4280368
Betriebssystem Zusammenfassung
Resumen del Recurso
Diapositiva 1
Überblick Betriebsysteme
- MS DOS (Fa. Microsoft)- Windows (Fa. Microsoft): aufgesetzt auf DOS, mehrere Anwendungen gleichz. aktiv, - Windows NT (Fa. Microsoft): aufbauend auf Dos, Win 2000, XP, Vista, 7, 8, 10- Unix (1965, Fa. AT&T, Ken Thompsen, Dennis Ritchie): unabhänige Weiterentwicklung an Unis/Firmen-QNX (1982, Fa. QNX Software Systems): für eingebettete Systeme, Echtzeit-BSmit Mikrokernel-OS/360: Stapel-BS, wurde durch VM/370 übernommen-VM/370(1972, Fa. IBM): für 370er-Architektur-Maschinen, 'Virtual Maschine Monitor'-Mac-OS (1976, Fa. Apple, Steve Jobs, Steve Woznijak, Ron Wayne): basiert auf UNIX- IOS (Fa. Apple): Downsize von MacOS- Android (Fa. Google, Andy Rubin): Downsize von Linux- Windows Phone (Fa. Microsoft)
Diapositiva 2
Zentrale Begriffe und Definition
Betriebssystem = die Programme eines digitalen Rechensystems, die zusammen mit den Eigenschaften dieser Rechenanlage die Basis der möglichen Betriebsarten bilden und die insbesondere die Abwicklung von Programmen steuern und überwachen
Diapositiva 3
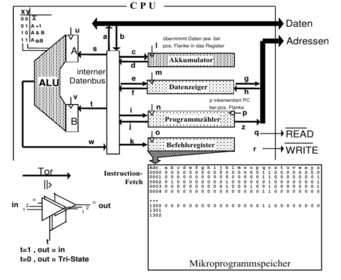
Hardware
- CPU: central processing unit: - ALU - Datenbus - Akkumulator: übernimmt Daten jew. bei pos. Flanke in das Register - Datenzeiger: - Programmzähler: - Befehlsregister: - ROM: read only memory: Lesespeicher- RAM: random access memory: Schreibe-/Lesespeicher
{kind=link}
Diapositiva 4
{kind=link}
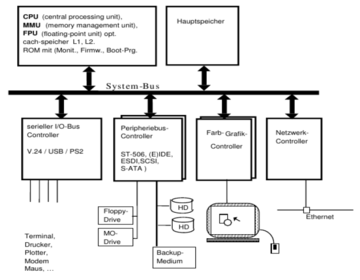
- CPU: holt Befehle aus Hauptspeicher und führt sie aus- Hauptspeicher: Speicher, der die gerade auszuführenden Programme oder Programmteile und die dabei benötigten Daten enthält- I/O-Controller: Modul zur Bedienung bon Ein/Ausgabeleitungen- Peripheriebus-Controller:Kontrolliert Bildschirm, Scanner, Drucker etc. - Grafik-/Farb-Controller:Medium zw Prozessor und Graphikkarte (?)- Netzwerk-Controller: Modul, das Daten über LAN/WLAN überträgt-Platten-Controller: führt selbstständige Aufträge (lesen/schreibe) auf HD/FD aus- externer Speicher: Festplatten, optische Platten
Hardware
Diapositiva 5
PC heute meist modular aufgebaut -> flexibel für Erfordernisse der AnwenderSie sind damit:- leicht erweiterbar / konfigurierbar, vgl. Baukastensystem -> Kostenreduktion durch versch. Hersteller- reparaturfreundlich ->besitzen hohe Verfügbarkeit (hohe Ausfallsicherh.+ schnell reparierbar)Voraussetzung dafür:- einheitlicher System-Bus: für Adress-, Daten- und Steuerleitungend.h. gleicher -- mechanischer Aufbau ("Backplane"), elektrische Eigenschaften, Leitungen, Signale, Timing, … -- logisch def. SS (Übergabeprotokoll für Daten) zwischen den Modulen- i.d.R. standardisiert, z.B.:ISA, EISA, Local-Bus (Vesa, PCI, PCIe), VME-, Multi-, Q-Bus, Micro-Channel
Aufbau und Komponenten
Diapositiva 6
Programmbearbeitung
Job = Ausführung eines Programms in Maschinencode
Prozess (= Task)
= "Folge von Systemzuständen", unter der Kontrolle eines Laufzeit- oder BS unabhängigen evtl neben anderen Programmen im Rechner ablaufendes Programm(-stück)./ \
