4580207
Descripción
Mapa Mental por Germán Gonzalo Rojas Perdomo, actualizado hace más de 1 año
|
|
Creado por Germán Gonzalo Rojas Perdomo
hace casi 9 años
|
|
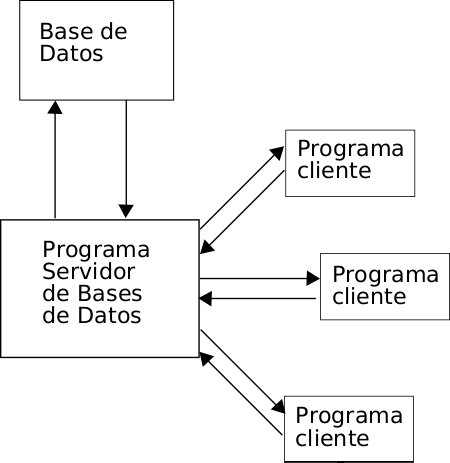
Sistema Gestor de Base de Datos
- Concepto
- Es el conjunto de programas que
administran y gestionan la
informacion de una base de
datos
- Es el conjunto de programas que
administran y gestionan la
informacion de una base de
datos
- Caracteristicas
- El método de almacenamiento y el programa
que gestiona los datos (servidor) son
independientes del programa desde el que se
lanzan las consultas (cliente)
- En lugar de primarse la visualización
de toda la información, el ojetivo
fundamental es permitir consultas
complejas, cuya resolución está
optimizada, expresadas mediante un
lenguaje formal.
- El almacenamiento de los datos se hace de
forma eficiente aunque oculta para el usuario y
normalmente tiene, al contrario de lo que
ocurre con las hojas de cálculo, poco que ver
con la estructura con la que los datos se
presentan al usuario.
- El acceso concurrente de múltiples
usuarios autorizados a los datos,
realizando operaciones de actualización
y consulta de los mismos garantizando
la ausencia de problemas de seguridad
(debidos a accesos no autorizados) o
integridad (pérdida de datos por el
intento de varios usuarios de acceder al
mismo fichero al mismo tiempo.
- El método de almacenamiento y el programa
que gestiona los datos (servidor) son
independientes del programa desde el que se
lanzan las consultas (cliente)
- Ventajas y desventajas
- Ventajas
- Reutilización de datos y programas
- Control de redundancia
- Mantenimiento y reingeniería: Cambios en la
estructura de datos sin cambiar los programas que
lo usan.
- Rapidez de desarrollo
- Seguridad
- Integridad
- Es posible equilibrar las cargas de
los requerimientos
- Reutilización de datos y programas
- Desventajas
- Puedo llegar a trabajar en forma “lenta” debido a la
cantidad de verificaciones que debe hacer.
- Compatibilidad en la
recuperación a fallas
- Susceptibilidad de fallas
- Tamaño
- Puedo llegar a trabajar en forma “lenta” debido a la
cantidad de verificaciones que debe hacer.
- Ventajas
- Historia
- Las bases de datos han estado en uso desde los
primeros días de las computadoras
electrónicas.la mayor parte de los sistemas
originales estaban enfocados a bases de datos
específicas y pensados para ganar velocidad a
costa de perder flexibilidad. Los SGBD originales
sólo estaban a disposición de las grandes
organizaciones que podían disponer de las
complejas computadoras necesarias.
- Sistemas de navegación (1960)
- Según las computadoras fueron ganando velocidad y capacidad,
aparecieron sistemas de bases de datos de propósito general; a
mediados de 1960 ya había algunos sistemas en uso. Apareció el
interés en obtener un estándar y Charles Bachman -autor de uno de
los primeros productos, el Integrated Data Store (IDS)- fundó el
Database Task Group dentro de CODASYL, el grupo responsable de la
creación y estandarización de COBOL. En 1971 publicaron su
estándar, que pasó a ser conocido como la «aproximación
CODASYL», y en breve aparecieron algunos productos basados en
esta línea.
