11805841
Beschreibung
Karteikarten von Christian Höppner, aktualisiert more than 1 year ago
|
|
Erstellt von Christian Höppner
vor mehr als 6 Jahre
|
|
| Frage | Antworten |
| Hypothese | Sie sind weniger umfangreich als Theorien. Sie stellen Vermutungen über einen Sachverhalt an. Sie lassen sich überprüfen. Hypothesen sind nie beweisbar/bestätigbar, man kann höchstens zeigen, dass sie falsch sind. |
| Induktionsproblematik | Es ist nicht möglich die Richtigkeit einer Theorie zu beweisen. Es ist aber zu beweisen das die Theorie falsch ist. |
| Falsifikationsprinzip | Wissenschaftliche Aussagen sollen daher nach Sir Popper empirisch wiederlegbar sein. |
| -Schlusstechnik- Induktion | Generalisierung von in der Realität beobachteten Regelmäßigkeiten. |
| -Schlusstechnik- Deduktion | Ableitung von Aussagen aus anderen (allgemeinen) Aussagen mit Hilfe logischer Regeln. Häufig. Hypothesenprüfung |
| -Schlusstechnik- Abduktion | Verknüpfung von Einzelbeobachtungen und erkennen von Regeln. |
| Gütekriterien für Forschung | - Ethische Aspekte: Können negative Folgen auftreten? - Transparenz: Das Vorgehen ist klar dokumentiert und nachprüfbar (reproduzierbar)? - Objektivität: Sind die Ergebnisse unabhängig von der Person? - Interne Validität: Keine anderen Erklärungen für die Ergebnisse? - Externe Validität: Übertragbarkeit der Ergebnisse? |
| Quantitative Methoden | - Messung und nummerische Beschreibung der Wirklichkeit - Allgemeingültige Gesetze für die Grundgesamtheit |
| Qualitative Methoden | - Verbalisierung der Erfahrungswirklichkeit - Beschreibung der Erfahrung |
| Latente Variablen/Konstrukte | können nicht direkt gemessen werden müssen erst operationalisiert werden (z.B. Skalen zuweisen) Beispiel: Motivation |
| Manifeste Variablen | können direkt gemessen werden Beispiel: Größe, Gewicht, Lieferzeit |
| Gütekriterien einer Messung | Genauigkeit, d.h. Exaktheit einer Messung Objektivität, d.h. Messung unabhängig vom Messenden (egal welche Person misst) Reliabilität, d.h. Zuverlässigkeit einer Messung (egal womit und wann gemessen wird) Validität, d.h. wird das gemessen, was gemessen werden soll. |
| Kategoriales Skalenniveu | 1. Nominal: Merkmalausprägungen können unterschieden werde. (Bspl. Geschlecht) 2. Ordinal: Merkmalausprägungen können unterschieden und in eine Reihenfolge gebracht werden. Die Abstände zwischen den Werten können nicht direkt verglichen o. interpretiert werden. (Bspl. Bildungsabschlüsse) |
| numerische/metrische Skalenniveaus | Verhältnisskala: Nullpunkt gegeben (Gewicht) Intervallskala: Nullpunkt gesetzt (Zeitrechnung, Jahr 0) stetig: beliebige Zwischenwerte im Intervall sind möglich (Größe) diskret: höchstens abzählbar viele Werte sind möglich (Anzahl Kinder) |
