detenidamente, se
tienen 4 grupos de 20 individuos que dan un total de 80 diferencias o diferencias de calificaciones entr
aceptar el supuesto de que es muestra grande y de que está normalmente distribuida. con lo hasta ora
revisado usted p esta técnica de estimación o inferencia Recordemos al Sr. Steve Jobs con quien iniciamos
estas notas del profesor ¿Qué hizo el Sr. Jobs para determinar que su computadora es mejor que la otra? Al
principio de las notas, se menciono que probablemente el Sr. Jobs primero hizo un muestreo de racimo.
Recordando la nota legal, se mencionó que esta es una mera suposición y resulta ser lo que muchos
analistas de mercado o mercadólogos harían por su empresa para saber la
- 3.3.1.1 Estimación de intervalo para muestras apareadas
grandes
- 3.3.1 estimaciones de intervalo para muestras apareadas grandes y
peqeñas
- 3.3.1.2 Estimación de intervalo para muestras apareadas
pequeñas
- Como se vio previamente para trabajar con estimaciones de muestra pequeñas, las fórmulas de
cálculo del límite superior e inferior de la estimación de intervalo siguen siendo los mismos. Lo único
que cambiaba en la fórmula es el valor i Z por el valor i t en la fórmula 18: Fórmula 19 Cálculo de las
estimaciones de intervalo para diferencias entre muestras pequeñas (n<30): int. superior ( ) i D D t
Estimación puntual=D int. inferior ( ) D t i x Para simplificar el ejemplo del Sr. Jobs,
supongamos que los datos de la tabla 12, no son muestra grande sino pequeña y, para esto suponga
que los valores de D y D de dicha tabla son de una muestra de solo 26 observaciones. Por tanto, si
el número de observaciones es de 26, los grados de libertad son 25. Por tanto, al buscar en la tabla
t para un nivel de significancia de 5% (el inverso de un nivel de confianza de 95%) con 25 grados de
libertad, se llega a un valor 2.0595 i t . Esto es:
- Como se vio previamente para trabajar con estimaciones de muestra pequeñas, las fórmulas de
cálculo del límite superior e inferior de la estimación de intervalo siguen siendo los mismos. Lo único
que cambiaba en la fórmula es el valor i Z por el valor i t en la fórmula 18: Fórmula 19 Cálculo de las
estimaciones de intervalo para diferencias entre muestras pequeñas (n<30): int. superior ( ) i D D t
Estimación puntual=D int. inferior ( ) D t i x Para simplificar el ejemplo del Sr. Jobs,
supongamos que los datos de la tabla 12, no son muestra grande sino pequeña y, para esto suponga
que los valores de D y D de dicha tabla son de una muestra de solo 26 observaciones. Por tanto, si
el número de observaciones es de 26, los grados de libertad son 25. Por tanto, al buscar en la tabla
t para un nivel de significancia de 5% (el inverso de un nivel de confianza de 95%) con 25 grados de
libertad, se llega a un valor 2.0595 i t . Esto es:
- 3.4 ¿Cómo determinar el intervalo de confianza?
- Existen muchas técnicas que nos ayudan a calibrar estadísticamente el nivel de confianza que se imprimirá a las estimaciones de intervalo. Sin embargo, estas salen de la óptica
y grado de Derechos de autor: Dr. Oscar Valdemar De la Torre Torres. (Registro en trámite) exigencia del curso ya que en el mismo se le enseñará a dominar las principales
técnicas estadísticas de utilidad para su vida profesional. Si usted desea profundizar en esto, puede cursar una maestría en administración o una en finanzas que logre ese
grado de profundización o puede consultar fuentes más avanzadas en Econometría o análisis de datos multivariante. Para usted, sea suficiente saber que un nivel de confianza
de 90% o mayor es más que suficiente y que no debe de bajar de dicho valor para poder generar buenas estimaciones.
- Existen muchas técnicas que nos ayudan a calibrar estadísticamente el nivel de confianza que se imprimirá a las estimaciones de intervalo. Sin embargo, estas salen de la óptica
y grado de Derechos de autor: Dr. Oscar Valdemar De la Torre Torres. (Registro en trámite) exigencia del curso ya que en el mismo se le enseñará a dominar las principales
técnicas estadísticas de utilidad para su vida profesional. Si usted desea profundizar en esto, puede cursar una maestría en administración o una en finanzas que logre ese
grado de profundización o puede consultar fuentes más avanzadas en Econometría o análisis de datos multivariante. Para usted, sea suficiente saber que un nivel de confianza
de 90% o mayor es más que suficiente y que no debe de bajar de dicho valor para poder generar buenas estimaciones.
- 3.5 ¿Cómo determinar el tamaño de muestra cuando se busca incrementar la precisión del intervalo
de confianza?
- Ya para finalizar el tema de la Teoría del muestreo es necesario completar un poco más una pregunta que se
planteó previamente ¿Qué tan grande debe ser la muestra para tener un estudio estadístico adecuado? Esta
pregunta se respondió en una primera instancia con el Teorema del límite central que sugiere que la muestra
sea mayor o igual a 30 observaciones para poder suponer que los datos se distribuyen normalmente. Sin
embargo, el mismo se aplica cuando la población de datos del fenómeno en estudio es muy grande y, por
ende, se desconoce el verdadero valor de la desviación estándar poblacional (σ). Puede darse el caso de que
usted sí conozca la desviación estándar de la población y es entonces cuando usted puede determinar el
tamaño de la muestra que debe utilizar para poder ser más preciso en sus estimaciones puntuales de
intervalo. Es decir lograr que su media muestral y error estándar se aproximen a los mismos parámetros
calculados en la población. Cuando se logra que la media muestr
- Ya para finalizar el tema de la Teoría del muestreo es necesario completar un poco más una pregunta que se
planteó previamente ¿Qué tan grande debe ser la muestra para tener un estudio estadístico adecuado? Esta
pregunta se respondió en una primera instancia con el Teorema del límite central que sugiere que la muestra
sea mayor o igual a 30 observaciones para poder suponer que los datos se distribuyen normalmente. Sin
embargo, el mismo se aplica cuando la población de datos del fenómeno en estudio es muy grande y, por
ende, se desconoce el verdadero valor de la desviación estándar poblacional (σ). Puede darse el caso de que
usted sí conozca la desviación estándar de la población y es entonces cuando usted puede determinar el
tamaño de la muestra que debe utilizar para poder ser más preciso en sus estimaciones puntuales de
intervalo. Es decir lograr que su media muestral y error estándar se aproximen a los mismos parámetros
calculados en la población. Cuando se logra que la media muestr
- 3.1 Consideraciones para calcular verdaderas estimaciones de
intervalo
- 4 Prueba de hipótesis: La técnica
clásica
- Hasta ahora se ha visto una de las aplicaciones de la Estadística inferencial que es la estimación de valores futuros
dados los datos muestrales con que se cuenta. Ahora se revisará una de las técnicas más útiles y necesarias de la
misma, la cual no será excepción en aplicaicones de su empresa y futuras materias de su carrera como pueden ser
Producción, Administración de la calidad o Finanzas. Esta técnica de la que se habla es: la prueba de hipótesis. En
el subtema 2.7 se habló de un proceso de 5 pasos que se debe seguir en el proceso de toma de decisiones
utilizando la Estadística y que es el mismo que deberá usted aplicar en su vida cotidiana: 1. Definir el objetivo:
Definir el objetivo de la decisión que se va a hacer. Por ejemplo, determinar si la calidad del inventario es buena o
no, si el número de piezas desperdiciadas es mayor a cierta cantidad, si el número de trimestres con pérdida es
mayor a cierto objetivo o si el número de conexiones fallidas en un sistema de cómputo
- 4.1 Comprobación de hipótesis de una sola
muestra.