- La estrategia de CODASYL estaba basada en la navegación manual por
un conjunto de datos enlazados en red. Cuando se arrancaba la base de
datos, el programa devolvía un enlace al primer registro de la base de
datos, el cual a su vez contenía punteros a otros datos. Para encontrar
un registro concreto el programador debía ir siguiendo punteros hasta
llegar al registro buscado.
- IBM también tenía su SGBD propio en
1968, conocido como IMS. Se trataba
de un software desarrollado para el
programa Apolo sobre System/360.
IMS tenía conceptos similares a
CODASYL, pero usaba una jerarquía
estricta de ordenación de los datos,
frente a la estructura en red de
CODASYL.
- Según las computadoras fueron ganando velocidad y capacidad,
aparecieron sistemas de bases de datos de propósito general; a
mediados de 1960 ya había algunos sistemas en uso. Apareció el
interés en obtener un estándar y Charles Bachman -autor de uno de
los primeros productos, el Integrated Data Store (IDS)- fundó el
Database Task Group dentro de CODASYL, el grupo responsable de la
creación y estandarización de COBOL. En 1971 publicaron su
estándar, que pasó a ser conocido como la «aproximación
CODASYL», y en breve aparecieron algunos productos basados en
esta línea.
- Sistemas relacionales (1970)
- Edgar Codd trabajaba en IBM, en una de esas oficinas periféricas que
estaba dedicada principalmente al desarrollo de discos duros. Estaba
descontento con el modelo de navegación CODASYL, principalmente
con la falta de operación de búsqueda. En 1970 escribió algunos
artículos en los que perfilaba una nueva aproximación que culminó en
el documento "A Relational Model of Data for Large Shared Data
Banks"
- Edgar Codd trabajaba en IBM, en una de esas oficinas periféricas que
estaba dedicada principalmente al desarrollo de discos duros. Estaba
descontento con el modelo de navegación CODASYL, principalmente
con la falta de operación de búsqueda. En 1970 escribió algunos
artículos en los que perfilaba una nueva aproximación que culminó en
el documento "A Relational Model of Data for Large Shared Data
Banks"
- Sistemas SQL (finales de década de 1970)
- IBM comenzó a trabajar a principios de 1970 en un prototipo
lejanamente basado en los conceptos de Codd llamándolo
System R. La primera versión estuvo lista en 1974 o 1975, y
comenzó así el trabajo en sistemas multi-tabla, en los que los
datos podían disgregarse de modo que toda la información
de un registro (alguna de la cual es opcional) no tiene que
estar almacenada en un único trozo grande. Las versiones
multi-usuario siguientes fueron probadas por los usuarios en
1978 y 1979, tiempo por el que un lenguaje SQL había sido
estandarizado. Las ideas de Codd se revelaron como
operativas y superiores a las de CODASYL, lanzando a IBM al
desarrollo de una verdadera versión de producción de
System R, conocido como SQL/DS, y posteriormente como
Database 2
- Muchos de los técnicos de INGRES estaban seguros del éxito
comercial del sistema, y formaron sus propias compañías para
comercializar el desarrollo pero con un interfaz SQL. Sybase,
Informix, NonStop SQL y la misma INGRES se vendían como
derivados del INGRES original en los años 1980. Incluso el SQL
Server de Microsoft está basado en Sybase, y por consiguiente en
INGRES. Sólo Larry Ellison -el fundador de Oracle- comenzó un
nuevo camino basado en el artículo de IBM sobre System R, y
aventajó a IBM sacando al mercado su primera versión en 1978.