| Stichproben | Stichproben sind eine Teilmenge der Population/Grundgesamtheit |
| Unabhängige Variable | (exogen, erklärend, UV): Wert hängt von keiner anderen Variable ab (“x”). |
| Abhängige Variable | (endogen, erklärt, AV): Wert hängt von der/den unabhängige(n) Variable ab (“y”). |
| Kovariablen/Störvariablen | Variablen, deren Wert ebenfalls auf die abhängige Variable einwirkt und/oder den Zusammenhang zwischen unabhängigen und abhängigen Variablen beeinflusst (“z”). |
| Population | Population: die Menge über die eine Aussage getroffen werden soll: die ganze Suppe im Suppentopf. |
| Stichprobe | Stichprobe: der Teilmenge der Population, die zur Analyse ausgewählt wurde: der Löffel voll Suppe. |
| Stichprobenverfahren | Stichprobenverfahren: der Prozess, mit dem die Teilmenge ausgewählt wurde. Z. B. zufällig: der Auswahlprozess, wo und wie der Löffel aus dem Suppentopf gefüllt wurde. |
| Repräsentative Stichprobe | Repräsentative Stichprobe: Ist die Verteilung der Eigenschaften der Stichprobe ähnlich der der Population? Wenn der Löffel anders schmeckt als die Suppe war der Löffel nicht repräsentativ. |
| Bias/ Verzerrung | Bias/ Verzerrung: Ein Teil der Population wird bevorzugt: Nur Fleischbällchen auf dem Löffel. |
| Generalisierbarkeit | Generalisierbarkeit: Inwieweit kann von der Stichprobe auf die Grundgesamtheit geschlossen werden? Wenn wir gut umgerührt haben sollten die Gewürze etc. auf dem Löffel ähnlich der im Topf sein und wir können vom Löffel auf den Topf schließen. |
| Parameter | Parameter: Wert der Grundgesamtheit, an dem wir interessiert sind: z. B. Temperatur der Suppe insgesamt. |
| Statistik | Statistik: Wert der auf Basis der Stichprobe berechnet wird: z. B. Temperatur der Suppe auf dem Löffel. |
| Zufallsstichprobe | Bei einer (einfachen) Zufallsstichprobe hat jeder Merkmalsträger die gleiche Wahrscheinlichkeit, Teil der Stichprobe zu sein. |
| geschichtete Stichproben | Bei geschichtete Stichproben setzen sich die Schichten aus ähnlichen Beobachtungen zusammen (z. B. Alter, Geschlecht). Es wird eine einfache, zufällige Stichprobe aus jeder Schicht genommen. |
| Zufällige Stichproben vs. Gelegenheitsstichproben | Zufällige Stichproben erlauben einen Schluss auf die Grundgesamtheit (generalisierbar). Gelegenheitsstichproben können verzerrt sein. |
| Beobachtungsstudien | Bei Beobachtungsstudien werden Daten gesammelt, ohne die Entstehung der Daten zu beeinflussen (keine unmittelbaren Kausalaussagen möglich). |