- Para exponer el concepto de la prueba de hipótesis se deben recordar tanto la forma de hacer
estimaciones como el cálculo de probabilidades empleando valores Z o valores t. Para iniciar con la
exposición de la idea recordemos al ejemplo de los comerciantes de aguacate. En concreto, centremos
la atención de la empresaria de Chicago. Suponga usted que ella busca definir que la calidad de su
inventario (recordemos que este concepto está medido a través del peso de cada fruta) debe ser mayor
a 3.8 onzas (Oz.) para decir que tiene buena calidad. Suponga que la empresaria toma una muestra de
30 aguacates de su inventario total de 5,000 y la experiencia de inventarios previos le dice que la
desviación estándar en el peso de los aguacates es de 1.1 Oz. Es decir, aquí no se tiene medida la
desviación estándar de una población pero se supone que ésta desviación estándar, que se logra con la
experiencia de inventarios previos, es una aproximación adecuada13 .
- Para exponer el concepto de la prueba de hipótesis se deben recordar tanto la forma de hacer
estimaciones como el cálculo de probabilidades empleando valores Z o valores t. Para iniciar con la
exposición de la idea recordemos al ejemplo de los comerciantes de aguacate. En concreto, centremos
la atención de la empresaria de Chicago. Suponga usted que ella busca definir que la calidad de su
inventario (recordemos que este concepto está medido a través del peso de cada fruta) debe ser mayor
a 3.8 onzas (Oz.) para decir que tiene buena calidad. Suponga que la empresaria toma una muestra de
30 aguacates de su inventario total de 5,000 y la experiencia de inventarios previos le dice que la
desviación estándar en el peso de los aguacates es de 1.1 Oz. Es decir, aquí no se tiene medida la
desviación estándar de una población pero se supone que ésta desviación estándar, que se logra con la
experiencia de inventarios previos, es una aproximación adecuada13 .
- 4.1.1 Ejemplos de los diferentes tipos de prueba de hipótesis con técnica clásica aplicados a una
muestra simple. 4.1.1.1 Pruebas de hipótesis para demostrar igualdad de la media muestral con una
media poblacional conocida o hipotética.
- En un primer acercamiento se demostrará la igualdad que tiene la muestra respecto a la media
objetivo o poblacional según sea el caso. Se tomará como caso de estudio el inventario de la
comerciante de Chicago y se harán ligeros cambios a los estadísticos y parámetros para ilustrar
mejor el empleo de la prueba de hipótesis en diferentes circunstancias.
- En un primer acercamiento se demostrará la igualdad que tiene la muestra respecto a la media
objetivo o poblacional según sea el caso. Se tomará como caso de estudio el inventario de la
comerciante de Chicago y se harán ligeros cambios a los estadísticos y parámetros para ilustrar
mejor el empleo de la prueba de hipótesis en diferentes circunstancias.
- 4.1.1.1.1 Prueba de hipótesis para demostración de igualdad empleando muestras
grandes.
- De entrada, la comerciante de Chicago tiene el siguiente inventario, al cual se le establecen la media
hipotética de 3.8 . Ho Oz y una desviación estándar poblacional, determinada con la experiencia
previa de la empresaria, de 1.1 .
- De entrada, la comerciante de Chicago tiene el siguiente inventario, al cual se le establecen la media
hipotética de 3.8 . Ho Oz y una desviación estándar poblacional, determinada con la experiencia
previa de la empresaria, de 1.1 .
- 4.1.1.1.2 Prueba de hipótesis para demostración de igualdad empleando una muestra grande y una
escala estandarizada
- Ahora se realizará la prueba de hipótesis cambiando la escala original por una escala estandarizada.
Es decir, se aplicará la fórmula del cálculo del valor Z dada en la fórmula 9 a la media muestral a
contrastar, considerando que es muestra grande. Esto lleva al cálculo de los estadísticos de la forma
en que se expresa en la fórmula 24 para muestra grande:
- Ahora se realizará la prueba de hipótesis cambiando la escala original por una escala estandarizada.
Es decir, se aplicará la fórmula del cálculo del valor Z dada en la fórmula 9 a la media muestral a
contrastar, considerando que es muestra grande. Esto lleva al cálculo de los estadísticos de la forma
en que se expresa en la fórmula 24 para muestra grande:
- 4.1.1.1.3 Prueba de hipótesis para un caso de demostración de igualdad con una muestra pequeña
con escala original.
- Note usted cómo se empleó, para las pruebas anteriores, la escala original y el valor Z ya sea para
realizar las estimaciones de intervalo o para definir el estadístico de prueba en una escala
estandarizada. Sin embargo ¿Qué hubiera sucedido si la empresaria hubiera tomado sólo 15
aguacates en lugar de 30 y hubiese decidido emplear la escala original (onzas)? En este punto, la
muestra sería pequeña y la media muestralsería ahora de X 5.1318
- Note usted cómo se empleó, para las pruebas anteriores, la escala original y el valor Z ya sea para
realizar las estimaciones de intervalo o para definir el estadístico de prueba en una escala
estandarizada. Sin embargo ¿Qué hubiera sucedido si la empresaria hubiera tomado sólo 15
aguacates en lugar de 30 y hubiese decidido emplear la escala original (onzas)? En este punto, la
muestra sería pequeña y la media muestralsería ahora de X 5.1318
- 4.1.1.1.4 Prueba de hipótesis para demostración de igualdad empleando una muestra pequeña y una escala
estandarizada.
