15283078
Beschreibung
Mindmap von Abhijay Gupta, aktualisiert more than 1 year ago
|
|
Erstellt von Abhijay Gupta
vor etwa 6 Jahre
|
|
Machine Learning
- Prediction
Anmerkungen:
- Most common ML application
- Types
- Regression
Anmerkungen:
- Output y belongs to R, set of real numbers
- Classification
Anmerkungen:
- Output y belongs to a set of specific, possible outcomes e.g. {yes, no}, {0,1,2,....9}
- Regression
- Learning task
Anmerkungen:
- Given value of an input x, make a good prediction of output y, denoted by y hat. x: scalar or vector x = (x1, x2, .... xp) 'p' features y: scalar or vector
- Supervised learning
Anmerkungen:
- Given a training se of N data points, learn a prediction function f:x->y such that given a new x, f can accurately predict the corresponding y.
- Linear model
- Error function
- Hyper-parameters
- Lambda - regularization coeff
- Model selection
- For different values of
hyper-param (HP) - train the
model - compute the perf
in valid set
- Pick val of HP that has
best valid perf
- Compute test perf for
model with chosen value of HP
- For different values of
hyper-param (HP) - train the
model - compute the perf
in valid set
- Model selection
- M - deg of polynomial
- Lambda - regularization coeff
- Overfitting
- Sol 3: Model selection for based on M
- Sol 2: Regularization
- Sol 1: Add more data points
- Checking for it: Use separate test
set
- Sol 3: Model selection for based on M
- Classification
- M1: Linear model
- Closed form solution
- Closed form solution
- M2: k-Nearest Neighbour (k-NN)
Anmerkungen:
- Average of classification values of k closest neighbours
- k - #nearest neighbours
- M1: Linear model
- Error function
- Unsupervised learning
Medienanhänge
{kind=link}
{kind=link}
{kind=link}
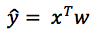{kind=link}
{kind=link}
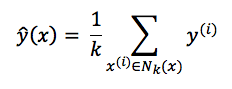{kind=link}
{kind=link}
{kind=link}
Möchten Sie kostenlos Ihre eigenen Mindmaps mit GoConqr erstellen? Mehr erfahren.