| Experiment | Bei einem Experiment wird der Wert der unabhängigen Variable systematisch variiert und die Variation der abhängigen Variable gemessen. - Um Verzerrungen durch Kovariablen vermeiden, erfolgt die Zuordnung zu den Experimentalkonditionen zufällig (randomisiert). - Durch wiederholte Messung kann der Effekt der Experimentalkonditionen geschätzt werden: hohe interne Validität. Bei Quasi-Experimenten ist die Zuordnung nicht randomisiert: geringe interne Validität |
| Laborexperiment vs. Feldexperiment | Bei Laborexperimenten erfolgt die Untersuchung innerhalb einer speziellen Versuchsanordnung (geringe externe Validität). Bei einem Feldexperimenten erfolgt die Untersuchung im natürlichen Umfeld (hohe externe Validität). |
| Grafische Verfahren der Datenanalyse | Balkendiagramm Histogramm Boxplot Streudiagramm/Scatterplot Mosaicplot Liniendiagramm |
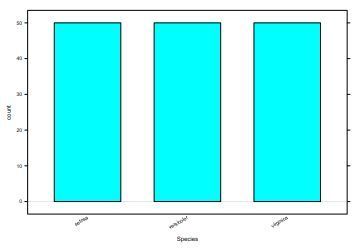
| Balkendiagramm | absoluten oder relativen Häufigkeiten von kategorialen oder metrisch diskreten Variablen. |
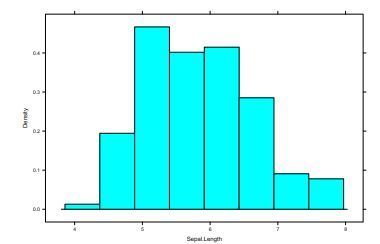
| Histogramm | Häufigkeit von gruppierten Merkmalsausprägungen (metrisch) |
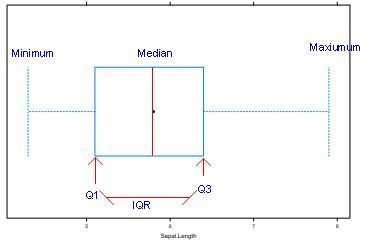
| Boxplot | Visualisierung von Median, oberem und unterem Quartil, Minimum und Maximum, Ausreißer. Der Mittelwert wird im Boxsplot nicht abgebildet. |
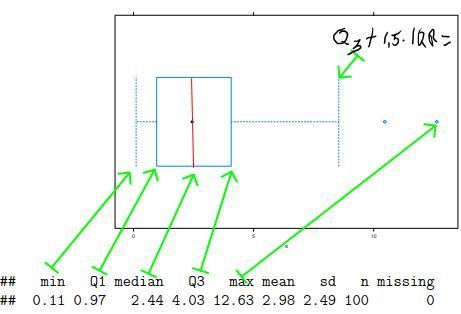
| Anatomie Boxplot | Die untere Linie der Box ist das untere Quartil (Q1). Die obere Linie der Box ist das obere Quartil (Q3). Der Punkt in der Box (häufig auch eine Linie) ist der Median. Sollten Punkte außerhalb der Antennen sein, sind dies mögliche Ausreißer. Maximale Reichweite der Antennen: 1,5 · IQR vom oberen bzw. unteren Quartil. Sollte das Maximum bzw. das Minimum der Daten kleiner bzw. größer sein wird dies genommen. |
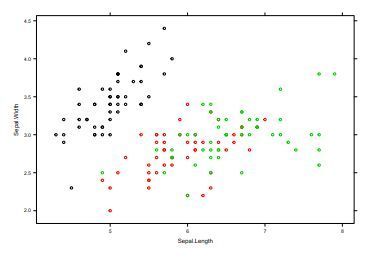
| Streudiagramm/ Scatterplot | Darstellung der Merkmalsausprägungen von zwei metrischen Merkmalen als Punkte |
| Mosaicplot | Darstellung der Merkmalsausprägungen zweier nominaler Merkmale |
| Liniendiagramm | Verlauf der Merkmalsausprägung eines Merkmals |
| Lagemaße | 1. Minimum bzw. Maximum: Kleinste bzw. größte Merkmalsausprägung 2. Modus/Modalwert: Häufigste Merkmalsausprägung. 3. Median/Zentralwert: Merkmalsausprägung, die bei (aufsteigend) sortierten Beobachtungen in der Mitte liegt. 4. Arithmetischer Mittelwert (engl. mean): Summe aller Werte geteilt durch die Anzahl 5. Quantil: Das p-Quantil ist der Wert, für den gilt, dass er von p Prozent der Werte nicht überschritten wird. |
| Streuungsmaße | Varianz : Maß für die durchschnittliche quadratische Abweichung zum Mittelwert Standardabweichung (engl. standard deviation): Quadratwurzel der Varianz Interquartilsabstand (engl. interquartile range, IQR): Oberes Quartil |
| Struktur der Daten in R | |
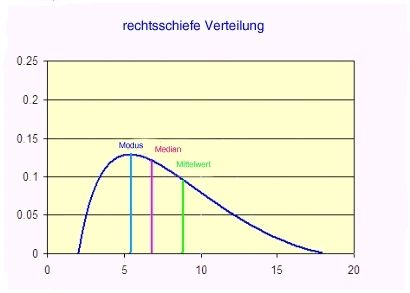
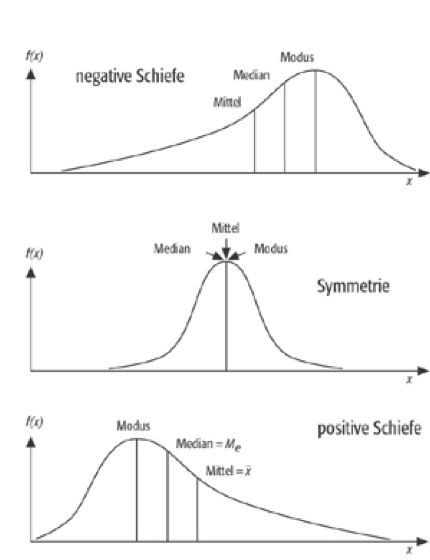