- Ahora se procederá a realizar la prueba de igualdad con muestra pequeña como la anterior pero utilizando
valores estandarizados. Para ello se tienen los siguientes pasos: 1. Definir una hipótesis nula a demostrar: La
hipótesis a demostrar sería: “El embarque de aguacates recibido tiene una calidad (peso) igual a 3.8 Oz”. Esto se
representa con la siguiente hipótesis nula a demostrar y su alternativa: 0 : 3.8 a : 3.8 H X H X 2. Se
determina, dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de dos colas
establecida con la hipótesis señalada con ID 1, ya que se busca demostrar una igualdad3. Se determina la
función de probabilidad a utilizar: En este caso, al ser muestra pequeña, se emplea la t-Student y, por ende, se
emplea un valor t. 4. Se define el grado de significancia: La muestra con que se trabaja es de 15 piezas. Por tanto
empresaria de
- Ahora se procederá a realizar la prueba de igualdad con muestra pequeña como la anterior pero utilizando
valores estandarizados. Para ello se tienen los siguientes pasos: 1. Definir una hipótesis nula a demostrar: La
hipótesis a demostrar sería: “El embarque de aguacates recibido tiene una calidad (peso) igual a 3.8 Oz”. Esto se
representa con la siguiente hipótesis nula a demostrar y su alternativa: 0 : 3.8 a : 3.8 H X H X 2. Se
determina, dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de dos colas
establecida con la hipótesis señalada con ID 1, ya que se busca demostrar una igualdad3. Se determina la
función de probabilidad a utilizar: En este caso, al ser muestra pequeña, se emplea la t-Student y, por ende, se
emplea un valor t. 4. Se define el grado de significancia: La muestra con que se trabaja es de 15 piezas. Por tanto
empresaria de
- 4.1.1.2 Pruebas de hipótesis para demostrar desigualdad de la media muestral con una media
poblacional conocida o hipotética
- Ahora corresponde el caso de demostrar que existe una desigualdad entre la media muestral de los datos que se
procesan y la media poblacional o la media objetivo (Ho ). Para poder utilizar este ejemplo, suponga ahora
que, por alguna circunstancia peculiar, la empresaria de Chicago desea que el inventario de aguacates sea
diferente de 8.9 Ho Oz. Es decir, puede tener cualquier peso superior o inferior diferente a 8.9 Oz. Entonces,
la comerciante buscará hacer una prueba de hipótesis en donde busca comprobar que dicha desigualdad
existe. A continuación se le presentan los 4 casos de igualdad estudiados pero como desigualdades. Los datos
del problema para el caso de una prueba de hipótesis de desigualdad, como se ha visto, serán los mismos salvo
el valor de la media hipotética 8.9 Ho Oz . A su vez, es de necesidad observar que, para el caso de
desigualdad, las reglas de aceptación de la hipótesis nula (H0 ) cambian por las siguientes marcadas con el ID 2
en la tabla 16: A su vez, e
- Ahora corresponde el caso de demostrar que existe una desigualdad entre la media muestral de los datos que se
procesan y la media poblacional o la media objetivo (Ho ). Para poder utilizar este ejemplo, suponga ahora
que, por alguna circunstancia peculiar, la empresaria de Chicago desea que el inventario de aguacates sea
diferente de 8.9 Ho Oz. Es decir, puede tener cualquier peso superior o inferior diferente a 8.9 Oz. Entonces,
la comerciante buscará hacer una prueba de hipótesis en donde busca comprobar que dicha desigualdad
existe. A continuación se le presentan los 4 casos de igualdad estudiados pero como desigualdades. Los datos
del problema para el caso de una prueba de hipótesis de desigualdad, como se ha visto, serán los mismos salvo
el valor de la media hipotética 8.9 Ho Oz . A su vez, es de necesidad observar que, para el caso de
desigualdad, las reglas de aceptación de la hipótesis nula (H0 ) cambian por las siguientes marcadas con el ID 2
en la tabla 16: A su vez, e
- 4.1.1.2.2 Prueba de hipótesis para demostración de desigualdad empleando una muestra grande y
una escala estandarizada.
- Ahora se realizará la prueba de hipótesis cambiando la escala original por una escala estandarizada.
Es decir, se aplicará la fórmula del cálculo del valor Z dada en la fórmula 9 a la media muestral a
contrastar, considerando si es muestra grande. Esto lleva al cálculo de los estadísticos de la forma en
que se expresa en la fórmula 24 para muestra grande: h0 x x z Retomando el objetivo de la
empresaria de Chicago quien desea demostrar que un determinado embarque de aguacates tiene un
peso diferente a la media hipotética de 8.9 . Ho Oz y una desviación estándar poblacional
(determinada con la experiencia previa de la empresaria) de 1.1 . Oz , la comprobación de hipótesis
llevaría a un estadístico de prueba Z dado por (recuerde que la muestra es de 30 piezas y la media
muestral de 4.7365)
- Ahora se realizará la prueba de hipótesis cambiando la escala original por una escala estandarizada.
Es decir, se aplicará la fórmula del cálculo del valor Z dada en la fórmula 9 a la media muestral a
contrastar, considerando si es muestra grande. Esto lleva al cálculo de los estadísticos de la forma en
que se expresa en la fórmula 24 para muestra grande: h0 x x z Retomando el objetivo de la
empresaria de Chicago quien desea demostrar que un determinado embarque de aguacates tiene un
peso diferente a la media hipotética de 8.9 . Ho Oz y una desviación estándar poblacional
(determinada con la experiencia previa de la empresaria) de 1.1 . Oz , la comprobación de hipótesis
llevaría a un estadístico de prueba Z dado por (recuerde que la muestra es de 30 piezas y la media
muestral de 4.7365)
- 4.1.1.2.3 Prueba de hipótesis para un caso de demostración de desigualdad con una muestra pequeña
con escala original.
- Ahora se retoma el caso de una muestra pequeña con 15 piezas que tiene una media muestral de de X
5.1318 y un objetivo de demostrar desigualdad para una media hipotética de 0 8.9 H Oz . Con
estos datos iniciales, para este tipo de prueba de hipótesis Definir una hipótesis nula a demostrar: La
hipótesis a demostrar sería: “El embarque de aguacates recibido tiene una calidad (peso) diferente a
8.9 Oz”. Esto se representa con la siguiente hipótesis nula a demostrar y su alternativa Se determina,
dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es importante observar,
siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de dos colas
establecida con la hipótesis señalada
- Ahora se retoma el caso de una muestra pequeña con 15 piezas que tiene una media muestral de de X
5.1318 y un objetivo de demostrar desigualdad para una media hipotética de 0 8.9 H Oz . Con
estos datos iniciales, para este tipo de prueba de hipótesis Definir una hipótesis nula a demostrar: La
hipótesis a demostrar sería: “El embarque de aguacates recibido tiene una calidad (peso) diferente a
8.9 Oz”. Esto se representa con la siguiente hipótesis nula a demostrar y su alternativa Se determina,
dada la hipótesis, si es prueba de dos colas, cola superior y cola inferior: Aquí es importante observar,
siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de dos colas
establecida con la hipótesis señalada
- 4.1.1.3.2 Prueba de hipótesis de cola superior empleando muestra grande y escala
estandarizada
- Ahora se hará la misma prueba de hipótesis de cola superior con muestra grande empleando una escala
estandarizada. Para ello se siguieron estos pasos: 1. Definir una hipótesis nula a demostrar: La hipótesis
a demostrar sería: “El embarque de aguacates recibido tiene una calidad (peso) mayor a 2.5 Oz”. Esto se
representa con la siguiente hipótesis nula a demostrar y su alternativa: 0 : 2.5 a : 2.5 H X H X 2. Se
determina, dada la hipótesis, si es prueba dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de dos
colas establecida con la hipótesis señalada con ID 3, ya que se busca demostrar una prueba de cola
superior
- Ahora se hará la misma prueba de hipótesis de cola superior con muestra grande empleando una escala
estandarizada. Para ello se siguieron estos pasos: 1. Definir una hipótesis nula a demostrar: La hipótesis
a demostrar sería: “El embarque de aguacates recibido tiene una calidad (peso) mayor a 2.5 Oz”. Esto se
representa con la siguiente hipótesis nula a demostrar y su alternativa: 0 : 2.5 a : 2.5 H X H X 2. Se
determina, dada la hipótesis, si es prueba dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de dos
colas establecida con la hipótesis señalada con ID 3, ya que se busca demostrar una prueba de cola
superior
- 4.1.1.3.3 Prueba de hipótesis de cola superior con muestra pequeña y escala
original
- Ahora se tomará el caso de la muestra pequeña (15 aguacates) con su media muestral de 5.1318 Oz y
la misma desviación estándar poblacional de 1.1 Oz. En este caso se trabajará con la escala original.
Para ello, la empresaria siguió estos pasos: 1. Definir una hipótesis nula a demostrar: La hipótesis a
demostrar sería: “El embarque de aguacates recibido tiene una calidad (peso) mayor a 2.5 Oz”. Esto se
representa con la siguiente hipótesis nula a demostrar y su alternativa: 0 : 2.5 : 2.5 a H X H X 2. Se
determina, dada la hipótesis, si es prueba dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de una
cola establecida con la hipótesis señalada con ID 3, ya que se busca demostrar una prueba de cola
superior:
- Ahora se tomará el caso de la muestra pequeña (15 aguacates) con su media muestral de 5.1318 Oz y
la misma desviación estándar poblacional de 1.1 Oz. En este caso se trabajará con la escala original.
