18891575
Descripción
Mapa Mental por Julissa Ayala, actualizado hace más de 1 año
|
|
Creado por Julissa Ayala
hace más de 5 años
|
|
ESTADISTICA INFERENCIAL
- DEFINICION En el ámbito científico, la estadística, en general, y la estadística inferencial, en particular, es el camino
que hay que recorrer para llegar de una pregunta a la respuesta adecuada. Así, la estadística no es más que un
argumento para defender nuestras ideas
- ¿Cuándo es necesaria la estadística inferencial? Cuando queremos hacer alguna afirmación sobre más
elementos de los que vamos a medir.
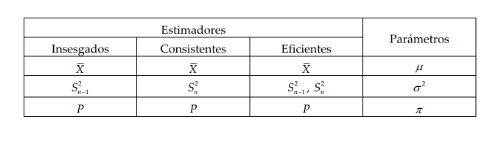
- ESTIMACION PUNTUAL
- La estimación puntual asigna directamente
al parámetro el valor obtenido para el
estadístico.
- La estimación puntual constituye la inferencia más
simple que podemos reali‐ zar: asignar al
parámetro el valor del estadístico que mejor sirva
para estimarlo. Pero para que un estadístico sea
considerado un buen estimador ha de cumplir
ciertas condiciones
- Si usamos los símbolosθ para un parámetro cualquiera, y ˆθ ,
para un posible estimador de θ , podemos enunciar las
propiedades de la siguiente forma:
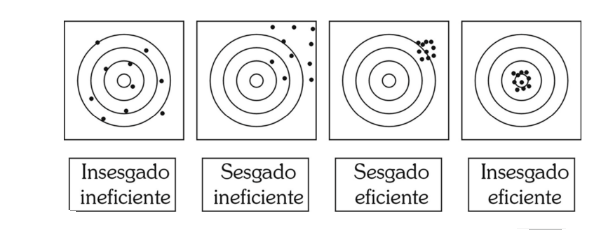
- • Carencia de sesgo: Un
estimador, ˆθ , será insesgado
si su valor esperado coinci‐ de
con el del parámetro a estimar,
θ . ˆ E(θ) =θ
- Consistencia: Un estimador, ˆθ , será consistente
si, conforme aumenta el tamaño muestral, n, su
valor se va aproximando a θ . Expresado más
formalmente, in‐ dica que dada una cantidad
arbitrariamente pequeña, δ , cuando n tiende a
infinito, P(lθ-θl<s)=1
- Eficiencia: Dados dos posibles
estimadores 1 ˆθ y 2 ˆθ , diremos
que 1 ˆθ es un esti‐ mador más
eficiente que 2 ˆθ si se cumple
- Suficiencia: Un estimador, ˆθ ,
será suficiente si utiliza toda la
información muestral disponible.
- • Carencia de sesgo: Un
estimador, ˆθ , será insesgado
si su valor esperado coinci‐ de
con el del parámetro a estimar,
θ . ˆ E(θ) =θ
- ejemplo
- MARCO DE REFERENCIA
http://esta2.galeon.com/Temas1-3.pdf Soluciones de
Ejercicios de estimacion
http://lcolladotor.github.io/courses/Courses/MEyAdDG/day2/Pruebas%20de%20Hip%C3%B3tesis.pdf
- La estimación puntual asigna directamente
al parámetro el valor obtenido para el
estadístico.
- ESTIMADOR POR INTERVALOS
- Intervalo de confianza de un parámetro
poblacional es un par ordenado de funciones reales
L1 x1,…, xn ( ) , L2 x1,…, xn ( ) que dependen de las n
medidas de una muestra aleatoria de la población
en cuestión.
- La estimación por intervalos
consiste en establecer el intervalo
de valores donde es más probable
se encuentre el parámetro. La
obtención del intervalo se basa en
las siguientes consideraciones:
- Si conocemos la distribución muestral
del estimador podemos obtener las
probabilidades de ocurrencia de los
estadísticos muestrales.
- Si conociéramos el valor del parámetro poblacional,
podríamos establecer la probabilidad de que el estimador
se halle dentro de los intervalos de la distribución
muestral.
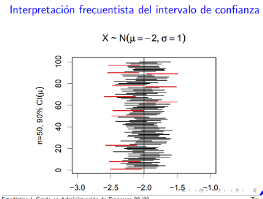
- El problema es que el parámetro poblacional es desconocido, y por ello
el intervalo se establece alrededor del estimador. Si repetimos el
muestreo un gran número de veces y definimos un intervalo alrededor
de cada valor del estadístico muestral, el parámetro se sitúa dentro de
cada intervalo en un porcentaje conocido de ocasiones. Este intervalo es
denominado "intervalo de confianza".
