5575690
Descripción
Mapa Mental por Natalina Laria, actualizado hace más de 1 año
|
|
Creado por Natalina Laria
hace más de 8 años
|
|
DNA structure, replication and repair
- Structure and properties of DNA
- Genetic information is stored in DNA
- DNA is a macromolecule
- polymer
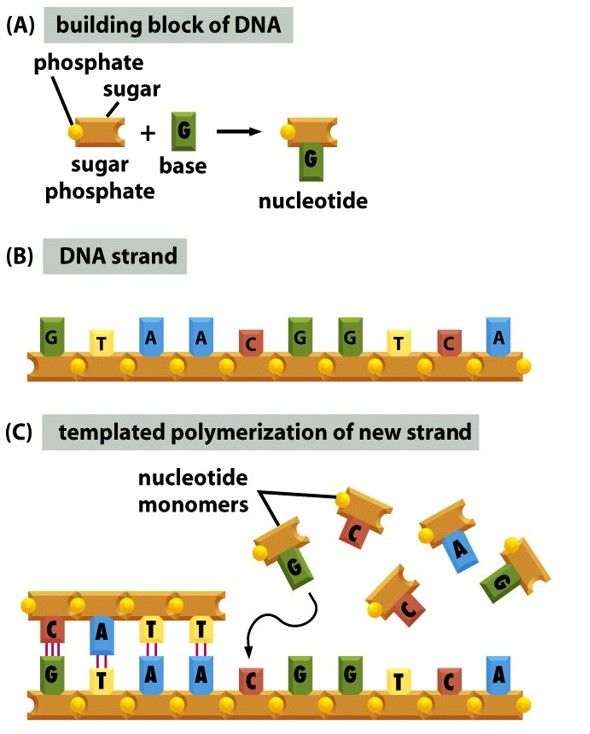
- Monomers are called nucleotides
- Consist of a Phosphate, sugar and base
- Consist of a Phosphate, sugar and base
- Monomers are called nucleotides
- polymer
- Information in DNA is digital
- Each position can be A, T, G or C
- Each position can be A, T, G or C
- Building Blocks of DNA
- DNA is a macromolecule
- DNA stores information in all life forms
- Common mechanisms for storage, replication and expression of genetic information suggest a single
origin for all life however, differences in detail are significant, especially between prokaryotes and
eukaryotes
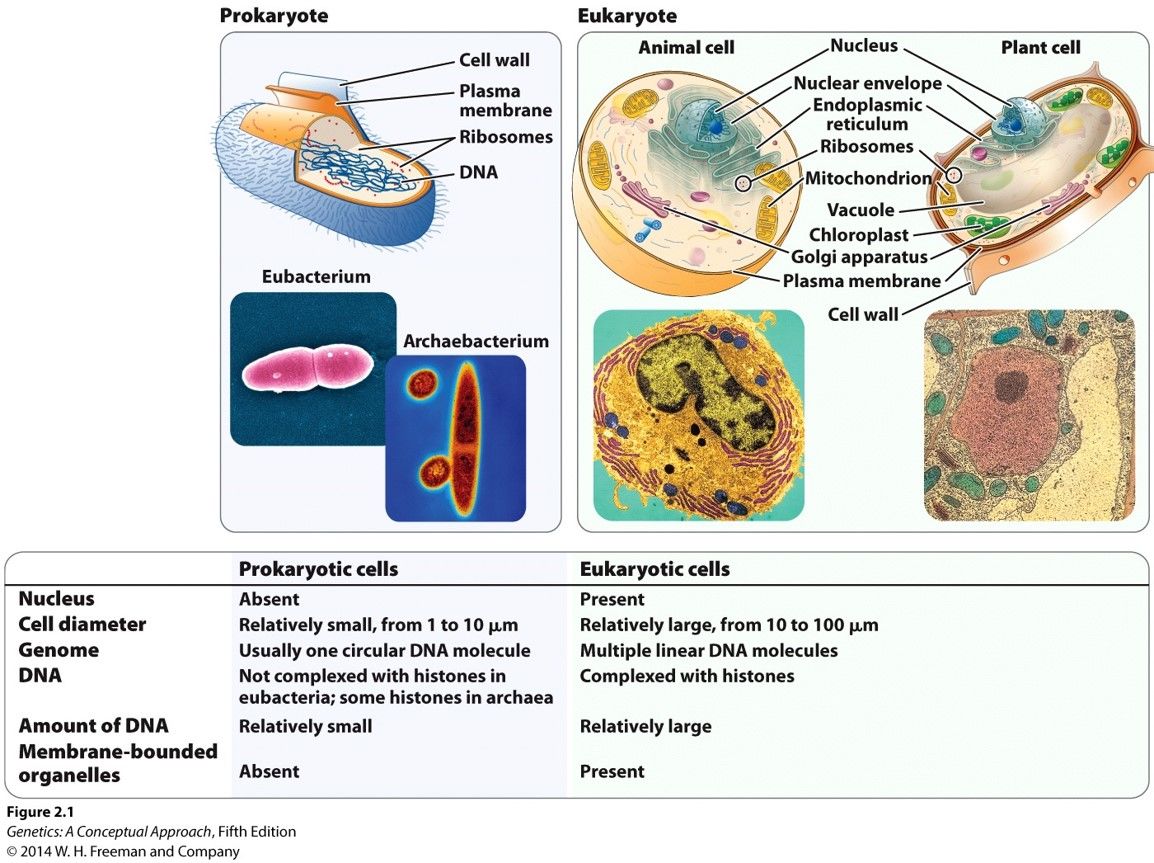
- Prokaryotic and eukaryotic cells
- Prokaryotes have no nucleus Prokaryotes carry less DNA Prolaryotes do not have membrane bound
organelles Prokaryotes usually have 1 circular bacterial chromosome - eukaryotes usually have
multiple linear DNA chromosomes Prokaryotes not complexed by histones Prokaryotic cell diameter
is relatively small
- Prokaryotes have no nucleus Prokaryotes carry less DNA Prolaryotes do not have membrane bound
organelles Prokaryotes usually have 1 circular bacterial chromosome - eukaryotes usually have
multiple linear DNA chromosomes Prokaryotes not complexed by histones Prokaryotic cell diameter
is relatively small
- Prokaryotic and eukaryotic cells
- Common mechanisms for storage, replication and expression of genetic information suggest a single
origin for all life however, differences in detail are significant, especially between prokaryotes and
eukaryotes
- DNA structure and organisation
- Must be stable and protected
- to store genetic
information
- to prevent damage
(mutation)
- to store genetic
information
- Must be accessible
- information can be
used to produce
functional cells
- information can be
used to produce
functional cells
- Must be stable and protected
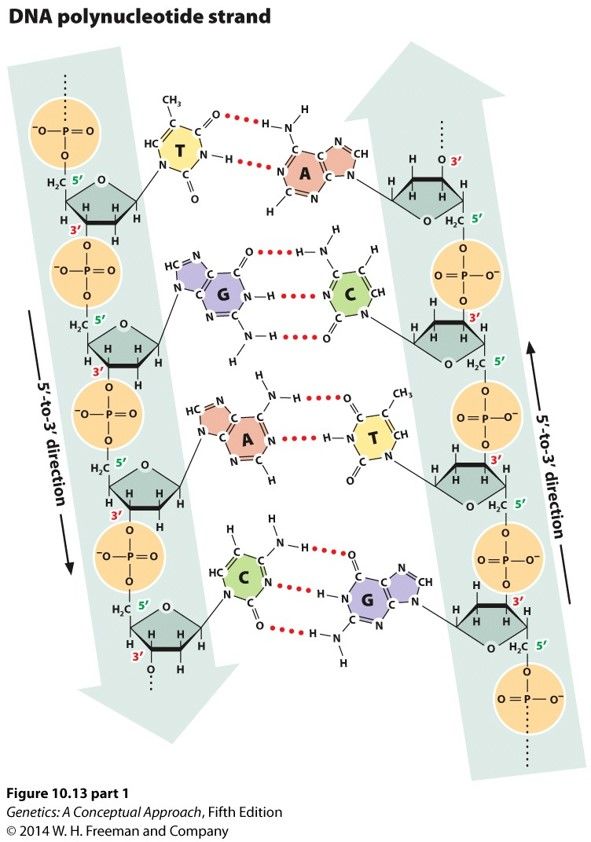
- Native DNA is a
double helix of
complementary
antiparallel chains
- Linked by
hydrogen
bonds
between
the bases
- 3 H bonds in a
G-C pair and 2