Para ello, la empresaria siguió estos pasos: 1. Definir una hipótesis nula a demostrar: La hipótesis a
demostrar sería: “El embarque de aguacates recibido tiene una calidad (peso) mayor a 2.5 Oz”. Esto se
representa con la siguiente hipótesis nula a demostrar y su alternativa: 0 : 2.5 : 2.5 a H X H X 2. Se
determina, dada la hipótesis, si es prueba dos colas, cola superior y cola inferior: Aquí es importante
observar, siguiendo las recomendaciones de la tabla 16, que se utiliza una prueba de hipótesis de una
cola establecida con la hipótesis señalada con ID 3, ya que se busca demostrar una prueba de cola
superior:
- 4.1.1.3.4 Prueba de hipótesis de cola superior con muestra pequeña y escala de
estandarizada
- Se determina la función de probabilidad a utilizar: En este caso, al ser muestra pequeña, se emplea la
distribución t-Student y, por ende, se emplea un valor t. 4. Se define el grado de significancia: La muestra
con que se trabaja es de 15 piezas. Por tanto, la empresaria decide utilizar un valor t que corresponda a
un nivel de significancia de 5%. Al ser esta una prueba de una cola (cola superior), debe buscar un valor
t en tablas que corresponda a 5% de probabilidad y 14 grados de libertad. Esto le lleva a un valor t de
1.7613. 5. Se define si se trabaja con la escala original o con una estandarizada: En este ejemplo, la
empresaria decidió trabajar con la escala original por lo que utilizó el valor Z para definir el valor crítico
superior (IC ) del intervalo de confianza con los que aceptará o rechazará la hipótesis.
- Se determina la función de probabilidad a utilizar: En este caso, al ser muestra pequeña, se emplea la
distribución t-Student y, por ende, se emplea un valor t. 4. Se define el grado de significancia: La muestra
con que se trabaja es de 15 piezas. Por tanto, la empresaria decide utilizar un valor t que corresponda a
un nivel de significancia de 5%. Al ser esta una prueba de una cola (cola superior), debe buscar un valor
t en tablas que corresponda a 5% de probabilidad y 14 grados de libertad. Esto le lleva a un valor t de
1.7613. 5. Se define si se trabaja con la escala original o con una estandarizada: En este ejemplo, la
empresaria decidió trabajar con la escala original por lo que utilizó el valor Z para definir el valor crítico
superior (IC ) del intervalo de confianza con los que aceptará o rechazará la hipótesis.
- 4.1.1.4 Ejemplos de pruebas de hipótesis de cola inferior.
- Para el caso de la prueba de hipótesis de cola inferior se tiene la misma lógica de análisis que las pruebas
de cola inferior, con la diferencia de que las reglas de decisión para aceptar la hipótesis nula () se dan por
el renglón o ID 3 de la tabla 16: Por cuestión de espacio, no se hará una exposición extensa de los cuatro
posibles casos dado el tamaño de muestra (grande o pequeña) y tipo de escala (original o estandarizada).
Lo que se hará será simplemente citar un ejemplo consistente en una muestra grande con escala
estandarizada. Usted podrá observar que los pasos a seguir en los otros tres casos son similares a las 4
pruebas previas de cola superior. Solo cambiará, como se ha mencionado, la regla de aceptación de H0 .
Para exponer este ejemplo, se supondrá ahora que la empresaria no quiere aguacates con un peso menor
a 7 Oz, por lo que deberá demostrar que el embarque que ha recibido se ajusta a dicho estándar de
calidad.
- Para el caso de la prueba de hipótesis de cola inferior se tiene la misma lógica de análisis que las pruebas
de cola inferior, con la diferencia de que las reglas de decisión para aceptar la hipótesis nula () se dan por
el renglón o ID 3 de la tabla 16: Por cuestión de espacio, no se hará una exposición extensa de los cuatro
posibles casos dado el tamaño de muestra (grande o pequeña) y tipo de escala (original o estandarizada).
Lo que se hará será simplemente citar un ejemplo consistente en una muestra grande con escala
estandarizada. Usted podrá observar que los pasos a seguir en los otros tres casos son similares a las 4
pruebas previas de cola superior. Solo cambiará, como se ha mencionado, la regla de aceptación de H0 .
Para exponer este ejemplo, se supondrá ahora que la empresaria no quiere aguacates con un peso menor
a 7 Oz, por lo que deberá demostrar que el embarque que ha recibido se ajusta a dicho estándar de
calidad.
- 4.2 ¿Cuándo se utiliza la escala original y cuándo la
estandarizada?
- Hasta el momento se ha observado que una de las variantes que puede tener la comprobación de
hipótesis se refiere a la escala empleada. Esta puede ser la escala original o la escala estandarizada,
lograda al aplicar las fórmulas 24 o 25 según sea el tamaño de la muestra. Sin embargo, poco se ha
dicho sobre el criterio para utilizar una escala u otra. En realidad, no existen reglas generales para
decidir. Más bien la selección se da en función del tipo de problema y las preferencias del analista. Sin
embargo, algo que puede ser de utilidad para elegir la escala estandarizada es el hecho de que ésta
sirve para homologar escalas. Por ejemplo, la variable estandarizada, como veremos en breve, sirve
más para comparar inventarios con variabilidades de peso diferentes. Tal es el caso de los empresarios
aguacateros de Morelia y Chicago. Por tanto, la selección de la escala es netamente personal a
inherente al analista.
- Hasta el momento se ha observado que una de las variantes que puede tener la comprobación de
hipótesis se refiere a la escala empleada. Esta puede ser la escala original o la escala estandarizada,
lograda al aplicar las fórmulas 24 o 25 según sea el tamaño de la muestra. Sin embargo, poco se ha
dicho sobre el criterio para utilizar una escala u otra. En realidad, no existen reglas generales para
decidir. Más bien la selección se da en función del tipo de problema y las preferencias del analista. Sin
embargo, algo que puede ser de utilidad para elegir la escala estandarizada es el hecho de que ésta
sirve para homologar escalas. Por ejemplo, la variable estandarizada, como veremos en breve, sirve
más para comparar inventarios con variabilidades de peso diferentes. Tal es el caso de los empresarios
aguacateros de Morelia y Chicago. Por tanto, la selección de la escala es netamente personal a
inherente al analista.
- 4.3 ¿Qué se hace cuando se desconoce la desviación estándar poblacónal?
- Hasta ahora se ha trabajado bajo el supuesto de que se conoce la desviación estándar poblacional o
se supone una partiendo de la experiencia propia. Por ejemplo, la empresaria de chicago partió de lo
que ha observado con su proveedor, en el sentido de fijar la desviación estándar del peso de
aguacates que ha recibido a lo largo de la historia como de 1.1Oz. Sin embargo, no siempre se conoce
este valor por lo que debe calcularse para poder determinar los estadísticos Z o t. Cuando el tamaño
de la muestra es grande (n≥30), se calcula el error estándar con la fórmula 8: x n Cuando el
tamaño de la muestra es pequeña (n<30), se calcula el error estándar
- Hasta ahora se ha trabajado bajo el supuesto de que se conoce la desviación estándar poblacional o
se supone una partiendo de la experiencia propia. Por ejemplo, la empresaria de chicago partió de lo
que ha observado con su proveedor, en el sentido de fijar la desviación estándar del peso de
aguacates que ha recibido a lo largo de la historia como de 1.1Oz. Sin embargo, no siempre se conoce
este valor por lo que debe calcularse para poder determinar los estadísticos Z o t. Cuando el tamaño
de la muestra es grande (n≥30), se calcula el error estándar con la fórmula 8: x n Cuando el
tamaño de la muestra es pequeña (n<30), se calcula el error estándar
- 4.4 Pruebas de hipótesis para comparar
muestras.
