13178452
Descripción
Mapa Mental por ANTHONY JACKSON VALENCIA CASTILLO, actualizado hace más de 1 año
|
|
Creado por ANTHONY JACKSON VALENCIA CASTILLO
hace más de 6 años
|
|
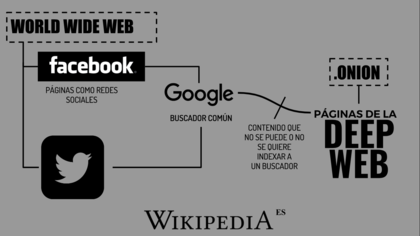
La Deep Web
- Origen
- La principal causa de existencia es la imposibilidad de los
motores de búsqueda (Google, Yahoo, Bing,
etc.) de encontrar o indexar gran parte de la
información existente en Internet.
- La principal causa de existencia es la imposibilidad de los
motores de búsqueda (Google, Yahoo, Bing,
etc.) de encontrar o indexar gran parte de la
información existente en Internet.
- Tamaño
- En 2010 se estimó que la información que se encuentra
en la internet profunda es de 7500 terabytes, lo que
equivale a aproximadamente 550 billones de
documentos individuales. El contenido de la internet
profunda es de 400 a 550 veces mayor de lo que se
puede encontrar en la internet superficial.
- En 2010 se estimó que la información que se encuentra
en la internet profunda es de 7500 terabytes, lo que
equivale a aproximadamente 550 billones de
documentos individuales. El contenido de la internet
profunda es de 400 a 550 veces mayor de lo que se
puede encontrar en la internet superficial.
- Motivos
- Web contextual
- páginas cuyo contenido varía dependiendo del
contexto (por ejemplo, la dirección IP del cliente,
de las visitas anteriores, etc.).
- páginas cuyo contenido varía dependiendo del
contexto (por ejemplo, la dirección IP del cliente,
de las visitas anteriores, etc.).
- Contenido dinámico
- páginas dinámicas obtenidas como
respuesta a parámetros, por ejemplo, datos
enviados a través de un formulario.
- páginas dinámicas obtenidas como
respuesta a parámetros, por ejemplo, datos
enviados a través de un formulario.
- Contenido de acceso restringido
- páginas protegidas con contraseña,
contenido protegido por un Captcha,
etc.
- páginas protegidas con contraseña,
contenido protegido por un Captcha,
etc.
- Software
- Contenido oculto intencionadamente, que requiere
un programa o protocolo específico para poder
acceder (ejemplos: Tor, I2P, Freenet)
- Contenido oculto intencionadamente, que requiere
un programa o protocolo específico para poder
acceder (ejemplos: Tor, I2P, Freenet)
- Web contextual
- Rastreando la internet profunda
- Los motores de búsqueda comerciales han comenzado a
explorar métodos alternativos para rastrear la Web
profunda. El Protocolo del sitio (primero desarrollado e
introducido por Google en 2005) y OAI son mecanismos
que permiten a los motores de búsqueda y otras partes
interesadas descubrir recursos de la internet profunda
en los servidores web en particular.
- Los motores de búsqueda comerciales han comenzado a
explorar métodos alternativos para rastrear la Web
profunda. El Protocolo del sitio (primero desarrollado e
introducido por Google en 2005) y OAI son mecanismos
que permiten a los motores de búsqueda y otras partes
interesadas descubrir recursos de la internet profunda
en los servidores web en particular.
- Denominación
- Bergman, en un artículo semanal sobre la Web
profunda publicado en el Journal of Electronic
Publishing, mencionó que Jill Ellsworth utilizó el
término «Web invisible» en 1994 para referirse a los
sitios web que no están registrados por ningún
motor de búsqueda.
- Bergman, en un artículo semanal sobre la Web
profunda publicado en el Journal of Electronic
Publishing, mencionó que Jill Ellsworth utilizó el
término «Web invisible» en 1994 para referirse a los
sitios web que no están registrados por ningún
motor de búsqueda.
- Métodos de profundización
- Las arañas (web crawlers)
- Una araña web (crawler) es un
programa o script automatizado que
inspecciona la World Wide Web de una
manera metódica y automatizada.
- Una araña web (crawler) es un
programa o script automatizado que
inspecciona la World Wide Web de una
manera metódica y automatizada.
- Tor
- El Navegador Tor es una versión actualizada de
privacidad optimizada de Mozilla Firefox. Es un
software libre y de código abierto que permite el
anonimato en línea y evasión de censura.
- El Navegador Tor es una versión actualizada de
privacidad optimizada de Mozilla Firefox. Es un
software libre y de código abierto que permite el
anonimato en línea y evasión de censura.
- Las arañas (web crawlers)
Recursos multimedia adjuntos
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
¿Quieres crear tus propios Mapas Mentales gratis con GoConqr? Más información.