18717788
Beschreibung
Mindmap von LUGDY PÁEZ QUINTERO, aktualisiert more than 1 year ago
|
|
Erstellt von LUGDY PÁEZ QUINTERO
vor etwa 5 Jahre
|
|
Medidas estadísticas bivariantes de regresión
Anmerkungen:
- la teoría de la regresión trata de «explicar»1 el comportamiento de una variable, denominada explicada (dependiente o endógena), en función de otra u otras, denominadas explicativas (independientes o exógenas). Se puede establecer una primera clasificación en función del número de variables explicativas: la regresión (y correlación) será simple si únicamente hay una variable explicativa; por el contrario, será múltiple si el número de variables explicativas son varias.
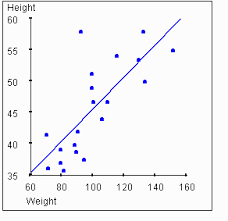
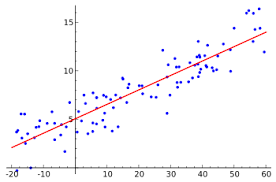
- Regresión lineal simple
Anmerkungen:
- Se basa en estudiar los cambios en una variable, no aleatoria, afectan a una variable aleatoria, en el caso de existir una relación funcional entre ambas variables que puede ser establecida por una expresión lineal, es decir, su representación gráfica es una línea recta. Es decir, se esta en presencia de una regresión lineal simple cuando una variable independiente ejerce influencia sobre otra variable dependiente. Ejemplo: Y = f(x) Cuando la relación funcional entre las variables dependiente (Y) e independiente (X) es una línea recta, se tiene una regresión lineal simple, dada por la ecuación Y = βo + β1X + ε donde: βo : El valor de la ordenada donde la línea de regresión se intersecta al eje Y. β1 : El coeficiente de regresión poblacional (pendiente de la línea recta) ε : El error. Referencia: Montero, J.M. (2007). Regresión y Correlación Simple. Madrid: Paraninfo. (pp 151 – 158). Recuperado de http://go.galegroup.com/ps/i.do?id=GALE%7CCX4052100011&v=2.1&u=unad&it=r&p=GVRL&sw=w&asid=b82c81e98fcc1361e1929abe203c8219 EcuRed contributors. (27 junio 2011). Regresiónlineal. EcuRed. Recuperadode: https://www.ecured.cu/Regresi%C3%B3n_lineal
- Supocisiones de la regresión lineal
Anmerkungen:
- 1. Los valores de la variable independiente X son "fijos". 2. La variable X se mide sin error (se desprecia el error de medición en X) 3. Existen subpoblaciones de valores Y para cada X que están normalmente distribuidos. 4. Las variancias de las subpoblaciones de Y son todas iguales. 5. Todas las medias de las subpoblaciones de Y están sobre la misma recta. 6. Los valores de Y están nomalmente distribuidos y son estadísticamente independientes. Las suposiciones del 3 al 6 equivalen a decir que los errores son aleatorios, que se distribuyen normalmente con media cero y variancia σ².
- Estimación de parámetros
Anmerkungen:
- La función de regresión lineal simple es expresado como: Y = ßo + ß1X + ε (3) la estimación de parámetros consiste en determinar los parámetros ßo y ß1 a partir de los datos muestrales observados; es decir, deben hallarse valores como bo y b1 de la muestra, que represente a ßo y ß1, respectivamente. De la ecuación (3), para un xi determinado, se tiene el correspondiente Yi , y el valor del error εi sería (Yi-ßo-ß1Xi)
- El coeficiente de regressión (b1)
Anmerkungen:
- Está expresado en las mismas unidades de medida de la variable X. e indica el número de unidades que varía Y cuando se produce cambio en una unidad en X (pendiente de la recta de regresión). Si b1=0, se dice que no existe relación lineal entre las dos variables y que estas son independientes.
- Regresión lineal múltiple
Anmerkungen:
- Permite trabajar con una variable a nivel de intervalo o razón, así también se puede comprender la relación de dos o más variables y permitirá relacionar mediante ecuaciones, una variable en relación a otras variables llamándose Regresión múltiple. O sea, la regresión lineal múltiple es cuando dos o más variables independientes influyen sobre una variable dependiente. Ejemplo: Y = f(x, w, z). Referencia: EcuRed contributors. (27 junio 2011). Regresión lineal. EcuRed. Recuperado de: https://www.ecured.cu/Regresi%C3%B3n_lineal
- A partir de ella podemos:
- Identificar que variables independientes (causas) explican una variable dependiente (resultado)
- Comparar y comprobar modelos causales
- Predecir valores de una variable, es decir, a partir de unas características predecir de forma
aproximada un comportamiento o estado
- Identificar que variables independientes (causas) explican una variable dependiente (resultado)
- Condiciones que se deben cumplir para poder aplicar la regresión lineal múltiple
- La variable dependiente (resultado) debe ser ordinal o escalar, es decir, que las categorías de la
variable tengan orden interno o jerarquía, p.ej. nivel de ingresos, peso, número de hijos, justificación
del aborto en una escala de 1-nunca a 10-siempre
- Las variables independientes (causas) deben ser ordinales o escalares
- Hay otras condiciones como: las variables independientes no puede estar altamente correlacionadas
entre sí, las relaciones entre las causas y el resultado deben ser lineales, todas variables deben seguir
la distribución normal y deben tener varianzas iguales.
- La variable dependiente (resultado) debe ser ordinal o escalar, es decir, que las categorías de la
variable tengan orden interno o jerarquía, p.ej. nivel de ingresos, peso, número de hijos, justificación
del aborto en una escala de 1-nunca a 10-siempre
- Pasos:
- 1 – Significación de F-test: si es menor de 0,05 es que el modelo es estadísticamente significativo y por
tanto las variables independientes explican “algo” la variable dependiente, cuánto “algo” es la
R-cuadrado
- 2 – R cuadrado: es cuánto las variables independientes explican la variable dependiente, indica el
porcentaje de la varianza de la variable dependiente explicado por el conjunto de variables
independientes. Cuanto mayor sea la R-cuadrado más explicativo y mejor es el modelo causal. Los dos
siguientes pasos hacen referencia a la influencia de cada una de las variables independientes:
- 3 – Significación de t-test: si es menor de 0,05 es que esa variable independiente se relaciona de forma
significativa con la variable dependiente, por tanto, influye sobre ella, es explicativa
- 4 – Coeficiente beta (β): indica la intensidad y la dirección de la relación entre esa variable
independiente (VI) y la variable dependiente (VD): cuanto más se aleja de 0 más fuerte es la relación
el signo indica la dirección (signo + indica que al aumentar los valores de la VI aumentan los valores
de la VD; signo – indica que al aumentar los valores de la VI, los valores de la VD descienden)
- 1 – Significación de F-test: si es menor de 0,05 es que el modelo es estadísticamente significativo y por
tanto las variables independientes explican “algo” la variable dependiente, cuánto “algo” es la
R-cuadrado
Medienanhänge
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Möchten Sie kostenlos Ihre eigenen Mindmaps mit GoConqr erstellen? Mehr erfahren.