- IBM comenzó a trabajar a principios de 1970 en un prototipo
lejanamente basado en los conceptos de Codd llamándolo
System R. La primera versión estuvo lista en 1974 o 1975, y
comenzó así el trabajo en sistemas multi-tabla, en los que los
datos podían disgregarse de modo que toda la información
de un registro (alguna de la cual es opcional) no tiene que
estar almacenada en un único trozo grande. Las versiones
multi-usuario siguientes fueron probadas por los usuarios en
1978 y 1979, tiempo por el que un lenguaje SQL había sido
estandarizado. Las ideas de Codd se revelaron como
operativas y superiores a las de CODASYL, lanzando a IBM al
desarrollo de una verdadera versión de producción de
System R, conocido como SQL/DS, y posteriormente como
Database 2
- Sistemas orientados a
objetos (1980)
- Durante la década de 1980 el auge de la programación orientada a objetos
influyó en el modo de manejar la información de las bases de datos.
Programadores y diseñadores comenzaron a tratar los datos en las bases
de datos como objetos. Esto quiere decir que si los datos de una persona
están en la base de datos, los atributos de la persona como dirección,
teléfono y edad se consideran que pertenecen a la persona, no son datos
extraños. Esto permite establecer relaciones entre objetos y atributos,
más que entre campos individuales.
- Durante la década de 1980 el auge de la programación orientada a objetos
influyó en el modo de manejar la información de las bases de datos.
Programadores y diseñadores comenzaron a tratar los datos en las bases
de datos como objetos. Esto quiere decir que si los datos de una persona
están en la base de datos, los atributos de la persona como dirección,
teléfono y edad se consideran que pertenecen a la persona, no son datos
extraños. Esto permite establecer relaciones entre objetos y atributos,
más que entre campos individuales.
- Sistemas NoSQL (2000)
- El siglo XXI trajo una nueva tendencia en las bases de
datos: el NoSQL. Esta tendencia introducía una línea no
relacional significativamente diferentes de las clásicas.
No requieren por lo general esquemas fijos, evitan las
operaciones join almacenando datos desnormalizados y
están diseñadas para escalar horizontalmente. La mayor
parte de ellas pueden clasificarse como almacenes
clave-valor o bases de datos orientadas a documentos.
- El siglo XXI trajo una nueva tendencia en las bases de
datos: el NoSQL. Esta tendencia introducía una línea no
relacional significativamente diferentes de las clásicas.
No requieren por lo general esquemas fijos, evitan las
operaciones join almacenando datos desnormalizados y
están diseñadas para escalar horizontalmente. La mayor
parte de ellas pueden clasificarse como almacenes
clave-valor o bases de datos orientadas a documentos.
- Sistemas XML (2010)
- las Bases de Datos XML forman un
subconjunto de las Bases de Datos
NoSQL. Todas ellas usan el formato de
almacenamiento XML, que está abierto,
legible por humanos y máquinas y
ampliamente usado para
interoperabilidad. En esta categoría
encontramos: BaseX, eXist, MarkLogic
Server, MonetDB/XQuery, Sedna.
- las Bases de Datos XML forman un
subconjunto de las Bases de Datos
NoSQL. Todas ellas usan el formato de
almacenamiento XML, que está abierto,
legible por humanos y máquinas y
ampliamente usado para
interoperabilidad. En esta categoría
encontramos: BaseX, eXist, MarkLogic
Server, MonetDB/XQuery, Sedna.
- Las bases de datos han estado en uso desde los
primeros días de las computadoras
electrónicas.la mayor parte de los sistemas
originales estaban enfocados a bases de datos
específicas y pensados para ganar velocidad a
costa de perder flexibilidad. Los SGBD originales
sólo estaban a disposición de las grandes
organizaciones que podían disponer de las
complejas computadoras necesarias.
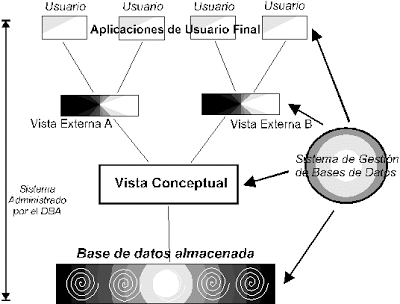
- ARQUITECTURA DEL SISTEMA GESTOR DE BASE DE DATOS
- Interfaces externos
- Medios para comunicarse con el SGDB en ambos
sentidos (E/S) y explotar a todas sus funciones.
