10549188
| Pregunta | Respuesta |
| T/F: Age/gender are also outcome measures. | F. These are baseline characteristics |
| Psychometric properties are the intrinsic properties of an outcome measure and include ________, ________, and ________. | 1. Reliability 2. Validity 3. Clinical meaningfulness |
| What are the two general outcome measure categories? | 1. Questionnaires 2. performance-based measures |
| In performance-based measures, time to complete a task is an example of _________ measurement; while determining whether a patient has normal/abnormal gait pattern is a ________ measurement. | 1. Objective. 2. Qualitative |
| The type of outcome measures can also be categorized based on ICF model. Match the following measures to respective ICF level. 1. Geriatric depression scale 2. Mini-mental state exam 3. Activities-specific Balance Confidence Scale 4. 10 Meter Walk Test 5. Pediatric evaluation of disability inventory (PEDI) 6. Neck Disability Index 7. Oswestry disability questionnaire | 1, 2: Body function and impairment 3, 4, 5: Activity limitation 6, 7: Participation restriction |
| Validity refers to an outcome's ability to ____________. | measure the characteristics it is intended to measure |
| Reliability refers to an outcome measure's _______ in _________. | consistency in score production |
| What are the 4 types of reliability that should be considered when appraising outcome measures? | 1. internal consistency 2. test-retest reliability 3. intra-rater reliability 4. inter-rater reliability |
| Which reliability answers the question: Do all the items measure the same construct? | Internal consistency |
| Internal consistency is the consistency of _______ across individual items of an outcome measure. | construct |
| How is internal consistency measured? | 1. conduct the outcome measure on a group of people 2. analyze the INTRA-SUBJECT CORRELATION between items |
| Internal consistency is measured using the __________ (statistical measure). | Cronbach alpha |
| Cronbach alpha ranges from ___ to ___. | 0 to 1. |
| Cronbach alpha close to 0 indicates that ________. | Individual items of the measure DO NOT correlate with each other. |
| Cronbach alpha close to 1 indicates that ____________. | The individual items have STRONG CORRELATION with each other. |
| Why do we not want the Cronbach alpha to exceed 0.90? | Because excessive correlation suggests likelihood of repetition between items in an outcome measure |
| What if the Cronbach alpha in a special population is 0.97? | Consider shortening the test. |
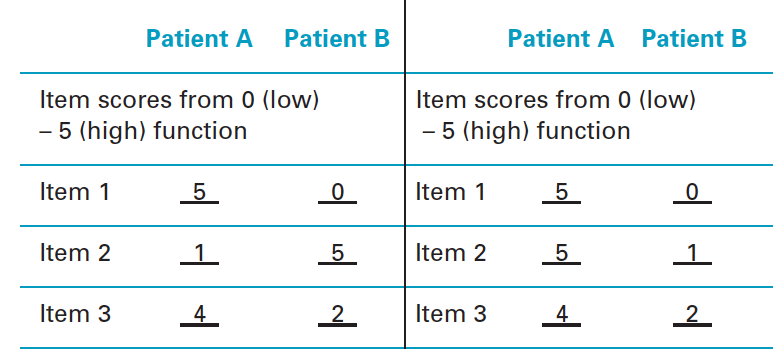
| Which study has a higher internal consistency? | The one on the right. (patient A is consistently higher, patient B is consistently lower). |
| Test-retest reliability establishes the extent to which an outcome measure produces ___________ when ___________ to a patient who (has/has not) experienced change. | 1. produces the same result 2. when tested repeatedly 3. on a patient who HAS NOT CHANGED! |
| To determine the test-retest consistency, (one/multiple) rater measures (the same/ multiple) patient two or more times, over the course of (a year/ several days). | 1. ONE tester 2. THE SAME patient 3. a few days |
| Who is the tester in a patient self-directed questionnaire? | Patient him/herself |
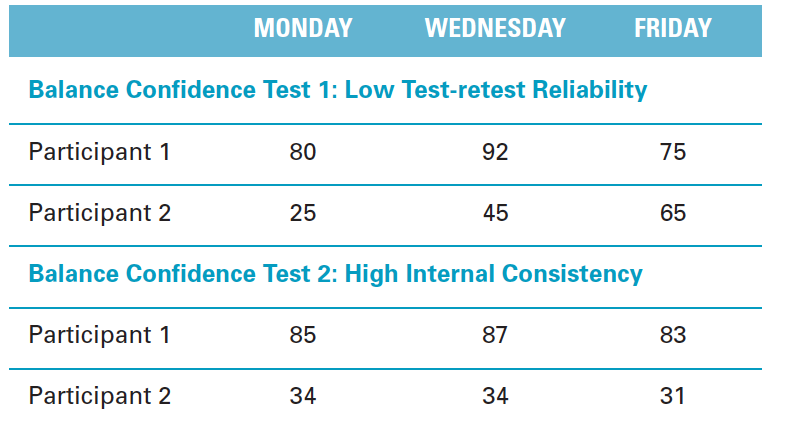
| Which test has a better test-retest reliability? | Bottom test. |
| The consistency with which an OM produces the same score when used by the same therapist on the same patient is called ________. | Intra- rater reliability |
| T/F: usually only 1 therapists were required to perform the same test on the same patient repeatedly over several days to test for intra-rater reliability. | F. Usually requires 2 or more therapists |
| The difference between test-retest reliability and intra-rater reliability is that ______ refers only to the OM itself, while __________ specifically addresses the skills of the raters. | [TEST-RETEST reliability] refers only to the OM itself, while [intra-rater reliability] specifically addresses the skills of the raters. |
| Inter-rater reliability refers to the consistency with which (the same/different) raters produce (the same/different) scores for (the same/different) patient. | Different raters same score same patient |
| A trial involving many therapists rating one patient at the same time is able to tell you about the OM's _____. | inter-rater reliability. |
| T/F: the same statistical tool is used to compare test-retest reliability, intra-rater reliability, and inter-rater reliability. | T. |
| Which test is used to compare test-retest reliability, intra-rater reliability, and inter-rater reliability? | ICC (intraclass correlation coefficient) or kappa analysis |
| Kappa is usually used for _______ while ICC is usually used for ___________. | Kappa: nominal/ ordinal data ICC: consecutive data |
| Kappa ranges from __ to __ | -1 to +! |
| ICC ranges from __ to ___. | 0 to 1 |
| If the absolute value of kappa/ICC is >0.80, then there is _____ agreement. | excellent |
| If the absolute value of kappa/ICC is between 0.60 to 0.80, then there is _____ agreement. | substantial |
| If the absolute value of kappa/ICC is between 0.40 to 0.60, then there is _____ agreement. | moderate |
| If the absolute value of kappa/ICC is less than 0.40, then there is _____ agreement. | poor |