- Si conocemos la distribución muestral
del estimador podemos obtener las
probabilidades de ocurrencia de los
estadísticos muestrales.
- Intervalo de confianza de un parámetro
poblacional es un par ordenado de funciones reales
L1 x1,…, xn ( ) , L2 x1,…, xn ( ) que dependen de las n
medidas de una muestra aleatoria de la población
en cuestión.
- PRUEBA DE HIPOTESIS
- Otra manera de hacer inferencia es haciendo una afirmación
acerca del valor que el parámetro de la población bajo estudio
puede tomar. Esta afirmación puede estar basada en alguna
creencia o experiencia pasada que será contrastada con la
evidencia que nosotros obtengamos a través de la información
contenida en la muestra. Esto es a lo que llamamos Prueba de
Hipótesis
- La Hipótesis Nula, denotada como H0 siempre
especifica un solo valor del parámetro de la
población si la hipótesis es simple o un conjunto
de valores si es compuesta (es lo que queremos
desacreditar)
- FORMULAS
- FORMULAS
- La Hipótesis Alternativa, denotada como H1 es la que responde
nuestra pregunta, la que se establece en base a la evidencia que
tenemos
- FORMULA
- Como las conclusiones a las que lleguemos se
basan en una muestra, hay posibilidades de que
nos equivoquemos. Dos decisiones correctas son
posibles:
- Rechazar H0 cuando es
falsa No Rechazar H0
cuando es verdadera.
- Dos decisiones incorrectas son posibles:
Rechazar H0 cuando es verdadera No
Rechazar H0 cuando es falsa
- Rechazar H0 cuando es
falsa No Rechazar H0
cuando es verdadera.
- FORMULA
- Error de tipo I
- Si usted rechaza la hipótesis nula cuando es verdadera, comete un error
de tipo I. La probabilidad de cometer un error de tipo I es α, que es el
nivel de significancia que usted establece para su prueba de hipótesis.
Un α de 0.05 indica que usted está dispuesto a aceptar una probabilidad
de 5% de estar equivocado al rechazar la hipótesis nula. Para reducir
este riesgo, debe utilizar un valor menor para α. Sin embargo, usar un
valor menor para alfa significa que usted tendrá menos probabilidad de
detectar una diferencia si esta realmente existe
- Si usted rechaza la hipótesis nula cuando es verdadera, comete un error
de tipo I. La probabilidad de cometer un error de tipo I es α, que es el
nivel de significancia que usted establece para su prueba de hipótesis.
Un α de 0.05 indica que usted está dispuesto a aceptar una probabilidad
de 5% de estar equivocado al rechazar la hipótesis nula. Para reducir
este riesgo, debe utilizar un valor menor para α. Sin embargo, usar un
valor menor para alfa significa que usted tendrá menos probabilidad de
detectar una diferencia si esta realmente existe
- Error de tipo II
- Cuando la hipótesis nula es falsa y usted no la rechaza, comete un error de tipo II. La probabilidad de cometer
un error de tipo II es β, que depende de la potencia de la prueba. Puede reducir el riesgo de cometer un error de
tipo II al asegurarse de que la prueba tenga suficiente potencia. Para ello, asegúrese de que el tamaño de la
muestra sea lo suficientemente grande como para detectar una diferencia práctica cuando esta realmente
exista
- Cuando la hipótesis nula es falsa y usted no la rechaza, comete un error de tipo II. La probabilidad de cometer
un error de tipo II es β, que depende de la potencia de la prueba. Puede reducir el riesgo de cometer un error de
tipo II al asegurarse de que la prueba tenga suficiente potencia. Para ello, asegúrese de que el tamaño de la
muestra sea lo suficientemente grande como para detectar una diferencia práctica cuando esta realmente
exista
- Otra manera de hacer inferencia es haciendo una afirmación
acerca del valor que el parámetro de la población bajo estudio
puede tomar. Esta afirmación puede estar basada en alguna
creencia o experiencia pasada que será contrastada con la
evidencia que nosotros obtengamos a través de la información
contenida en la muestra. Esto es a lo que llamamos Prueba de
Hipótesis
- Regresión lineal y correlación.