- Para ilustrar el empleo de este tipo de prueba de hipótesis, tómese la idea original que tenían los dos empresarios
aguacateros de comparar la calidad de sus inventarios, con la finalidad de saber si el proveedor, que es el mismo
para ambos, les vende la misma calidad. Lo primero que hacen los empresarios es homologar sus escalas de
medida, por lo que deciden trabajar con onzas. Posteriormente, deciden probar la calidad estableciendo como
objetivo determinar que la calidad que ambos reciben es la misma. Para poder establecer el ejercicio, recuerde usted
el tema de estimaciones de intervalo de diferencias. En concreto, que las muestras pueden ser independientes o
relacionadas. Para este caso, dado que ambos reciben aguacates del mismo proveedor y este puede determinar qué
calidad mandar a cada cliente, se supondrá que la muestra está relacionada, acoplada o apareada. Es decir, las
muestras no son independientes. Por tanto, deben calcularse diferencias entre los valores de cada observaci
- Para ilustrar el empleo de este tipo de prueba de hipótesis, tómese la idea original que tenían los dos empresarios
aguacateros de comparar la calidad de sus inventarios, con la finalidad de saber si el proveedor, que es el mismo
para ambos, les vende la misma calidad. Lo primero que hacen los empresarios es homologar sus escalas de
medida, por lo que deciden trabajar con onzas. Posteriormente, deciden probar la calidad estableciendo como
objetivo determinar que la calidad que ambos reciben es la misma. Para poder establecer el ejercicio, recuerde usted
el tema de estimaciones de intervalo de diferencias. En concreto, que las muestras pueden ser independientes o
relacionadas. Para este caso, dado que ambos reciben aguacates del mismo proveedor y este puede determinar qué
calidad mandar a cada cliente, se supondrá que la muestra está relacionada, acoplada o apareada. Es decir, las
muestras no son independientes. Por tanto, deben calcularse diferencias entre los valores de cada observaci
- Hasta ahora se ha visto una de las aplicaciones de la Estadística inferencial que es la estimación de valores futuros
dados los datos muestrales con que se cuenta. Ahora se revisará una de las técnicas más útiles y necesarias de la
misma, la cual no será excepción en aplicaicones de su empresa y futuras materias de su carrera como pueden ser
Producción, Administración de la calidad o Finanzas. Esta técnica de la que se habla es: la prueba de hipótesis. En
el subtema 2.7 se habló de un proceso de 5 pasos que se debe seguir en el proceso de toma de decisiones
utilizando la Estadística y que es el mismo que deberá usted aplicar en su vida cotidiana: 1. Definir el objetivo:
Definir el objetivo de la decisión que se va a hacer. Por ejemplo, determinar si la calidad del inventario es buena o
no, si el número de piezas desperdiciadas es mayor a cierta cantidad, si el número de trimestres con pérdida es
mayor a cierto objetivo o si el número de conexiones fallidas en un sistema de cómputo
- 5 Prueba de hipótesis: Las técnicas Ji- cuadrada y
ANOVA
- Hasta ahora se ha visto el caso en el que se realizan pruebas de hipótesis comprobando medias
muestrales respecto a una media poblacional o una media hipotética. A su vez, se hicieron
comparaciones de diferencias de medias muestrales entre dos poblaciones diferentes. Dentro de los
supuestos que se han manejado es determinar que existe dependencia o independencia en dichas
poblaciones, por un lado y que están ya sea normalmente distribuidas (si se trata de una población o
muestra grande) o t-Student distribuidas si se trata de una muestra pequeña.
- 5.1 La técnica Ji-Cuadrada 5.1.1 Prueba de hipótesis para
demostrar independencia.
- Ahora se revisará el empleo de la técnica Ji-Cuadrada para determinar si los atributos de dos o más
variables en una muestra o población son independientes o no. Por ejemplo, Steve Jobs pudo hacer
una encuesta más amplia y detallada que la previamente vista en donde se asignaron calificaciones, y
ahora preguntar a diferentes individuos de los cuatro segmentos o estratos
- Ahora se revisará el empleo de la técnica Ji-Cuadrada para determinar si los atributos de dos o más
variables en una muestra o población son independientes o no. Por ejemplo, Steve Jobs pudo hacer
una encuesta más amplia y detallada que la previamente vista en donde se asignaron calificaciones, y
ahora preguntar a diferentes individuos de los cuatro segmentos o estratos
- 5.1.2 Distribución de probabilidad
ji-cuadrada
- Recuerde usted que las distribuciones normal (gaussiana) y t-Student son simétricas e incluyen valores
de probabilidad tanto a la izquierda como a la derecha del cero. Estas distribuciones de probabilidad
son muy útiles para muchos fenómenos como los revisados. Sin embargo, cuando se trata con valores
que solo son positivos, será de mucho interés tener una distribución de probabilidad que nunca tenga
valores negativos en su distribución de probabilidad. Por ejemplo, el precio de una acción nuca tendrá
valores negativos pero, en repetidas ocasiones de nuestros ejercicios, las estimaciones de intervalo
llevaban a límites inferiores negativos que no era lógico que existan. Por ejemplo, podríamos tener la
estimación de intervalo del precio de una acción, las calificaciones de un grupo de clase o el peso de
los aguacates
- Recuerde usted que las distribuciones normal (gaussiana) y t-Student son simétricas e incluyen valores
de probabilidad tanto a la izquierda como a la derecha del cero. Estas distribuciones de probabilidad
son muy útiles para muchos fenómenos como los revisados. Sin embargo, cuando se trata con valores
que solo son positivos, será de mucho interés tener una distribución de probabilidad que nunca tenga
valores negativos en su distribución de probabilidad. Por ejemplo, el precio de una acción nuca tendrá
valores negativos pero, en repetidas ocasiones de nuestros ejercicios, las estimaciones de intervalo
llevaban a límites inferiores negativos que no era lógico que existan. Por ejemplo, podríamos tener la
estimación de intervalo del precio de una acción, las calificaciones de un grupo de clase o el peso de
los aguacates
- 5.1.3 Algunas consideraciones a tomar con la prueba
ji-cuadrada
- Existen dos situaciones que deben tenerse presente al momento de realizar pruebas con la técnica
ji-cuadrada para los tres usos que interesan: 1. Nunca se deben trabajar con tablas de contingencia
que tengan frecuencias menores a 5. Es decir, que el valor de una celda sea menor a 5. Si en algún
momento se presentara este caso en dos o más celdas, podemos eliminar algunas categorías (renglón
o columna) y combinar los valores de la (s) eliminada (s) con otra que esté en el mismo caso y así
lograr frecuencias mayores o iguales a 5. Sin embargo, esto tiene la limitante de la pérdida de una o
varias categorías y el examen de independencia entre variables quedaría muy parcial. 2. Si, por alguna
circunstancia, el valor ji-cuadrada derivado con la fórmula 24 diera cero, debe sospecharse del
resultado ya que se puede estar en presencia de un problema de una inapropiada recolección de datos.