leichtgewichtige: Schwergewichtige:- Ausführung innerhalb eines gem. Adressraums, - werden von BS streng voneinander getrennt- kein Speicherschutz voreinander, - Kommunikation nur über IPC - schnell zu verarbeiten - längere Prozessumschaltzeiten
Diapositiva 7
Programmbearbeitung
- BS muss Prozess einen Prozessor zuteilen- Prozessor holt Befehle des Programms, interpretiert sie und steuert deren Ausführung -> der Prozess läuft
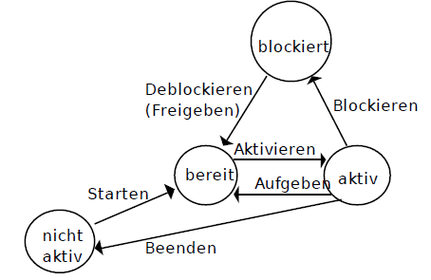
Prozesszustände----------------------------------------------------------->Starten: BS wählt Prozess und ordnet diesem Prozessor zuAktivierung: Prozess beginnt Abarbeitung des Prog. an der Stelle, an der der Prozessor zuvor aufgegeben oder blockiert wurdeBlockieren: erfolgt, wenn man zum Weiterarbeiten auf Ergebnis warten muss (zB Daten von Netzwerkcontroller)Aktivieren: BS teilt durch blockieren frei gewordenem Prozessor einen neuen Prozess zuDeblockieren: Deblockieren eines blockierten Prozesses durch eintreten eines EreignissesBeenden: Terminieren nach der Bearbeitung de letzten Befehls des Programmes des Prozesses
{kind=link}
Diapositiva 8
Programmbearbeitung
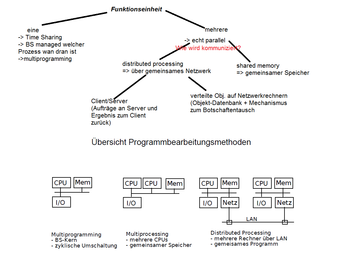
-parallele Bearbeitung von Prozesses ist nur möglich, wenn diese unabhängig bearbeitet werden könnenSequentielles Programm: -Ausführung von Anweisungen nacheinander -> Prozess(Task)- definiert nur eine einzige Task- benötigt nur if, while,...Prozessprogramm:-zwei oder mehrere sequentielle Programme die konkurrierend als Prozess ausgeführt werden- Ausführung auf einer oder mehreren Funktionseinheiten (einer: Time Sharing -> managed BS(multiprogramming) / mehrere: echt parallel(Verbindung durch shared memory oder gemeinsames Netzwerk =distributed processing )
{kind=link}
Diapositiva 9
Programmbearbeitung
Prozessprogramm = Programm zur Steuerung, Regelung , Manipulation eines technischen ProzessesKennzeichen:-EchtzeitcharakterNebenläufigkeit-externen Datenfluss ( außerhalb des Rechners; durch Interaktion mit Aktorik und Sensorik m.d. Prozess; nicht formal erfasst)RTLinux = Erweiterung von Linux zu Echtzeit-BS von Prof. Victor Yodaiken, Uni New Mexico
Diapositiva 10
Betriebsarten einer Rechenanlage
1. Stapelbetrieb (batch processing)- vollständig definierter Auftrag wird zusammenhängend an Anlage übergeben- ab dann keine Möglichkeit für Nutzer auf Ablauf einzuwirken- Ziele: Maximierung des Durchsatzes, optimale Auslastung der Betriebsmittel (Hardware und Software)
-oft in Rechenzentren- anfangs vorherrschend, heute bei Spezialrechnern (Supercomupting, rechenintensive Aufgaben)
{kind=link}
Diapositiva 11
Betriebsarten einer Rechenanlage
2. Dialogbetrieb ( interactive mode)-große Anzahl an Nutzern (viele Eingabeströme)- viele (gleich-)kurze Teilaufträge in Folge- Benutzer erwarten unmittelbare Reaktion des Rechners-Verarbeitung der Teilaufträge in Reihenfolge ihres EingangsTeilhaberbetrieb: alle Teilhaber haben dasselbe Programm (zB Zentralbuchung bei Banken)Teilnehmerbetrieb: jeder Teilnehmer hat beliebige Programme (zB Senden von bel. Aufträgen an Rechenanlage)->> Minimierung der Antwortzeiten für Kuranfragen
Diapositiva 12
Betriebsarten für Rechenanlagen