H bonds in an
A-T pair
- Linked by
hydrogen
bonds
between
the bases
- Supercoiling of DNA
- Separating the
two strands of
the DNA double
helix causes
supercoiling
- Regulated by Topoisomerases and Gyrases
- Regulated by Topoisomerases and Gyrases
- Separating the
two strands of
the DNA double
helix causes
supercoiling
- DNA packing
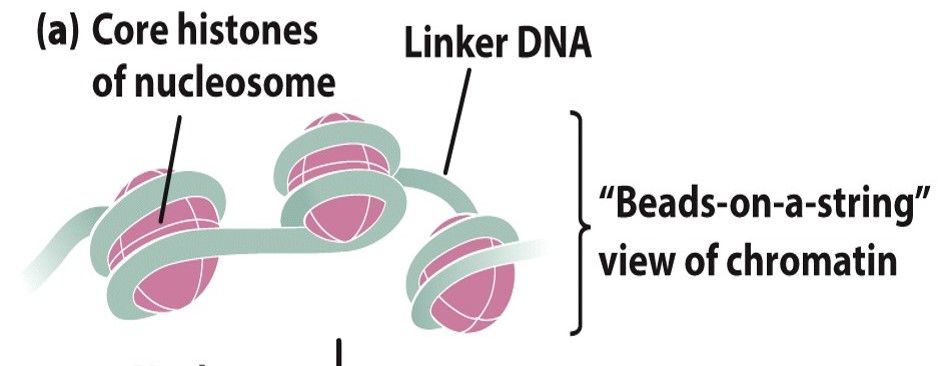
- Nucleosomes
- Small regions
of DNA are
wrapped
around
protein cores
- Look like 'beads on a string'
- Look like 'beads on a string'
- an octamer of two copies of each of
the histones H2A, H2B, H3 and H4
(the nucleosomal histones)
- Histones are
positively
charged
proteins.
- Histone H1 binds outside the
nucleosome and has a
structural role
- Histones are
positively
charged
proteins.
- Small regions
of DNA are
wrapped
around
protein cores
- Role of DNA packing
- DNA is safely stored but easy to access for
transcription and replication
- DNA is safely stored but easy to access for
transcription and replication
- Nucleosomes
- Genetic information is stored in DNA
- DNA replication
- DNA synthesis occurs in the 5’ to 3’ direction
- leading strand is replicated continuously
- lagging strand is replicated discontinuously
- Okazaki fragments
- RNA primer of each Okazaki fragment is replaced with
DNA and the adjacent fragments are joined by DNA ligase
- RNA primer of each Okazaki fragment is replaced with
DNA and the adjacent fragments are joined by DNA ligase
- Okazaki fragments
- DNA synthesis occurs in the
opposite direction to movement
of the replication fork
- leading strand is replicated continuously
- Nucleoside triphosphates are the substrates for DNA synthesis; pyrophosphate is released and the
nucleoside monophosphate is joined onto the growing strand
- Initiation of DNA
replication requires
many different proteins
- Initiator proteins
- Recruits the rest of the
replication machinery
- Recruits the rest of the
replication machinery
- Helicase
- Separates the two strands of
the double helix (breaks
hydrogen bonds)
- Separates the two strands of
the double helix (breaks
hydrogen bonds)
- Topoisomerase (gyrase)
- Relieves supercoiling of DNA by
breaking backbone (covalent
bonds)
- Topoisomerase inhibitors
- Prevent DNA replication
- Blocks topoisomerase I so that supercoils accumulate ahead of the
replication fork, preventing DNA replication
