3224976
Beschreibung

Karteikarten von flor romero, aktualisiert more than 1 year ago
|
|
Erstellt von flor romero
vor mehr als 9 Jahre
|
|
| Frage | Antworten |
| BIG DATA GLOSARIO FLOR ROMERO | |
| 1. BIG DATA | 2. Conjuntos de datos cuyo tamaño está más allá de la capacidad de las herramientas de tratamiento de bases de datos de uso común, tanto para captura como para Gestión y procesamiento de los datos en un tiempo aceptable. Actualmente los volúmenes de datos, son medidos en terabytes a petabytes, en transacciones diarias sobre temas individuales. La solución pasa por el uso de procesamiento paralelo masivo, tanto para el análisis y obtención de estadísticas como para la visualización de los datos para su mejor comprensión. No hay un valor exacto que indique cuando el volumen de datos puede considerarse grande, depende de las capacidades de almacenamiento y dificultad de tratamiento de cada organización. |
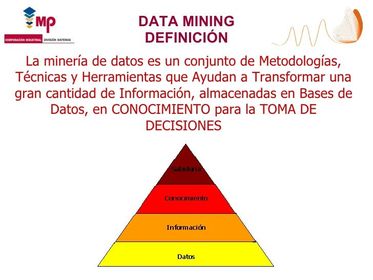
| 2. DATA MINING | prospección de datos, explotación, técnica de análisis de datos para la búsqueda de tendencias y patrones ocultos en los datos. |
| 3. DATA SCIENCE | Ciencia de datos- Disciplina centrada en la extracción de conocimiento a partir de datos. Emplea técnicas y teorías procedentes de muchos campos dentro de las matemáticas, estadística y tecnología de la información, incluyendo el procesamiento de señales, los modelos de probabilidad, aprendizaje automático, aprendizaje estadístico, programación de computadoras, ingeniería de datos, reconocimiento de patrones y aprendizaje, visualización, análisis predictivo, almacenamiento de datos y computación de alto rendimiento. |
| 4. BIG DATA ANALYTICS | es la práctica de aplicar la analítica modernas herramientas de software a través de datos de todo tipo, incluyendo los datos no estructurados, semi-estructurados, y estructurado; así como en tiempo real / streaming y por lotes. El propósito de Big Data Analytics es descubrir ideas e irregularidades, y para mejorar la comprensión del rendimiento del negocio y el comportamiento del cliente. Estos conocimientos basada en análisis se pueden utilizar para lograr resultados de negocio, mejorar la ventaja competitiva, mejorar las decisiones financieras y desarrollar proyecciones más concisos. |
| 5. CLUSTER | Conjunto de servidores (o nodos) que permiten garantizar la continuidad del servicio y distribuir la carga de procesamiento/red. |
| 6. HADOOP | conjunto de programas y procedimientos de código abierto para usar o modificar, es la "columna vertebral" de sus operaciones de datos grandes. |
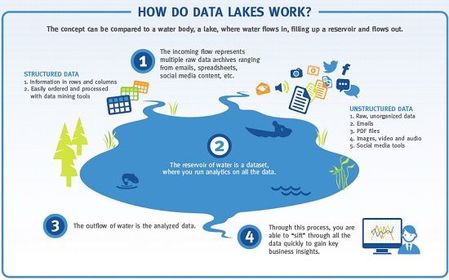
| 7. DATA LAKE | Un lago de datos es el almacenamiento de escalabilidad horizontal para su Big Data. Permite grandes volúmenes de datos para permitir el análisis en su lugar. Con un lago de datos, se puede mantener más datos y mantenerla por más tiempo, por lo que es esencial para los verdaderos Hadoop entornos. Un Dell EMC Isilon Lago de datos equipado con procesadores Intel ® es la manera perfecta para empezar. |
| 8. DATA LAKE EXTENSION | Las extensiones para el Lago de datos ofrecen grandes volúmenes de datos y las opciones de análisis de casos de uso transaccionales como Splunk, MongoDB y Cassandra en tiempo real |
| 9. ROOT | es la palabra inglesa para «raíz». Tener acceso «root» significa tener acceso a la raíz del servidor y tener todos los permisos de administración sin restricciones. También implica que es responsable de todas las acciones que se realicen con esos permisos en el servidor. |
| 13. RACK VIRTUAL | Tecnología de OVH ( Servidores Privados Virtuales (VPS) OVH) que permite reunir virtualmente varios servidores (independientemente de su número y su localización física en nuestros datacenters) y conectarlos a un switch virtual dentro de una misma red privada. De este modo, sus servidores pueden comunicarse de manera privada y segura entre ellos (dentro de una VLAN dedicada). |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Möchten Sie mit GoConqr kostenlos Ihre eigenen Karteikarten erstellen? Mehr erfahren.