Pueden afectar a la base de datos o a la
operación del SGBD
- Medios para comunicarse con el SGDB en ambos
sentidos (E/S) y explotar a todas sus funciones.
Pueden afectar a la base de datos o a la
operación del SGBD
- Operaciones directas con la base de
datos
- Definición de tipos, asignación de niveles de
seguridad, actualización de datos,
interrogación de la base de datos.
- Definición de tipos, asignación de niveles de
seguridad, actualización de datos,
interrogación de la base de datos.
- Operaciones relativas a la operación del SGBD
- Copia de seguridad y restauración,
recuperación tras una caída, monitoreo de
seguridad, gestión del almacenamiento,
reserva de espacio, monitoreo de la
configuración, monitoreo de prestaciones,
afinado... los interfaces externos bien
pueden ser utilizados por usuarios (p.e.
administradores) o bien por programas
que se comunican a través de un API.
- Copia de seguridad y restauración,
recuperación tras una caída, monitoreo de
seguridad, gestión del almacenamiento,
reserva de espacio, monitoreo de la
configuración, monitoreo de prestaciones,
afinado... los interfaces externos bien
pueden ser utilizados por usuarios (p.e.
administradores) o bien por programas
que se comunican a través de un API.
- Optimizador de consultas
- Realiza la optimización de cada pregunta y escoge el plan de actuación
más eficiente para ejecutarlo.
- Realiza la optimización de cada pregunta y escoge el plan de actuación
más eficiente para ejecutarlo.
- Intérprete o procesador del lenguaje
- La mayor parte de las operaciones se efectúan
mediante un lenguaje de base de datos. Existen
lenguajes para definición de datos, manipulación de
datos (p.e. SQL), para especificar aspectos de la
seguridad y más. Las sentencias en ese lenguaje se
introducen en el SGBD mediante el interfaz
adecuado. Se procesan las expresiones en dicho
lenguaje (ya sea compilado o interpretado) para
extraer las operaciones de modo que puedan ser
ejecutadas por el SGBD.
- La mayor parte de las operaciones se efectúan
mediante un lenguaje de base de datos. Existen
lenguajes para definición de datos, manipulación de
datos (p.e. SQL), para especificar aspectos de la
seguridad y más. Las sentencias en ese lenguaje se
introducen en el SGBD mediante el interfaz
adecuado. Se procesan las expresiones en dicho
lenguaje (ya sea compilado o interpretado) para
extraer las operaciones de modo que puedan ser
ejecutadas por el SGBD.
- Motor de la base de datos
- Realiza las operaciones requeridas sobre la base de datos,
típicamente representándolo a alto nivel.
- Realiza las operaciones requeridas sobre la base de datos,
típicamente representándolo a alto nivel.
- Mecanismo de almacenamiento
- Traduce las operaciones a lenguaje de bajo nivel para
acceder a los datos. En algunas arquitecturas el mecanismo
de almacenamiento está integrado en el motor de la base de
datos.
- Traduce las operaciones a lenguaje de bajo nivel para
acceder a los datos. En algunas arquitecturas el mecanismo
de almacenamiento está integrado en el motor de la base de
datos.
- Motor de transacciones
- Para conseguir corrección y fiabilidad la mayoría de las
operaciones internas del SGBD se realizan encapsuladas dentro
de transacciones. Las transacciones pueden ser especificadas
externamente al SGBD para encapsular un grupo de
operaciones. El motor de transacciones sigue la ejecución de las
transacciones y gestiona su ejecución de acuerdo con las reglas
que tiene establecidas (p.e. control de concurrencia y su
ejecución o cancelación).