3. Echtzeitbetrieb (real time processing)- strenge Zeitbedingungen müssen eingehalten werden- Prozesse müssen unterbrechbar sein zB per Interrupt (preemtive-scheduling)- schnelle Reaktionszeiten (Millisekundebereich)Ziel: garantierte Antwortzeiten, die niemals überschritten werdenBeispiele: MP3-Player Autopilot im Flugzeug>>Periodische Ereignisse = System ist schedulable>> asynchrone Unterbrechungen = deadline scheduling
Diapositiva 13
Betriebsarten einer Rechenanlage
andere Einteilung von Betriebsarten:-Einbenutzerbetrieb:- überwiegende Betriebsart-> Windows XP/VISTA etc.- momentan gewünschte Aufgabe soll optimal ausgeführt werden, Rest spielt untergeordnete Rolle (zB Systemausnutzung- Anforderungen s. Stapelbetrieb- schlechtre Aystemkomponentenausnutzung-Mehrbenutzerbetrieb:- Workstations, Großrechner- mehrere Benutzer rechnen simultan mit mehreren Prozessen/Benutzer- Time-Sharing-Betrieb- gegenseitiger Schutz voreinander ist wichtig!
Diapositiva 14
Prozessscheduling
Problem: mehrere Prozesse rechenbereicht, welcher kommt dran?-> entscheidet Scheduler (Teil des BS) entsprechend AlgorithmusEigenschaften guter Algorthimen: Fairness (Gleichbehandlung aller Prozesse), Wirkungsgrad (optimale Auslastung der CPU)Response-Time (min. Antwortzeit für Benutzer)Turnaround-Zeit (min. Wartezeit auf Ausgabe von Batch-Jobs)Durchsatz (Max. Anzahl von Bearbeiteten Prozessen/StundeProblem: Scheduler weiß nicht, ob Prozess häufig blockiert werden muss (durch Warten auf Ereignis) oder stundenlang CPU verbrauchen willLösung: Hardwaretimer generiert zyklische Unterbrechungen (System Tick), löst damit Prozessumschaltung aus>> bei Unterbrechung entscheidet Scheduler gem. Algorithmus welcher Prozess nun dran kommtBenutzer bekommen Zeitscheibehöherpriore Prozesse unterprechen niederpriore!-> preemptive scheduling ( bereite, nicht wartenden, Prozesse werden temporör von Bearbeitung ausgeschlossen) <-> run to completion
Diapositiva 15
Prozessscheduling
1. Round Robin- am einfachsten- am fairsten- am häufigsten verwendetjeder Prozess bekommt best. Zeitdauer, danach wird er unterbrochen (wenn er sich noch nicht selbst unterbrochen hat)alle Prozesse gleich wichtigAufgabe Scheduler:verwaltung einer Liste, in der alle rechenbereite Prozesse ( bzw Verweise auf diese!) enthalten sindzu beachten:-man braucht auch Umschaltzeiten zwischen den Prozessen! ( 0,1-5 ms -> process switch)Aufwand für Prozesskontext:-Retten aller benutzten Register (besonders Programm und Stack-Pointer)- evtl Koprozessorregister
Merke:Bearbeitungszeit zu kurz -> schlechter WirkungsgradBearbeitungszeit zu lang -> zu lange Wartezeiten für kurze Transaktionen
Diapositiva 16
Prozessscheduling
Prozesschedulin
2. Priority SchedulingPrioritäten (in Form äußerer Faktoren) werden beachtetinitiale Prioritäten (Prio) -> Anfangszustandaktuelle Prioritäten (laufende/ current priority) -> Zustand nach inkrementieren>> Scheduler inkrementiert bei jedem System-Tick die Prio des Prozesses (bis auf 0, dann erneut auf initiale Prio, wenn Prozess noch nicht fertig)>> dynamische Änderung der initialen Prio möglich ( für besseren Durchsatz, zB wenn Prozesse häufig warten müssen wird Prio erhöht damit er wenn bereit endlich mal dran kommt)>> Prozess mit der höchsten Prio wird immer zuerst bearbeitetVarianten:1. Prozesse in Prio-Klassen einteilen und innerhalb einer Klasse Round Robin anwenden, zwischen Klassen priority scheduling