- Existen dos situaciones que deben tenerse presente al momento de realizar pruebas con la técnica
ji-cuadrada para los tres usos que interesan: 1. Nunca se deben trabajar con tablas de contingencia
que tengan frecuencias menores a 5. Es decir, que el valor de una celda sea menor a 5. Si en algún
momento se presentara este caso en dos o más celdas, podemos eliminar algunas categorías (renglón
o columna) y combinar los valores de la (s) eliminada (s) con otra que esté en el mismo caso y así
lograr frecuencias mayores o iguales a 5. Sin embargo, esto tiene la limitante de la pérdida de una o
varias categorías y el examen de independencia entre variables quedaría muy parcial. 2. Si, por alguna
circunstancia, el valor ji-cuadrada derivado con la fórmula 24 diera cero, debe sospecharse del
resultado ya que se puede estar en presencia de un problema de una inapropiada recolección de datos.
- 5.1.4 Prueba de hipótesis ji cuadrada para bondad de ajuste (determinar la función de probabilidad a
emplear en un grupo de datos).
- Ahora se revisará uno de los usos más comunes que tiene la prueba con distribución ji-cuadrada:
Determinar si el comportamiento de un grupo de datos se explica con alguna función de densidad
determinada. Como ha visto hasta ahora, el análisis de prueba con técnica ji-cuadrada se enfoca a
trabajar con tablas de contingencias en donde se presentan las diferentes frecuencias observadas en
las diferentes combinaciones de variables. Sin embargo, cuando se tiene una serie de datos, no
siempre se puede hacer una tabla de frecuencias, salvo que sea el histograma, de los datos debido a
que se deben fijar clases o intervalos discrecionales. Existen algunas otras distribuciones de
probabilidad cómo la binomial, la Poisson u otras que se enfocan a eventos aleatorios discretos
(Recuerde usted la definición correspondiente) y en estas se puede hacer un análisis de bondad de
ajuste con técnica ji-cuadrada que no difiere mucho del anteriormente realizado
- Ahora se revisará uno de los usos más comunes que tiene la prueba con distribución ji-cuadrada:
Determinar si el comportamiento de un grupo de datos se explica con alguna función de densidad
determinada. Como ha visto hasta ahora, el análisis de prueba con técnica ji-cuadrada se enfoca a
trabajar con tablas de contingencias en donde se presentan las diferentes frecuencias observadas en
las diferentes combinaciones de variables. Sin embargo, cuando se tiene una serie de datos, no
siempre se puede hacer una tabla de frecuencias, salvo que sea el histograma, de los datos debido a
que se deben fijar clases o intervalos discrecionales. Existen algunas otras distribuciones de
probabilidad cómo la binomial, la Poisson u otras que se enfocan a eventos aleatorios discretos
(Recuerde usted la definición correspondiente) y en estas se puede hacer un análisis de bondad de
ajuste con técnica ji-cuadrada que no difiere mucho del anteriormente realizado
- 5.1.5 Prueba de hipótesis ji-cuadrada para hacer inferencias sobre la varianza de una sola población (o
muestra)
- En este tipo de prueba de hipótesis se determinará si la varianza que se calcula en una muestra de
datos o población es igual, mayor o menor a algún nivel de varianza objetivo predeterminado ( 2 H 0
). La lógica de la prueba de hipótesis es muy similar al método de valores Z o t empleado en la técnica
clásica. Es decir se debe determinar un estadístico ji-cuadrada que en breve se delimitará y extraer un
valor ji-cuadrada tanto para el intervalo superior como el inferior (valores críticos), según el caso que
aplique (si es prueba de una o dos colas). Otra diferencia obvia y fundamental de la prueba ji-cuadrada
es que no emplea una distribución normal o t-Student para fijar los mencionados valores críticos.
- En este tipo de prueba de hipótesis se determinará si la varianza que se calcula en una muestra de
datos o población es igual, mayor o menor a algún nivel de varianza objetivo predeterminado ( 2 H 0
). La lógica de la prueba de hipótesis es muy similar al método de valores Z o t empleado en la técnica
clásica. Es decir se debe determinar un estadístico ji-cuadrada que en breve se delimitará y extraer un
valor ji-cuadrada tanto para el intervalo superior como el inferior (valores críticos), según el caso que
aplique (si es prueba de una o dos colas). Otra diferencia obvia y fundamental de la prueba ji-cuadrada
es que no emplea una distribución normal o t-Student para fijar los mencionados valores críticos.
- 5.1.6 Haciendo estimaciones de intervalos de
varianzas.
- Así como se hicieron estimaciones de intervalos dado lo cambiante de la media muestral para
determinar hasta donde podría fluctuar la misma (hacia arriba y/o hacia abajo), también se puede
replicar el ejercicio en el caso de las varianzas. Lo único que se tiene que hacer es calcular los
correspondientes intervalos de confianza a través de la siguiente expresión: Aguacate Peso (g)
Aguacate Peso (g) 1 9.24156638 16 6.889437022 2 12.19955397 17 2.805266224 3 7.828912118 18
1.263366478 4 0.34339132 19 0.321894217 5 5.446988563 20 0.689824563 6 4.308144063 21
5.14666579 7 2.778536985 22 0.934611953 8 4.78302773 23 6.680220548 9 2.099924462 24
3.119794535 10 4.27460843 25 3.4652034 11 4.691816478 26 3.796020078 12 2.939152383 27
5.120936133 13 5.27263691 28 8.525283542 14 8.447711808 29 11.79793331 15 2.321627026 30
4.563482046 4.736584616 234.61 9.788691792 1.21 Calidad del inventario de la comerciante de
Chicago (muestra grande) 17.7084 0 50 100 150 200 250 300 0 0.01 0.02 0.03 0.04 0.05 0
- Así como se hicieron estimaciones de intervalos dado lo cambiante de la media muestral para
determinar hasta donde podría fluctuar la misma (hacia arriba y/o hacia abajo), también se puede
replicar el ejercicio en el caso de las varianzas. Lo único que se tiene que hacer es calcular los
correspondientes intervalos de confianza a través de la siguiente expresión: Aguacate Peso (g)
Aguacate Peso (g) 1 9.24156638 16 6.889437022 2 12.19955397 17 2.805266224 3 7.828912118 18
1.263366478 4 0.34339132 19 0.321894217 5 5.446988563 20 0.689824563 6 4.308144063 21
5.14666579 7 2.778536985 22 0.934611953 8 4.78302773 23 6.680220548 9 2.099924462 24
3.119794535 10 4.27460843 25 3.4652034 11 4.691816478 26 3.796020078 12 2.939152383 27
5.120936133 13 5.27263691 28 8.525283542 14 8.447711808 29 11.79793331 15 2.321627026 30
4.563482046 4.736584616 234.61 9.788691792 1.21 Calidad del inventario de la comerciante de
Chicago (muestra grande) 17.7084 0 50 100 150 200 250 300 0 0.01 0.02 0.03 0.04 0.05 0
- 5.2 Prueba
ANOVA.
- La prueba ANOVA es una prueba muy poderosa y muy simple de interpretar. La misma nos servirá para
comparar no solo dos medias a la vez sino más de dos medias de muestras que pueden ser
independientes o estar acopladas, apareadas o relacionadas y que pueden venir de tamaños de
muestras totalmente diferentes. Por ejemplo, piense usted que necesita comparar siete muestras
diferentes correspondientes a siete inventarios de aguacate. Los métodos de la técnica clásica
Estadística II Notas del profesor para el alumno Página: 150 Derechos de autor: Dr. Oscar Valdemar De
la Torre Torres. (Registro en trámite) serían bastante limitados si desea hacer pruebas de hipótesis (ya
sea de muestras acopladas o independientes). Incluso el hacer esto sería laborioso ya que le implicaría
hacer 21 pruebas de hipótesis diferentes. Es decir una prueba de hipótesis de la muestra 1 con la
muestra 2 y así sucesivamente.