- Blocks topoisomerase I so that supercoils accumulate ahead of the
replication fork, preventing DNA replication
- Prevent DNA replication
- Relieves supercoiling of DNA by
breaking backbone (covalent
bonds)
- Single stranded binding protein
- In a single stranded region of DNA where short regions of base paired
'hairpins' have been formed single stranded binding protein works to
straighten the strand through cooperative protein binding
- In a single stranded region of DNA where short regions of base paired
'hairpins' have been formed single stranded binding protein works to
straighten the strand through cooperative protein binding
- Initiator proteins
- Initiated at origins
- Specific DNA sequence (Usually AT-rich)
- Origin sequences bound
by DNA binding proteins
(initiator proteins)
- Specific DNA sequence (Usually AT-rich)
- Proceeds bidirectionally
- Elongation requires
many different proteins
- Primase
- Primase is recruited to the origin when
the strands have been separated by
helicase
- Primers are laid down 5’ to 3’ on both strands
(bidirectional replication)
- Primase is recruited to the origin when
the strands have been separated by
helicase
- DNA polymerases
- DNA polymerase III
- Main replication polymerase
- Primer extension
- Coordination of leading and
lagging strand synthesis
- The two molecules of DNA pol III (one on each strand)
interact to ensure the two strands replicate together
- The two molecules of DNA pol III (one on each strand)
interact to ensure the two strands replicate together
- Main replication polymerase
- DNA polymerase I
- Replaces RNA primers with DNA
- Exonuclease activity 5’ to 3’ - One nucleotide at a time is removed from
the 5’ end of the primer as one is added to the 3’ end of the preceding
Okazaki fragment (DNA synthesis 5’ to 3’)
- Exonuclease activity 5’ to 3’ - One nucleotide at a time is removed from
the 5’ end of the primer as one is added to the 3’ end of the preceding
Okazaki fragment (DNA synthesis 5’ to 3’)
- Replaces RNA primers with DNA
- Can back up and remove
incorrectly paired bases
- use a 3’ to 5’ exonuclease activity to
remove incorrect bases
- The 3’ end is then extended again as usual
- The 3’ end is then extended again as usual
- use a 3’ to 5’ exonuclease activity to
remove incorrect bases
- In eukaryotes
- DNA pol e on the leading strand and on the