Diapositiva 17
Prozessscheduling
3. Multiple Queues- Prio-Klassen-Prinzip (1 - n Klassen, n ist höchste Prio)-jede Klasse bekommt time slice ( 2^n-i Stück, d.h. Klasse 3 von 5 bekommt 2^2=4 time slices)>>anfangs alle Prozesse in der höchsten Klasse>>braucht Prozess alle time slices (ohne sich selbst zu blockieren), dann wird er eine Klasse tiefer eingeordnet und bekommt doppelt so viel Zeit >> suspendiert er sich selbst, wird die Klasse erhöht=> CPU-intesive Prozesse (die sich wenig suspendieren) kommen weniger oft dran (dafür aber länger)=> spart häufige Prozessumschaltung
Diapositiva 18
Prozessscheduling
4. Shortest Job First-kürzester Job wird zuerst bearbeitet (speziell für batch jobs)=> geht nur wenn man die Ausführungszeit vorher schon weiß! (geht nicht im Dialogbetrieb)
Diapositiva 19
Prozessscheduling
5. Two-level Scheduling-wenn Prozesse nicht in Hauptspeicher entstehen Verlustzeiten für Ein-/Auslagerung, darumlow-level Scheduler:bearbeitet Prozesse im Hauptspeicherhigh-level Scheduler (übergeordnet):tauscht Prozesse zwischen Haupt- und Hintergrundspeicher aus (swapp)Kriterien:- Dauer der Auslagerung eines Prozesses (wie lange ist er schon im Hintergrundspeicher?)- Rechenzeit, die bisher verbraucht wurde- Größe des Prozesses- Priorität des Prozesses- angeforderte Geräte
Diapositiva 20
Prozessscheduling
6. Echtzeit Scheduling- möglichst kurze Latenzzeiten (Reaktionszeit) (unter 1 Millisek.)- tatsächlich pro-gesteuertes Scheduling aller ProzessePrioritätsinversion: A (hohe prio) muss auf C (niedrigeste Prio) warten, weil dies Mutex (verhindert das Verändern gemeinsam genutzter Datensrukturen) blockiert -------------------------------->>> A kann seine Priorität an C vererben, damit C nicht durch B blockiert wird
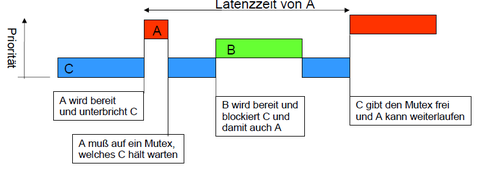{kind=link}
Diapositiva 21
Prozessverwaltung
-Programm besteht aus Sicht des BS aus mind. drei Speicherbereichen: - Programmcode - Datebereich - Stackbereich>>nur ein aktiver Prozess (d.h. kein Multiprocessing) -> Programm nutzt ganzen verfügbaren Speicher>>mehrere Prozesse -> Probleme bei Speicher- und Prozessverwaltung
{kind=link}
Diapositiva 22
Prozessverwaltung
1. Verfahren ohne Swapping(Tauschen von Blöcken) und Paging(Tauschen von Seiten)-BS und Treiber belegen Randbereiche des SpeichersAblauf>>Aufruf des Programms durch umgebende Shell per Name (vollst. Pfad)>> Exe von Filesystem (zB Festplatte) in den Hauptspeicher laden(Speicherbereich in RAM reservieren, Code und konstante Datenbereiche in HS kopieren, falls nicht absolut adressiert binden, variable Daten und Stackbereich einrichten)>> ausführen>> return zum umgebenden Shell>> HS wieder freigeben
Diapositiva 23
Prozessverwaltung
