22359102
Beschreibung
Mindmap von Fabian Rubio, aktualisiert more than 1 year ago
|
|
Erstellt von Fabian Rubio
vor mehr als 4 Jahre
|
|
Medidas Estadísticas
Bivariantes de Regresión
- Esta conformada por
- regresión lineal simple
- Uno de los aspectos más relevantes de la Estadística es el
análisis de la relación o dependencia entre variables.
Frecuentemente resulta de interés conocer el efecto que
una o varias variables pueden causar sobre otra, e incluso
predecir en mayor o menor grado valores en una variable a
partir de otra
- El modelo de regresión lineal
- La estructura del modelo de regresión lineal es la
siguiente:
- En esta expresión estamos admitiendo que todos los factores o causas que influyen
en la variable respuesta Y pueden dividirse en dos grupos: el primero contiene a una
variable explicativa X y el segundo incluye un conjunto amplio de factores no
controlados que englobaremos bajo el nombre de perturbación o error aleatorio, ε,
que provoca que la dependencia entre las variables dependiente e independiente no
sea perfecta, sino que esté sujeta a incertidumbre
- En esta expresión estamos admitiendo que todos los factores o causas que influyen
en la variable respuesta Y pueden dividirse en dos grupos: el primero contiene a una
variable explicativa X y el segundo incluye un conjunto amplio de factores no
controlados que englobaremos bajo el nombre de perturbación o error aleatorio, ε,
que provoca que la dependencia entre las variables dependiente e independiente no
sea perfecta, sino que esté sujeta a incertidumbre
- La estructura del modelo de regresión lineal es la
siguiente:
- Estimación de los parámetros del modelo
- Partimos de una muestra de valores de X e Y medidos sobre n individuos: (x1, y1),(x2,
y2), ...,(xn,yn), y queremos estimar valores en Y según el modelo ˆ Y = β0 + β1X, donde
β0 y β1 son por el momento desconocidos. Debemos encontrar entonces de entre todas
las rectas la que mejor se ajuste a los datos observados, es decir, buscamos aquellos
valores de β0 y β1 que hagan mínimos los errores de estimación. Para un valor xi, el
modelo estima un valor en Y igual a ˆ yi = β0 + β1xi y el valor observado en Y es igual a
yi, con lo cual el error de estimación en ese caso vendría dado por ei = yi − ˆ yi = yi − (β0
+ β1xi). Entonces tomaremos como estimaciones de β0 y β1 , que notamos por ˆ β0 y ˆ
β1, aquellos valores que hagan mínima la suma de los errores al cuadrado, que viene
dada por:
- Partimos de una muestra de valores de X e Y medidos sobre n individuos: (x1, y1),(x2,
y2), ...,(xn,yn), y queremos estimar valores en Y según el modelo ˆ Y = β0 + β1X, donde
β0 y β1 son por el momento desconocidos. Debemos encontrar entonces de entre todas
las rectas la que mejor se ajuste a los datos observados, es decir, buscamos aquellos
valores de β0 y β1 que hagan mínimos los errores de estimación. Para un valor xi, el
modelo estima un valor en Y igual a ˆ yi = β0 + β1xi y el valor observado en Y es igual a
yi, con lo cual el error de estimación en ese caso vendría dado por ei = yi − ˆ yi = yi − (β0
+ β1xi). Entonces tomaremos como estimaciones de β0 y β1 , que notamos por ˆ β0 y ˆ
β1, aquellos valores que hagan mínima la suma de los errores al cuadrado, que viene
dada por:
- Inferencias sobre el coeficiente de
regresión
- Observábamos que los estimadores ˆ β0 y ˆ β1 dependen de
la muestra seleccionada, por lo tanto son variables aleatorias
y presentarán una distribución de probabilidad. Estas
distribuciones de probabilidad de los estimadores pueden
utilizarse para construir intervalos de confianza o contrastes
sobre los parámetros del modelo de regresión.
- Observábamos que los estimadores ˆ β0 y ˆ β1 dependen de
la muestra seleccionada, por lo tanto son variables aleatorias
y presentarán una distribución de probabilidad. Estas
distribuciones de probabilidad de los estimadores pueden
utilizarse para construir intervalos de confianza o contrastes
sobre los parámetros del modelo de regresión.
- El coeficiente de correlación lineal y el
coeficiente de determinación
- Nuestro objetivo en adelante será medir la bondad del ajuste
de la recta de regresión a los datos observados y cuantificar al
mismo tiempo el grado de asociación lineal existente entre
las variables en cuestión. A mejor ajuste, mejores serán las
predicciones realizadas con el modelo
- El coeficiente de correlación lineal
- para medir la asociación lineal entre dos variables X e Y se
utiliza una medida adimensional denominada coeficiente
de correlación lineal, dado por
- El coeficiente de correlación lineal toma valores entre -1 y 1 y su
interpretación es la siguiente: • Un valor cercano o igual a 0 indica
respectivamente poca o ninguna relación lineal entre las variables.