lagging strand DNA pol d
- High fidelity (proof-reading)
enzymes
- High fidelity (proof-reading)
enzymes
- DNA pol e on the leading strand and on the
lagging strand DNA pol d
- DNA polymerase III
- DNA ligase
- Seals the nick between two
Okazaki fragments
- Seals the nick between two
Okazaki fragments
- Primase
- Nucleases - Enzymes that
cut nucleic acids (DNA or
RNA)
- Exonuclease – cuts off one nucleotide at
a time from the end of a DNA molecule
- Endonuclease – cuts internally in a DNA molecule
(may be sequence specific)
- Exonuclease – cuts off one nucleotide at
a time from the end of a DNA molecule
- Replication errors and mismatch repair
- Mismatch repair
- operates soon after replication and distinguishes the
newly replicated strand (carrying the incorrect base) from
the parental, correct strand
- Mismatch repair assumes that the parental strand is correct
- Newly synthesised DNA is methylated but not immediately so Mismatch
repair acts on the non-methylated strand, soon after DNA replication
- Newly synthesised DNA is methylated but not immediately so Mismatch
repair acts on the non-methylated strand, soon after DNA replication
- Mismatch repair assumes that the parental strand is correct
- Hereditary non-polyposis colon cancer (HNPCC) is
due to inherited defects in mismatch repair genes
- operates soon after replication and distinguishes the
newly replicated strand (carrying the incorrect base) from
the parental, correct strand
- Replication strand slippage
- misalignment of the template and newly synthesised
strand and results in unequal daughter strands
- misalignment of the template and newly synthesised
strand and results in unequal daughter strands
- Mismatch repair
- DNA synthesis occurs in the 5’ to 3’ direction
- Replication of chromosome
ends
- The last RNA primer on the
lagging strand cannot be replaced
- Chromosomes have
repeated sequences at each
end, called telomeres
- G-rich (on strand
with its 3’ end at
the chromosome
end)
- Short repeats (6-10 bp)
- G-rich (on strand
with its 3’ end at
the chromosome
end)
- Telomerase
- Reverse transcriptase
- enzyme that uses an RNA template to
make a complementary DNA strand
- enzyme that uses an RNA template to
make a complementary DNA strand
- an enzyme
that
extends
chromosome
ends
by
adding
telomere
repeat
sequences.