Speicherbelegung:-nur bei einfachen Rechnern(CPU) und BS beginnen alle Programme an gleicher HS-Adresse (-> kein Linken/verschieben)-> nicht bei DOS, da Treiber und Prg. vorgelagert sein können1.Code laden, Pointer für Anwenderprog hochsezen (->weniger Anwenderspeicher)2. Datenbereich: nach oben offen, dyn. Speicheranforderung möglich (Heap), (statische Variablen, Heap ist hier)3. Stapelspeicher(Stack), für Rücksprungadressen(Adresse an der ein Programm fortgesetzt wird nachdem ein Unterprogramm (=Funktionsaufruf) abgearbeitet wurde.) und lokale Variablen -Heap und Stack dürfen sich nicht überlappen(durch zu viele alloc-Aufrufen, zu tiefe Schachtelung durch Unterprogramm-Umgebungen)-> Lösung: Überprüfung von alloc-Fkt am Anfang von jedem Unterprogramm (->per Software), über versch Segmente und Memory-Management-Unit (->Hardware)
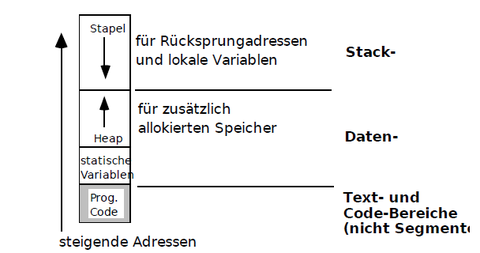{kind=link}
Diapositiva 24
Prozessverwaltung
Einbindung von BS-Funktionen (system calls):- Ein-/Ausgabe von Zeichen auf Tastatur/Bildschirm/LAN- Anfordern/Freigeben von Hauptspeicher- Lesen/schreiben auf Dateien/Geräten(zB Festplatte)- Abfrage des aktuellen Datums/Prozess-Nummer/UserName....Möglichkeiten der Behandlung von system calls:1. Verwenden von festen Einsprungadressen im BS-Code2. per Interrupt-Prozeduren (mind. 1)-> flexibler, kein Update der Programme notwendig( neuere BS)Merke: Besteht die Möglichkeit Gerätetreiber oder vorgelagerte Programme zu laden müssen Programme an unterschiedlichen Stellen im HS ablauffähig sein -> Prog muss nach Laden erst an eine Adresse gebunden werden und Adressbezüge neu berechnen, in Code einfügen (ermöglicht durch Relocation table= Tabelle mit Adressinfos)
Diapositiva 25
Prozessverwaltung
Problem: Programm > verfügbarer HS->Lösung: Overlay Technik - Programm in kleine Stücke (=Overlays) zerteilen - nur benötigte Teile im HS (Rest im Hintergrundspeicher, wird bei Bedarf geladen, aber nicht in Page/SwappArea, sondern als Datenfile)bei mehreren quasiparallel-ablaufenden Programmen:-> jedes aktive Programm bekommt eine Partition (Teil) des HS zugeteilt, welcher wiederum in Stack, Daten und Code-Teil eingeteilt wird)-> solange in HS bis Beendet oder abgebrochen
Diapositiva 26
Prozessverwaltung
Fixed Partitions:- HS wird ein Partitionen fester Größe eingeteilt- neue Prozesse in Warteschlange für kleinste PartitionProblem: Lücken im Speicher (durch vorher bestimmte Größe), die Speicherverschnitt bildenMöglichkeiten:1. Programm muss relocateable sein -> Code hat Tabelle mit Infos, welche Adressen an welcher Stelle im Code bei Verschieben geändert werden müssen2. CPU hat Bereichs-Zeiger, es werden nur auf einen Basiszeiger bezogene Adressen verwendet- initial nur für Code, Daten und Stack, tatsächliche Zeiger ergeben sich durch Addition der Basiszeiger und Zeiger innerhalb eines Segment (autom von CPU übernommen)Feste Zuweisung mit Verschieben:-Prüfen, ob Prozess in Lücke passt -> ja: einlagern; nein: prüfen ob Summe des restlichen Speichers reicht-> ja:verschiebenNachteil: Verschieben braucht viel CPU-Zeit, Programme müssen relocation table oder Basiszeiger habenProblem: Programme die dynamischen zusätzlichen Speicher brauchen (durch alloc, new, rekursion)Lösung: ausreichend viel Speicher muss vorgehalten werdenProblem: schlechte Ausnutzung des Speichers (da er freigehalten werden muss), keine Prozesse die mehr Speicher brauchen als vorhanden