| For a study of OM to have good reliability, the study's purpose should be ____ to the clinical question. | relevant |
| For a study of OM to have good reliability, the inclusion/exclusion criteria should _________. | be clearly defined and include my patient |
| For a study of OM to have good reliability, the OMs should be _____ to my clinical question and be conducted in a _____ anner. | relevant. clinically realistic |
| For a study of OM to have good reliability, the study population should _________. | Be sufficiently similar to my patient |
| For a study of OM to have good reliability, the sample size should be ______ | sufficiently large |
| For a study of OM to have good reliability, the participants should be (more/less) diverse in the full range of OMs. | More diverse (so that a full spectrum of people the OM was designed for is tested.) |
| For a study of OM to have good reliability, the participants should be (stable/unstable) in the character of interest. | Stable. (no change in medication/ treatment during the period of testing) |
| For a study of OM to have good reliability, there should be evidence that the tests were conducted in a ______ manner. | reasonably consistent (e.g. quiet room v.s. noisy street) |
| For a study of OM to have good reliability, the raters should be blinded of _______. | previous participant scores |
| Why should there be ample time given even when assessing the intra-rater reliability? | 1. raters may remember the previous score 2. patient may be fatigued |
| There are three types of outcome measure validity, they are______, _______ and ______. | Content validity, criterion validity, and construct validity. |
| Content validity establishes that an outcome measure includes____________ that it purports to measure. | all the characteristics |
| How is content validity established? | 1. panel of experts 2. each determines whether the measure include all important components of the construct |
| A less formal evaluation of content validity is ________. | Face validity |
| The measure of whether the tested OM matches a gold standard is called ________. | Criterion validity |
| T/F: A gold standard criterion measure has the virtually irrefutable validity for measuring the characteristics of interest. | T. |
| When a gold standard criterion does not exist, a ______ can be used. | reference standard |
| Criterion validity studies can be divided into _______ and ________ validity. | concurrent and predictive |
| Concurrent validity is established when researchers demonstrate that an outcome measure has a high correlation with the criterion measure taken at ___________. | The same point of time |
| Predictive validity is established when researchers demonstrate that an OM has a high correlation with a ________. | future criterion measure |
| ________ establishes the ability of an OM to assess n abstract characteristic or concept. | construct validity |
| How is construct validity established? | 1. provide a theoretical model that describes the constructs being assessed. 2. a series of studies are conducted to establish whether the measure actually assess those constructs |
| What are the three commonly used methods to establish construct validity? | 1. known-group validity 2. convergent validity 3. discriminant validity |
| Known-group validity establishes that an OM produces (the same/different) scores for groups with known (similarities/differences) on the characteristic being measured. | Different. known differences. |
| _________ validity establishes that a new measure correlates with another thought to measure similar a characteristic or concept. (High/low) correlation is ideal. | Convergent High correlation is ideal |
| __________ validity establishes that a new measure correlates with another thought to measure a distinctly different characteristic or concept. (High/low correlation is ideal). | Discriminant validity Low correlation is ideal |
| Which statistic test is used to detemine criterion validity? | Spearman's rho |
| convergent validity test may look the same as __________. | concurrent validity |
| To interpret Spearman's rho value, _____ is generally strong, _______ is moderate and _______ is poor. | > 0.85 is strong 0..60 - 0.85 is moderate < 0.6 is poor |
| To have good content validity, the experts establishing the criteria should be _______ | diverse and allow different perspective. |
| To have good content validity, the researchers should collect and respond to the expert's feedback ________. | systematically |
| To have good criterion and construct validity, the authors should argue for the credibility of the _____ or _______. | gold standard or reference criterion measure |
| To have good criterion and construct validity, the raters should be ______ to the results of the OM as well as the criterion measure. | blinded |
| T/F: To have good criterion and construct validity, all participants should have completed one or the other measure. | F. All participants should have completed BOTH measures. |
| T/F: To have good criterion and construct validity, there should be reasonable time between tests for predictive validity. | T. |
| For known-group construct validity studies, the groups established should be ________ on the characteristics of interest. | distinctively different |
{kind=link}
{kind=link}
¿Quieres crear tus propias Fichas gratiscon GoConqr? Más información.