- Extends DNA so that strand remains same
size (fills in gap left by lost rna polymerase)
- Reverse transcriptase
- The last RNA primer on the
lagging strand cannot be replaced
- Mutation and DNA repair
- Mutations
- in germ cells will be passed on to offspring
- in somatic cells may cause cancer
- Mutations that disrupt regulation of cell division
may lead to cancer
- Mutations that disrupt regulation of cell division
may lead to cancer
- Base mismatches
- Base excision repair
- the first step is
removal of the
base
- Incorrect/modified bases are
recognised; different errors are
recognised by different glycosylases
- A uracil specific
glycosylase
removes uracil in
the first step.
- This is why DNA contains Thymine. It
makes the repair system able to
distinguish a problem much more
easily
- This is why DNA contains Thymine. It
makes the repair system able to
distinguish a problem much more
easily
- A uracil specific
glycosylase
removes uracil in
the first step.
- the first step is
removal of the
base
- Deamination changes base pairing
properties. This occurs
spontaneously but the rate can be
increased by some chemicals
- Can lead to
point
mutations
- Can lead to
point
mutations
- Base excision repair
- in germ cells will be passed on to offspring
- Causes of mutation
- Replication errors
- Mispairing
or small
insertions
and
deletions
- Mispairing
or small
insertions
and
deletions
- Spontaneous
chemical change to
DNA
- Chemical mutagens
- Radiation
- UV light causes pyrimidine
dimers to form – usually
thymine
- A single unrepaired thymine dimer can be lethal
because progress of high fidelity DNA polymerases is
blocked