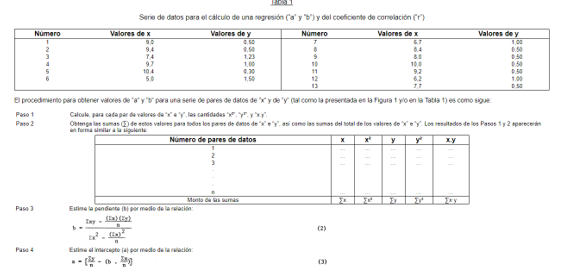
- Expresándolo en forma simple, la regresión lineal es una técnica que permite cuantificar la relación que
puede ser observada cuando se grafica un diagrama de puntos dispersos correspondientes a dos variables,
cuya tendencia general es rectilínea (Figura la); relación que cabe compendiar mediante una ecuación “del
mejor ajuste” de la forma: LINEAL
Nota:
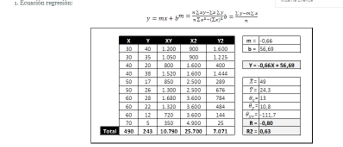
- y = a + bx En esta ecuación, “y” representa los valores de la coordenada a lo largo del eje vertical en el gráfico (ordenada); en tanto que “x” indica la magnitud de la coordenada sobre el eje horizontal (absisa). El valor de “a” (que puede ser negativo, positivo o igual a cero) es llamado el intercepto; en tanto que el valor de “b” (el cual puede ser negativo o positivo) se denomina la pendienteo coeficiente de regresión.
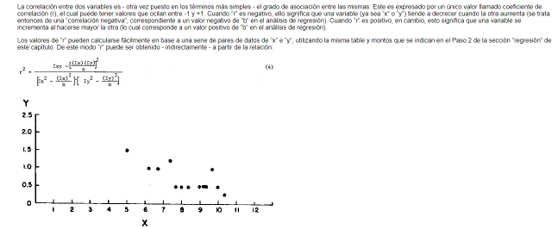
- El Diagrama de dispersión es una
herramienta utilizada cuando se desea
realizar un análisis gráfico de datos
bivariados, es decir, los que se refieren a dos
conjuntos de datos. El resultado del análisis
puede mostrar que existe una relación entre
una variable y la otra.
- Coeficiente de correlación El análisis de correlación se encuentra
estrechamente vinculado con el análisis de regresión y ambos
pueden ser considerados de hecho como dos aspectos de un mismo
problema.
- ECUACION DE REGRECION La ecuación de la recta de regresión permite pronosticar la
puntuación que alcanzará cada sujeto en una variable Y conociendo su puntuación en otra
variable X. A la variable Y se le denomina criterio y a la variable X predictor.
- Expresándolo en forma simple, la regresión lineal es una técnica que permite cuantificar la relación que
puede ser observada cuando se grafica un diagrama de puntos dispersos correspondientes a dos variables,
cuya tendencia general es rectilínea (Figura la); relación que cabe compendiar mediante una ecuación “del
mejor ajuste” de la forma: LINEAL
- Diseño de experimentos.
- Los modelos de diseño de experimentos son modelos
estadísticos clásicos cuyo objetivo es averiguar si unos
determinados factores influyen en una variable de
interés y, si existe influencia de algún factor,
cuantificar dicha influencia.
- — Se quiere estudiar el rendimiento de los
alumnos en una asignatura y, para ello, se
desean controlar diferentes factores:
profesor que imparte la asignatura; método
de enseñanza; sexo del alumno.
- — Se quiere estudiar el rendimiento de los
alumnos en una asignatura y, para ello, se
desean controlar diferentes factores:
profesor que imparte la asignatura; método
de enseñanza; sexo del alumno.
- Análisis de varianza ANOVA
- El análisis de la varianza (ANOVA) es una potente herramienta estadística, de
gran utilidad tanto en la industria, para el control de procesos, como en el
laboratorio de análisis, para el control de métodos analíticos.
- El objetivo del ANOVA aquí es comparar los errores
sistemáticos con los aleatorios obtenidos al realizar
diversos análisis en cada laboratorio.
- El análisis de la varianza (ANOVA) es una potente herramienta estadística, de
gran utilidad tanto en la industria, para el control de procesos, como en el
laboratorio de análisis, para el control de métodos analíticos.
- Los modelos de diseño de experimentos son modelos
estadísticos clásicos cuyo objetivo es averiguar si unos
determinados factores influyen en una variable de
interés y, si existe influencia de algún factor,
cuantificar dicha influencia.
- Julissa Ayala Ontiveros
mateniemiento industrial
probabilidad y estadistica
3B
- TOJO EL QUE SE ROBE MI TRABAJO
- TOJO EL QUE SE ROBE MI TRABAJO
Recursos multimedia adjuntos
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
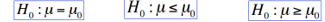{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
¿Quieres crear tus propios Mapas Mentales gratis con GoConqr? Más información.