Diapositiva 27
variable Partitionen:-Prozesse werden entsprechen dem verfügbaren und benötigtem Platz im HS abgelegt- neue Prozesse füllen Lücken der vorher beendetenVorteil: variable Anzahl von Tasks, ein Prozess kann ganzen HS belegenNachteil: schlechte Speicherausnutzung (kleine Lücken!) Lösung: dynamisches Verschieben von Bereichen im Speicher
Diapositiva 28
Virtuelle Speicherverwaltung mit Swapping
HS ist der tatsächlich im System physikalisch vorhandene Speicher, max so groß wie der von CPU real adressierbare SpeicherVS befindet sich vollständig auf dem Hintergrundspeicher, max so groß wie der von CPU adressierbare virt Adressraum-> CPU kann beide Speicher ansprechen (zur Umrechnung von vir. in phys. Adressen -> Memory Management Unit MMU)Für den Zugriff auf eine Adresse wird zuerst ein (Segment-) Deskriptor in ein spezielles Register geladen! Für jedes Segment existiert in der CPU / MMU ein solches Deskriptor-Register, welches den Selektor-Anteil einer logischen Adresse aufnimmt: Beim Laden eines Deskriptor-Registers mit dem Selektor-Anteil einer Adresse werden automatisch alle im Deskriptor enthaltenen Daten in entsprechende (sonst nicht zugängige) Register der CPU (genauer der MMU) geladen. Erst danach kann die logische in eine physikalische Adr. umgesetzt und gleichzeitig auch die Rechte und Attribute eines Segments überwacht werden.Aufgabe der MMU:• Berechnung der Adresse (einfache Summenbildung)• Überprüfung ob Adr. innerhalb des Segments (Limit und Granularität: Byte/4KB)• Überprüfung der Schreib, Lese, Ausführungsrechte bei Speicherzugriff• Überprüfung der Privileg-Level (CPL, RPL, DPL)Zur Bearbeitung eines Prozesses müssen:• vorher alle seine Segmente vollständig in den Hauptspeicher transferiert werden• die Seg.Register (außer CS) entsprechend ihrer akt. Pos. in HS geladen werdenProgramme (und Daten) sind dabei relativ zu den Segmentanfängen adressiert -> verbrauchte Rechenzeit -> Auslagerung auf HS
Diapositiva 29
Virtuelle Speicherverwaltung mit Swapping
Resultat:- nur soviele Prozesse wie auf HS passen können quasiparallel bearbeitet werden- sollen mehr Prozesse aktiv sein, müssen diese zyklische zwischen HS und VS ausgetauscht werden (zweistufiges Scheduling)- Prozess muss zur Bearbeitung vollständig in HS eingelagert werden -> Max Prozessgröße = Größes des phys. HS- kann Prozess nicht dauerhaft im HS gehalten werden, kann sich Reaktion des Programms verzögern (->kein Realtime BS möglich)Problem: Programme ändern mit Laufzeit ihre GrößeLösung: Swapping (alloc= system call -> vergrößerung des Datensegments/ Auslagerung auf größeres Segment)Problem: Programm passt nicht vollständig in HSLösung: Overlay-Technik ( BS lagert gerade relevante Programm- oder Datenteile ein/aus, nicht ganzen Daten, Programm und Stackbereich)
Diapositiva 30
Virtuelle Speicherverwaltung mit Paging