- Para conseguir corrección y fiabilidad la mayoría de las
operaciones internas del SGBD se realizan encapsuladas dentro
de transacciones. Las transacciones pueden ser especificadas
externamente al SGBD para encapsular un grupo de
operaciones. El motor de transacciones sigue la ejecución de las
transacciones y gestiona su ejecución de acuerdo con las reglas
que tiene establecidas (p.e. control de concurrencia y su
ejecución o cancelación).
- Gestión y operación de SGBD
- Comprende muchos otros componentes que tratan de aspectos
de gestión y operativos del SGBD como monitoreo de
prestaciones, gestión del almacenamiento, mapas de
almacenamiento.
- Comprende muchos otros componentes que tratan de aspectos
de gestión y operativos del SGBD como monitoreo de
prestaciones, gestión del almacenamiento, mapas de
almacenamiento.
- Interfaces externos
- SGBD mas utilizados
- MySQL
- Es un sistema de gestión de base de datos relacional,
multihilo y multiusuario con más de seis millones de
instalaciones. MySQL AB desarrolla MySQL como software
libre en un esquema de licenciamiento dual. Por un lado lo
ofrece bajo la GNU GPL, pero, empresas que quieran
incorporarlo en productos privativos pueden comprar a la
empresa una licencia que les permita ese uso.
- Es un sistema de gestión de base de datos relacional,
multihilo y multiusuario con más de seis millones de
instalaciones. MySQL AB desarrolla MySQL como software
libre en un esquema de licenciamiento dual. Por un lado lo
ofrece bajo la GNU GPL, pero, empresas que quieran
incorporarlo en productos privativos pueden comprar a la
empresa una licencia que les permita ese uso.
- Oracle
- Es un sistema de gestión de base de datos relacional (o RDBMS
por el acrónimo en inglés de Relational Data Base Management
System), fabricado por Oracle Corporation. Características: Se
considera a Oracle como uno de los sistemas de bases de datos
más completos, destacando su: • Soporte de transacciones. •
Estabilidad. • Escalabilidad. • Es multiplataforma. Su mayor
defecto es su enorme precio, que es de varios miles de dólares
(según versiones y licencias)
- Es un sistema de gestión de base de datos relacional (o RDBMS
por el acrónimo en inglés de Relational Data Base Management
System), fabricado por Oracle Corporation. Características: Se
considera a Oracle como uno de los sistemas de bases de datos
más completos, destacando su: • Soporte de transacciones. •
Estabilidad. • Escalabilidad. • Es multiplataforma. Su mayor
defecto es su enorme precio, que es de varios miles de dólares
(según versiones y licencias)
- Microsoft SQL Server
- Es un sistema de gestión de bases de datos relacionales basado en
el lenguaje Transact-SQL, capaz de poner a disposición de muchos
usuarios grandes cantidades de datos de manera simultánea. Así
de tener unas ventajas que a continuación se pueden describir.
- Es un sistema de gestión de bases de datos relacionales basado en
el lenguaje Transact-SQL, capaz de poner a disposición de muchos
usuarios grandes cantidades de datos de manera simultánea. Así
de tener unas ventajas que a continuación se pueden describir.
- Microsoft Access
- Es un sistema de gestión de bases de datos Relacional creado y modificado
por Microsoft (DBMS) para uso personal de pequeñas organizaciones. Es un
componente de la suite Microsoft Office aunque no se incluye en el paquete
“básico”. Una posibilidad adicional es la de crear ficheros con bases de datos
que pueden ser consultados por otros programas.
- Es un sistema de gestión de bases de datos Relacional creado y modificado
por Microsoft (DBMS) para uso personal de pequeñas organizaciones. Es un
componente de la suite Microsoft Office aunque no se incluye en el paquete
“básico”. Una posibilidad adicional es la de crear ficheros con bases de datos
que pueden ser consultados por otros programas.
- MySQL
Recursos multimedia adjuntos
{kind=link}
{kind=link}
{kind=link}
¿Quieres crear tus propios Mapas Mentales gratis con GoConqr? Más información.