| -Verteilung- rechtsschiefe | rechtsschiefen (linkssteilen) Verteilungen sind mehr Werte im unteren Wertebereich |
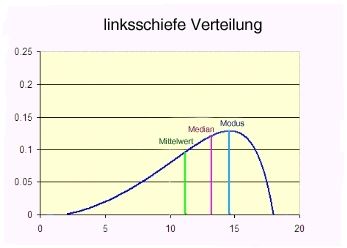
| -Verteilung- linksschief | bei linksschiefen (rechtssteilen) sind mehr Werte im oberen Wertebereich |
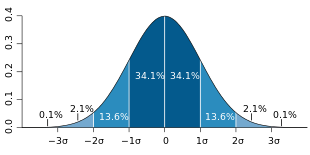
| Verteilung | Bei symmetrische Verteilungen verteilen sich die Daten symmetrisch um eine zentrale Lage. Bei mehrgipfligen Verteilungen gibt es mehr als nur ein Zentrum, um das die Werte streuen. |
| Normalverteilung | |
| -Kovariation- Kovarianz | |
| -Kovariation- Korrelationskoeffizient | |
| Hypothesentest Nullhypothese und Alternativhypothese | IInhaltliche Hypothesen und Modelle werden mathematisch/statistisch operationalisiert. Dabei ist die Nullhypothese H0 i. d. R. die, dass es keinen Zusammenhang, keinen Unterschied gibt, die Alternativhypothese ( HA Forschungshypothese) ist das logische Gegenteil der Nullhypothese. Die Rollen von H0 und HA können nicht vertauscht werden. |
| Hypothesentest Population | Hypothesen beziehen sich auf die Population/ Grundgesamtheit, d. h. p, µ, β . (Nicht auf die Stichprobe) Nullhypothesen können einseitig, gerichtet ( ≤ , ≥ ) oder zweiseitig, ungerichtet ( = ) sein. |
| Hypothesentest Teststatistik | Anhand einer geeigneten Teststatistik werden die Stichprobendaten zusammengefasst. Ist die Wahrscheinlichkeit der Teststatistik unter H0 klein, fällt der Wert der Teststatistik in den Ablehnungsbereich und wird H0 wird verworfen, andernfalls nicht. If the "P" is Low then the Ho Must Go! |
| Hypothesentest Siginifikanzniveau | Das Signifikanzniveau α eines Tests gibt die maximal zugebilligte Irrtumswahrscheinlichkeit dafür an, H0 zu verwerfen, obwohl H0 gilt. üblich: α = 5%, auch 1% oder (selten) 10% möglich |
| p-Wert | berechnet sich aus der (Rand-)Wahrscheinlichkeit der Teststatistik unter H0 Gilt p-Wert ≤ α (Signifikanzniveau), so wird H0 verworfen Der p-Wert sagt nicht aus, wie wahrscheinlich H0 bei den vorliegenden Daten (Teststatistik) ist , sondern wie wahrscheinlich die vorliegende Teststatistik unter H0 sind. Der p-Wert sagt nicht, wie relevant ein Ergebnis ist. Keine inhaltliche Entscheidung sollte rein auf Basis des p-Wertes getroffen werden. Vor der Testentscheidung immer eine explorative Datenanalyse durchführen. |
| Fehlerarten | Fehler 1. Art , Alpha-Fehler: Die Nullhypothese wird verworfen, obwohl sie gilt. Fehler 2. Art , Beta-Fehler: Die Nullhypothese wird nicht verworfen, obwohl die Alternativhypothese gilt. |
| Punktschätzer | ein unbekannter Parameter/ Wert der Population anhand eines Wertes der Stichprobe geschätzt Standardfehler beschreibt die Streuung (Standardabweichung) eines Schätzwertes |