• Cuanto más se acerque en valor absoluto a 1 mayor será el grado
de asociación lineal entre las variables. Un coeficiente igual a 1 en
valor absoluto indica una dependencia lineal exacta entre las
variables. • Un coeficiente positivo indica asociación lineal positiva,
es decir, tienden a variar en el mismo sentido. • Un coeficiente
negativo indica asociación lineal negativa, es decir, tienden a variar
en sentido opuesto. Nótese que si β1 = 0 entonces r = 0 , en cuyo
caso hay ausencia de linealidad. Por lo tanto, contrastar si el
coeficiente de correlación lineal es significativamente distinto de 0
sería equivalente a contrastar si β1 es significativamente distinto
de cero, contraste que ya vimos en la sección anterior.
- El coeficiente de correlación lineal toma valores entre -1 y 1 y su
interpretación es la siguiente: • Un valor cercano o igual a 0 indica
respectivamente poca o ninguna relación lineal entre las variables.
• Cuanto más se acerque en valor absoluto a 1 mayor será el grado
de asociación lineal entre las variables. Un coeficiente igual a 1 en
valor absoluto indica una dependencia lineal exacta entre las
variables. • Un coeficiente positivo indica asociación lineal positiva,
es decir, tienden a variar en el mismo sentido. • Un coeficiente
negativo indica asociación lineal negativa, es decir, tienden a variar
en sentido opuesto. Nótese que si β1 = 0 entonces r = 0 , en cuyo
caso hay ausencia de linealidad. Por lo tanto, contrastar si el
coeficiente de correlación lineal es significativamente distinto de 0
sería equivalente a contrastar si β1 es significativamente distinto
de cero, contraste que ya vimos en la sección anterior.
- para medir la asociación lineal entre dos variables X e Y se
utiliza una medida adimensional denominada coeficiente
de correlación lineal, dado por
- El coeficiente de determinación
- el coeficiente de correlación lineal puede interpretarse como una
medida de la bondad del ajuste del modelo lineal, concretamente, un
valor del coeficiente igual a 1 o -1 indica dependencia lineal exacta, en
cuyo caso el ajuste es perfecto. No obstante, para cuantificar la
bondad del ajuste de un modelo, lineal o no, se utiliza una medida
que se denomina coeficiente de determinación lineal R2, que es la
proporción de variabilidad de la variable Y que queda explicada por el
modelo de entre toda la presente, y cuya expresión es:
- que en modelo de regresión lineal coincide con el cuadrado del
coeficiente de correlación lineal: R2 = r2. El coeficiente de
determinación toma valores entre 0 y 1, y cuanto más se aproxime a
1 mejor será el ajuste y por lo tanto mayor la fiabilidad de las
predicciones que con él realicemos. Nótese que si el coeficiente de
correlación lineal r es igual a 1 o -1 entonces R2 = 1 y por lo tanto el
ajuste lineal es perfecto
- que en modelo de regresión lineal coincide con el cuadrado del
coeficiente de correlación lineal: R2 = r2. El coeficiente de
determinación toma valores entre 0 y 1, y cuanto más se aproxime a
1 mejor será el ajuste y por lo tanto mayor la fiabilidad de las
predicciones que con él realicemos. Nótese que si el coeficiente de
correlación lineal r es igual a 1 o -1 entonces R2 = 1 y por lo tanto el
ajuste lineal es perfecto
- el coeficiente de correlación lineal puede interpretarse como una
medida de la bondad del ajuste del modelo lineal, concretamente, un
valor del coeficiente igual a 1 o -1 indica dependencia lineal exacta, en
cuyo caso el ajuste es perfecto. No obstante, para cuantificar la
bondad del ajuste de un modelo, lineal o no, se utiliza una medida
que se denomina coeficiente de determinación lineal R2, que es la
proporción de variabilidad de la variable Y que queda explicada por el
modelo de entre toda la presente, y cuya expresión es:
- Nuestro objetivo en adelante será medir la bondad del ajuste
de la recta de regresión a los datos observados y cuantificar al
mismo tiempo el grado de asociación lineal existente entre
las variables en cuestión. A mejor ajuste, mejores serán las
predicciones realizadas con el modelo
- El modelo de regresión lineal
- Uno de los aspectos más relevantes de la Estadística es el
análisis de la relación o dependencia entre variables.
Frecuentemente resulta de interés conocer el efecto que
una o varias variables pueden causar sobre otra, e incluso
predecir en mayor o menor grado valores en una variable a
partir de otra
- regresión múltiple
- El análisis de regresión múltiple permite añadir
diversas variables, de modo que la ecuación refleje
los valores de un cierto número de variables de
predicción, no una sola. El objetivo de esto es
mejorar las predicciones de la variable de criterio.
- Aplicaciones de la
regresión múltiple.