- La prueba ANOVA es una prueba muy poderosa y muy simple de interpretar. La misma nos servirá para
comparar no solo dos medias a la vez sino más de dos medias de muestras que pueden ser
independientes o estar acopladas, apareadas o relacionadas y que pueden venir de tamaños de
muestras totalmente diferentes. Por ejemplo, piense usted que necesita comparar siete muestras
diferentes correspondientes a siete inventarios de aguacate. Los métodos de la técnica clásica
Estadística II Notas del profesor para el alumno Página: 150 Derechos de autor: Dr. Oscar Valdemar De
la Torre Torres. (Registro en trámite) serían bastante limitados si desea hacer pruebas de hipótesis (ya
sea de muestras acopladas o independientes). Incluso el hacer esto sería laborioso ya que le implicaría
hacer 21 pruebas de hipótesis diferentes. Es decir una prueba de hipótesis de la muestra 1 con la
muestra 2 y así sucesivamente.
- 5.2.1 La función de probabilidad
F.
- 1. Si la distribución ji-cuadrada se utiliza para determinar las probabilidades de una varianza. 2. Si por
otro lado es estadístico F es la división entre dos varianzas (la varianza entre muestras y entre el total
de datos). 3. Entonces la función de probabilidad F se da por la siguiente expresión: Fórmula 37:
Determinación de la probabilidad F a partir de la probabilidad ji-cuadrada. 2 , , 1 2 1, 1 , , 1 (Varianza
entre medias muestrales) (Varianza entre datos de las muestras en conjunto) T T i k k n i n P X F F P X
La probabilidad anterior se logra de la tabla de probabilidades F como la presentada
en la plataforma Moodle en el tema de la prueba ANOVA. Para determinar la misma se deben
especificar los grados de libertad del numerados, que corresponden el número de muestras (k )
empleadas menos 1 grado de libertad y el total de datos en las muestras en conjunto ( T n ) menos un
grado de libertad (para mayor referencia, consulte en la tabla el ejemplo que se da).
- 1. Si la distribución ji-cuadrada se utiliza para determinar las probabilidades de una varianza. 2. Si por
otro lado es estadístico F es la división entre dos varianzas (la varianza entre muestras y entre el total
de datos). 3. Entonces la función de probabilidad F se da por la siguiente expresión: Fórmula 37:
Determinación de la probabilidad F a partir de la probabilidad ji-cuadrada. 2 , , 1 2 1, 1 , , 1 (Varianza
entre medias muestrales) (Varianza entre datos de las muestras en conjunto) T T i k k n i n P X F F P X
La probabilidad anterior se logra de la tabla de probabilidades F como la presentada
en la plataforma Moodle en el tema de la prueba ANOVA. Para determinar la misma se deben
especificar los grados de libertad del numerados, que corresponden el número de muestras (k )
empleadas menos 1 grado de libertad y el total de datos en las muestras en conjunto ( T n ) menos un
grado de libertad (para mayor referencia, consulte en la tabla el ejemplo que se da).
- 5.2.2 La prueba
F.
- Ahora que se observa que se tienen los múltiples datos necesarios como los grados de libertad del
numerador y los del denominador se puede calcular el estadístico F y determinar un valor crítico F
empleando las tablas correspondientes al emplear los grados de libertad del numerador y del
denominador. Para ello será de necesidad utilizar las tablas de valores F como la que se presenta en la
plataforma Moodle en el tema correspondiente a la prueba ANOVA. Para ilustrar la prueba de
hipótesis con la técnica ANOVA retomemos el ejemplo de los empresarios aguacateros de Morelia y
Chicago. Lo que ellos quieren plantear es que el inventario que ellos reciben por parte de su proveedor
(que es el mismo), tienen la misma calidad.
- Ahora que se observa que se tienen los múltiples datos necesarios como los grados de libertad del
numerador y los del denominador se puede calcular el estadístico F y determinar un valor crítico F
empleando las tablas correspondientes al emplear los grados de libertad del numerador y del
denominador. Para ello será de necesidad utilizar las tablas de valores F como la que se presenta en la
plataforma Moodle en el tema correspondiente a la prueba ANOVA. Para ilustrar la prueba de
hipótesis con la técnica ANOVA retomemos el ejemplo de los empresarios aguacateros de Morelia y
Chicago. Lo que ellos quieren plantear es que el inventario que ellos reciben por parte de su proveedor
(que es el mismo), tienen la misma calidad.
- 5.2.3 Prueba ANOVA para probar la igualdad en la varianza entre dos muestras. El caso de la cola
superior.
- Previa mente se estudió que la técnica clásica es de utilidad para comparar medias muestrales y que la
ji-cuadrada lo es para contrastar varianzas respecto a una varianza objetivo. A su vez se acaba de revisar
que la prueba ANOVA es muy poderosa para contrastar igualdad entre medias. Adicional a la aplicación
anterior, la prueba ANOVA puede ser utilizada para comprobar la igualdad estadística de la varianza
entre dos muestras (solo dos y objetivo que no se logra con la técnica jicuadrada). Para ilustrar el método
(que es muy sencillo y cambia poco respecto al anterior) se seguirá trabajando con el ejemplo
- Previa mente se estudió que la técnica clásica es de utilidad para comparar medias muestrales y que la
ji-cuadrada lo es para contrastar varianzas respecto a una varianza objetivo. A su vez se acaba de revisar
que la prueba ANOVA es muy poderosa para contrastar igualdad entre medias. Adicional a la aplicación
anterior, la prueba ANOVA puede ser utilizada para comprobar la igualdad estadística de la varianza
entre dos muestras (solo dos y objetivo que no se logra con la técnica jicuadrada). Para ilustrar el método
(que es muy sencillo y cambia poco respecto al anterior) se seguirá trabajando con el ejemplo
- Hasta ahora se ha visto el caso en el que se realizan pruebas de hipótesis comprobando medias
muestrales respecto a una media poblacional o una media hipotética. A su vez, se hicieron
comparaciones de diferencias de medias muestrales entre dos poblaciones diferentes. Dentro de los
supuestos que se han manejado es determinar que existe dependencia o independencia en dichas
poblaciones, por un lado y que están ya sea normalmente distribuidas (si se trata de una población o
muestra grande) o t-Student distribuidas si se trata de una muestra pequeña.
- 6 Estadística multivariada: Regresión lineal simple y multivariada.
- Conceptos de estadística multivariada. Hasta el momento se ha trabajado con el contraste de muestras o poblaciones que tienen una
distribución de probabilidad identidad y, en algunos casos, que tienen un comportamiento dependiente una de la otra. En la vida
cotidiana, existen pocos fenómenos que no tienen algún tipo de relación estadística por lo que la probabilidad de suceso de dos o más
eventos conjuntos debe de determinarse
- 6.1 El coeficiente de correlación y su interacción con la covarianza.
- El responder que causa esto es algo muy amplio de responder y que se investiga a la luz de las diferentes ciencias.
Por ejemplo qué hace que el número de flores en un valle sea mayor conforme hay lluvia es algo que la biología,
en especial la Botánica, nos puede responder. Qué hace que el precio de una acción se mueva en conjunto con el
de otra es otra situación que se puede investigar con la Economía Financiera y así sucesivamente. Todas las causas
de este fenómeno de interacción se responden con las respectivas ciencias de interés. Sin embargo responder ¿en
qué magnitud y con qué grado de apego se mueven dos fenómenos modelados matemáticamente a través de dos
variables aleatorias? Es algo que se responde gracias a la estadística. En qué magnitud se mueve una variable
aleatoria de manera conjunta respecto al movimiento de otra se determina con la covarianza. Por ejemplo
observe las dos covarianzas del ejercicio anterior. Esto nos dice que el precio de AMX varía en respecto a su media
- El responder que causa esto es algo muy amplio de responder y que se investiga a la luz de las diferentes ciencias.