| Konfidenzintervall | Ein Konfidenzintervall gibt einem Bereich an, der den wahren, unbekannten Wert der Population mit einer gegebenen Sicherheit (z. B. 95% = 100% − 5% ) überdeckt Je größer die Sicherheit (z. B. 99% statt 95% ), desto breiter ist das Intervall Je größer der der Stichprobenumfang, desto kleiner das Konfidenzintervall (untersonst gleichen Umständen): der Standardfehler se fällt mit n . |
| Bootstrap | ... |
| Testverfahren Kategoriale Daten | Test des Anteilswertes : Anteil eines (binären) Merkmals in der Population. Chi-Quadrat Unabhängigkeitstest : Zusammenhang/ Unabhängigkeit zweier nominaler Merkmale. Hypothese H0 : Die Merkmale sind unabhängig, es gibt keinen Zusammenhang HA : Die Merkmale sind nicht unabhängig, es gibt einen Zusammenhang. |
| Ergebnis Test des Anteilswertes | |
| Chi-Quadrat Test: χ2 -Test | ITest des Zusammenhangs zweier kategorialer (nominaler) Variablen. Dabei werden die beobachteten Häufigkeiten O der Merkmalsausprägungskombinationen mit den unter Unabhängigkeit erwarteten Werten E verglichen |
| Chi-Quadrat Test Auswertung in R | |
| Einstichproben t-Test | Testet den Mittelwert eines Merkmals einer Stichprobe mit einem hypothetisch richtigen Mittelwert der Population. t.test() |
| Gepaarter t-Test/ t-Test für abhängige Stichproben | Testet die Differenz der Mittelwerte zweier Merkmale ( A, B ) einer Stichprobe mit einer hypothetisch richtigen Differenz in der Population |
| Zweistichproben t-Test/ t-Test für unabhängige Stichproben | Testet die Mittelwerte eines Merkmals zweier Stichproben 1 , 2 in der Population |
| Varianzanalyse (Anova) | Testet die Gleicheit der Mittelwerte zweier oder mehr Stichproben (Merkmale) in der Population: H0 : µ1 = µ2 = . . . = µK vs. HA : mindestens ein Mittelwert unterscheidet sich ( µi = µj ). aov() |
| Varianzanalyse (Anova) | Vergleich des Lagemaßes µ bei zwei oder mehr Stichproben. Ein- oder mehrfaktoriell möglich, bei mehr als einem Einfluss auch Wechselwirkungen. - Nullhypothese: Lagemaß µ für alle Gruppen gleich. - Die Gesamtstreung ( SST ) wird zerlegt in die Streuung zwischen den Stichproben /Gruppen ( SSG ) und die Streuung innerhalb der Stichproben /Gruppen ( SSE ): SST = SSG + SSE . Ist das Verhältnis der Streuung zwischen den Gruppen im Verhältnis zur Streuung innerhalb der Gruppengroß ( F ), so ist dies unter der Nullhypothese unwahrscheinlich. - Voraussetzung: Daten innerhalb der Stichproben/ Gruppen unabhängig, identisch, normalverteilt |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
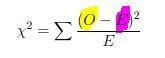{kind=link}
{kind=link}
{kind=link}
Möchten Sie mit GoConqr kostenlos Ihre eigenen Karteikarten erstellen? Mehr erfahren.