Prinzip: Streuspeicherverwaltung = Zerlegung des HS/VS in 1-4 KByte große Seiten/Kacheln (pages/page-frames)-BS verwaltete Seitentabelle (liegt in HS, enthalt häufig noch Zugriffsberechtigungen, Midifikationsbit, Zugriffszähler für Ein-/Auslagerstrategien) zur Umrechnung von linearen in phys. Adressen (Adresse = Seitentabellennummer + Distanz)-> befindet sich Seite nicht in Speicherkachel-> Programm unterbrechen -> Seite einlagern (evtl andere auslagern) -Y Bearbeitung fortsetzennotwendig: restartable instruction set (Maschinenbefehel muss intern unterbrechbar sein)Interrupt bei exception, aber innerhalb von Maschinenbefehl-> kann bei Swapping nicht auftreten, da alle Segmente vollständig im HS stehen müssenProblem: Verschnitt entsteht (ca Seitenlänge/2!!), Lösung: Seiten möglichst klein halten (-> große Umsatztabellen, Lösung: mehrere Seitentabellen)-für jeden aktuellen Prozess muss die Umsatztabelle im HS stehen- für jeden Prozess getrennte Tabellen (Prozesseitentabellen)Umsetzung der Seitentabellen:1. Tabelle hat so viele Zeilen wie der Prozess Seiten (Seitenummer ist Index in der Tabelle)2. Tabelle hat so viele Zeilen, wie der HS Kacheln hat ( an Pos i befindetsich die Nr, der in Kachel i eingelagerten Seite)
Diapositiva 31
Virtuelle Speicherverwaltung mit Paging
Suche: Vergleichen der Seitenummer mit Inhalt allen Zeilen, um die Zeile zu finden, in der sich die Seite befindet->Tabelle muss in inhaltsadressierten Speicher (Assoziativspeicher) sein (->gleichzeitiger Test in allen Zeilen!)Problem: nicht umsetzbarbei 1. man bräuchte zwei Zugriffe zum Lesen einer lin Adresse ( in Tabelle um Kachelnr zu ermitteln- Adresse generieren - HS lesen)bei 2. Assoziativspeicher in der Größe von Seitentabellen sind nicht realisierbar
virtuelle Adresse besteht aus:-Segmentadresse (höherwertig): Pointer- Seitenadresse(zweistufig, mittlerer Anteil): Seitenverzeichnisadresse =Pointer in Page-Directory Table enthält Pointer auf Seitentabelle , Seitenadresse= Pointer in Seitentabelle enthält Kachelnumer- Distanz (niederwertig)
Diapositiva 32
Virtuelle Speicherverwaltung mit Paging
Wichtig für Durchsatz der Rechenanlage ist das Verfahren zur dynamischen Ein-/Auslagerung von Speicherseiten-> Lokalität des Programs ist wichtig, d.h. keine Sprünge über große Distanzen Verfahren für Seitenersetzung (page replacement):-NRU (not recently used): Auslagern der Seite die im zurückliegenden Zeitraum nicht angesprochen wurde (->Seite hat zwei Statusbits: R =bei Leseopertion zu 1, M =Bbei Schreiboperation zu 1- FIFO (first in forst out): Auslagerung was sich am längsten im HS befindet (-> beim Einlagern der Seite wird Zeit festgestellt)- LRU (lest recently used): Auslagerung der Seite auf welche am längsten nicht mehr zugegriffen wurde (-> Eintragung der Uhrzeit bei Zugriff)- LFU (least frequently used): Auslagerung der Seite auf die bislang am wenigsten zugegriffen wurde (Jede Kachel bekommt zählwert, wird bei Zugriff inkrementiert)- PFF (page fault frequency): Häufigkeit, mit der Prozess page-faults erzeugt wird beachtet(zwei schranken: überschreitung-> ausdehnen, unterschreitung -> abgeben
Diapositiva 33
Virtuelle Speicherverwaltung mit Paging
Working-Set Algorithmus
¿Quieres crear tus propias Diapositivas gratis con GoConqr? Más información.