Por ejemplo qué hace que el número de flores en un valle sea mayor conforme hay lluvia es algo que la biología,
en especial la Botánica, nos puede responder. Qué hace que el precio de una acción se mueva en conjunto con el
de otra es otra situación que se puede investigar con la Economía Financiera y así sucesivamente. Todas las causas
de este fenómeno de interacción se responden con las respectivas ciencias de interés. Sin embargo responder ¿en
qué magnitud y con qué grado de apego se mueven dos fenómenos modelados matemáticamente a través de dos
variables aleatorias? Es algo que se responde gracias a la estadística. En qué magnitud se mueve una variable
aleatoria de manera conjunta respecto al movimiento de otra se determina con la covarianza. Por ejemplo
observe las dos covarianzas del ejercicio anterior. Esto nos dice que el precio de AMX varía en respecto a su media
- 6.2 El modelo regresión lineal simple para establecer relaciones estadísticas entre variables y hacer pronósticos
básicos.
- En este punto estamos entrando a una de las aplicaciones más importantes (sino la más importante) de la
Estadística inferencial: la regresión. Con esta se logrará establecer la relación estadística entre variables de la
forma: y x Esto quiere decir que la variable y se determina por una ecuación matemática en donde a una
constante (que puede ser de cero o de otro valor positivo o negativo) se le suma un valor de x multiplicado por
un número o constante (que puede ser de cero o de otro valor positivo o negativo). Si usted observa
detenidamente el modelo de regresión, podrá apreciar que será capaz de hacer estimaciones del tipo “por cada
valor de x se tendrá un valor de y dado por x “. Es decir ya podrá decir cuánto valdrá y dado el de x . La clave
aquí estará en calcular los coeficientes y . Esto es lo que determinaremos a continuación y a lo que le daremos
una explicación gráfica.
- En este punto estamos entrando a una de las aplicaciones más importantes (sino la más importante) de la
Estadística inferencial: la regresión. Con esta se logrará establecer la relación estadística entre variables de la
forma: y x Esto quiere decir que la variable y se determina por una ecuación matemática en donde a una
constante (que puede ser de cero o de otro valor positivo o negativo) se le suma un valor de x multiplicado por
un número o constante (que puede ser de cero o de otro valor positivo o negativo). Si usted observa
detenidamente el modelo de regresión, podrá apreciar que será capaz de hacer estimaciones del tipo “por cada
valor de x se tendrá un valor de y dado por x “. Es decir ya podrá decir cuánto valdrá y dado el de x . La clave
aquí estará en calcular los coeficientes y . Esto es lo que determinaremos a continuación y a lo que le daremos
una explicación gráfica.
- 6.2.1 Determinación de los coeficientes del modelo de regresión.
- Para determinar los coeficientes de regresión, siendo esta el modelo resultante de la interacción entre las dos
variables, se ocupa la covarianza que es la que cuantifica el grado de variación promedio conjunta entre
variables, la varianza de la variable regresora ( x ) 16, y la media muestral de la regresada (Y ):
- Para determinar los coeficientes de regresión, siendo esta el modelo resultante de la interacción entre las dos
variables, se ocupa la covarianza que es la que cuantifica el grado de variación promedio conjunta entre
variables, la varianza de la variable regresora ( x ) 16, y la media muestral de la regresada (Y ):
- Conceptos de estadística multivariada. Hasta el momento se ha trabajado con el contraste de muestras o poblaciones que tienen una
distribución de probabilidad identidad y, en algunos casos, que tienen un comportamiento dependiente una de la otra. En la vida
cotidiana, existen pocos fenómenos que no tienen algún tipo de relación estadística por lo que la probabilidad de suceso de dos o más
eventos conjuntos debe de determinarse
Medienanhänge
{kind=link}
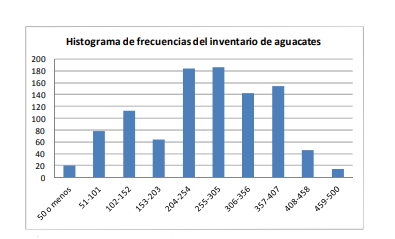{kind=link}
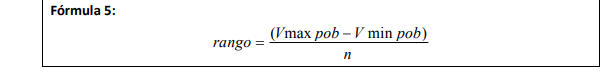{kind=link}
{kind=link}
{kind=link}
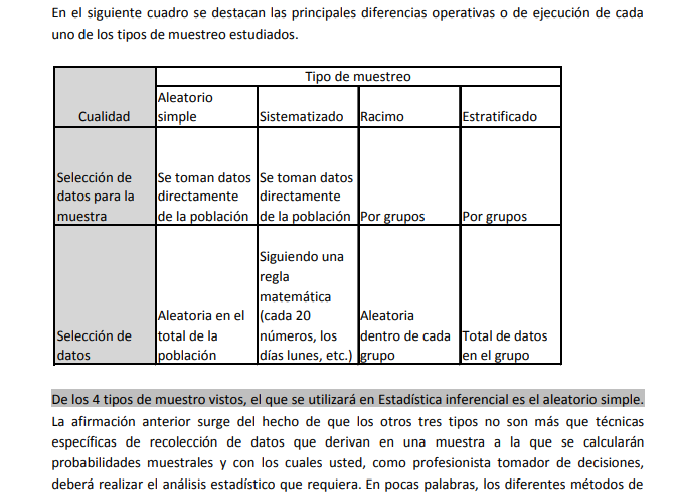{kind=link}
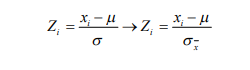{kind=link}
{kind=link}
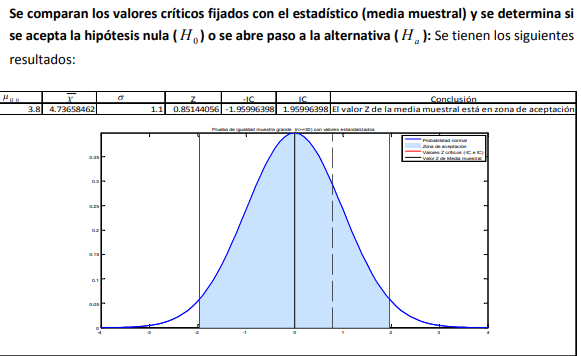{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
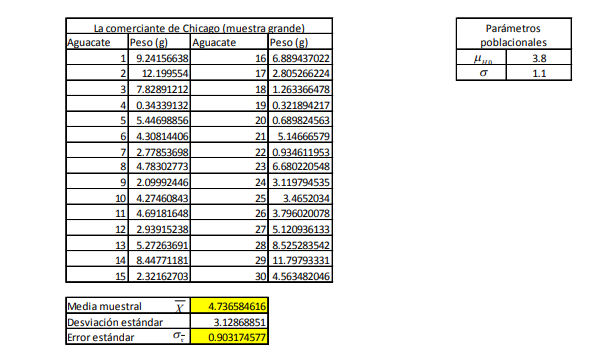{kind=link}
{kind=link}
Möchten Sie kostenlos Ihre eigenen Mindmaps mit GoConqr erstellen? Mehr erfahren.