- Es cierto que la regresión múltiple se utiliza
para la predicción de respuestas a partir de
variables explicativas. Pero no es ésta
realmente la aplicación que se le suele dar en
investigación. Los usos que con mayor
frecuencia encontraremos en las publicaciones
son los siguientes:
- • Identificación de variables explicativas.
- • Detección de interacciones entre
variables independientes que afectan a
la variable respuesta
- • Identificación de variables confusoras
- • Identificación de variables explicativas.
- Es cierto que la regresión múltiple se utiliza
para la predicción de respuestas a partir de
variables explicativas. Pero no es ésta
realmente la aplicación que se le suele dar en
investigación. Los usos que con mayor
frecuencia encontraremos en las publicaciones
son los siguientes:
- Requisitos y
limitaciones
- Linealidad
- Normalidad y equidistribución de los residuos
- • Número de variables independientes:
- Colinealidad
- Observaciones anómalas
- Linealidad
- Variables numéricas e indicadoras
(dummy)
- Un modelo de regresión lineal
tiene el aspecto
- Está claro que para ajustar el modelo la variable
respuesta debe ser numérica. Sin embargo, aunque
pueda parecer extraño no tienen por qué serlo las
variables explicativas. Aunque requiere un artificio,
podemos utilizar predictores categóricos mediante la
introducción de variables indicadoras (también
denominadas mudas o dummy)
- Está claro que para ajustar el modelo la variable
respuesta debe ser numérica. Sin embargo, aunque
pueda parecer extraño no tienen por qué serlo las
variables explicativas. Aunque requiere un artificio,
podemos utilizar predictores categóricos mediante la
introducción de variables indicadoras (también
denominadas mudas o dummy)
- Un modelo de regresión lineal
tiene el aspecto
- Interpretación de los resultados
- La significación del modelo de regresión: La hipótesis nula es
que la variable respuesta no está influenciada por las variables
independientes. Dicho de otro modo, la variabilidad observada
en las respuestas son causadas por el azar, sin influencia de las
variables independientes
- Los coeficientes: Los programas estadísticos ofrecen una
estimación de los mismos, junto a un error típico de la
estimación, un valor de significación, o mejor aún, un intervalo
de confianza.
- • La bondad del ajuste: Hay un término denominado R cuadrado, que se
interpreta del siguiente modo. La variable respuesta presenta cierta
variabilidad (incertidumbre), pero cuando se conoce el valor de las
variables independientes, dicha incertidumbre disminuye
- La matriz de correlaciones: Nos ayudan a identificar correlaciones
lineales entre pares de variables. Encontrar correlaciones lineales entre
la variable dependiente y cualquiera de las independientes es siempre
de interés
- La significación del modelo de regresión: La hipótesis nula es
que la variable respuesta no está influenciada por las variables
independientes. Dicho de otro modo, la variabilidad observada
en las respuestas son causadas por el azar, sin influencia de las
variables independientes
- Variables confusoras
- Dos variables o más variables están confundidas cuando sus efectos
sobre la variable dependiente no pueden ser separados. Dicho de
otra forma, una variable es confusora cuando estando relacionada
con alguna variable independiente, a su vez afecta a la dependiente.
- Cuando se identifica una variable que está confundida con alguna de las
variables independientes significativa, es necesario dejarla formar parte
del modelo, tenga o no mucha significación. Las variables confusoras no
pueden ser ignoradas
- Cuando se identifica una variable que está confundida con alguna de las
variables independientes significativa, es necesario dejarla formar parte
del modelo, tenga o no mucha significación. Las variables confusoras no
pueden ser ignoradas
- Dos variables o más variables están confundidas cuando sus efectos
sobre la variable dependiente no pueden ser separados. Dicho de
otra forma, una variable es confusora cuando estando relacionada
con alguna variable independiente, a su vez afecta a la dependiente.
- Aplicaciones de la
regresión múltiple.
- El análisis de regresión múltiple permite añadir
diversas variables, de modo que la ecuación refleje
los valores de un cierto número de variables de
predicción, no una sola. El objetivo de esto es
mejorar las predicciones de la variable de criterio.
- regresión lineal simple
Medienanhänge
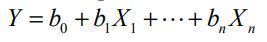{kind=link}
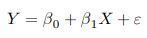{kind=link}
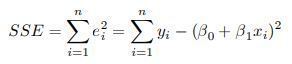{kind=link}
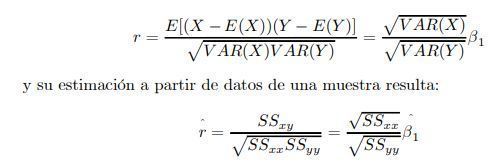{kind=link}
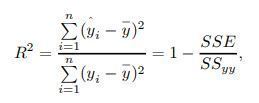{kind=link}
Möchten Sie kostenlos Ihre eigenen Mindmaps mit GoConqr erstellen? Mehr erfahren.