- Photoreactivation:
direct
repair
- Not present in humans
- An enzyme (photoreactivating enzyme) uses energy from
visible light to break the bonds between the two
pyrimidine residues
- Direct repair involves
reversing the chemical
reaction causing the
DNA damage
- Photolyase (or
photoreactivating enzyme)
splits the dimer to regenerate
normal DNA
- Direct repair involves
reversing the chemical
reaction causing the
DNA damage
- An enzyme (photoreactivating enzyme) uses energy from
visible light to break the bonds between the two
pyrimidine residues
- Not present in humans
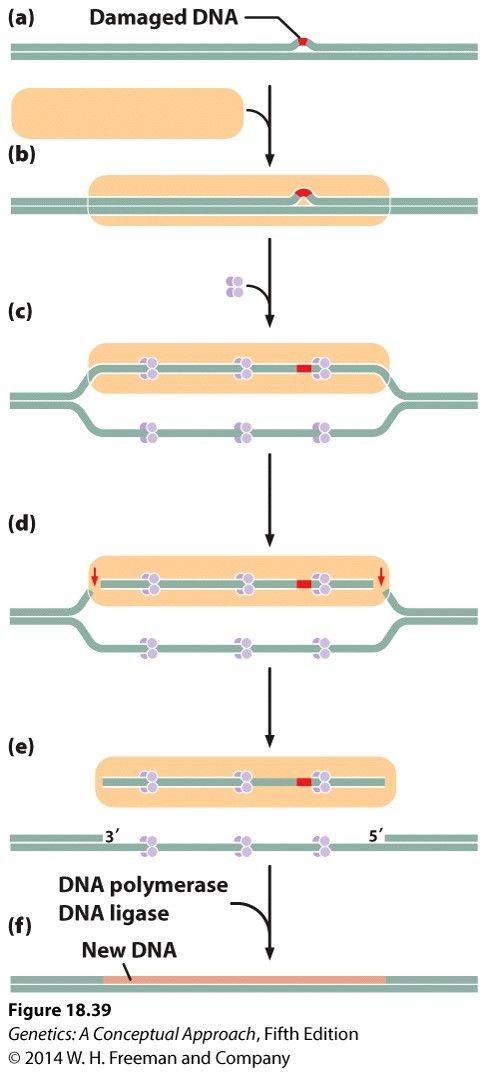
- Nucleotide excision repair
- Detects and repairs bulky lesions in DNA,
eg thymine dimers and modified bases
- 1. Recognition of damage 2. Single strand binding
protein binds 3. Endonuclease cuts out damaged
region 4. New DNA synthesised
- 1. Recognition of damage 2. Single strand binding
protein binds 3. Endonuclease cuts out damaged
region 4. New DNA synthesised
- Detects and repairs bulky lesions in DNA,
eg thymine dimers and modified bases
- Translesion synthesis
- Bases are randomly
incorporated opposite
the lesion (commonly A)
- error-prone mechanism
that introduces mutations
- New strand is
complete but likely to
carry a mutation
- May leave pyrimadine dimer
unrepaired leading to cell
death
- New strand is
complete but likely to
carry a mutation
- Bypasses the blockage of
DNA replication
- Bases are randomly
incorporated opposite
the lesion (commonly A)
- A single unrepaired thymine dimer can be lethal
because progress of high fidelity DNA polymerases is
blocked
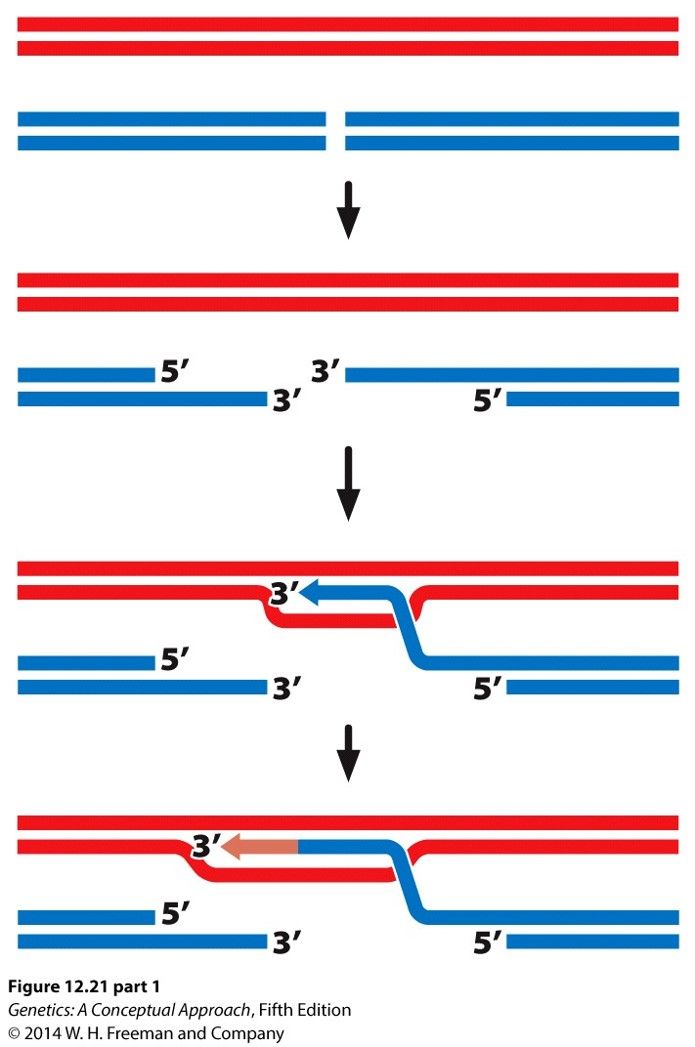
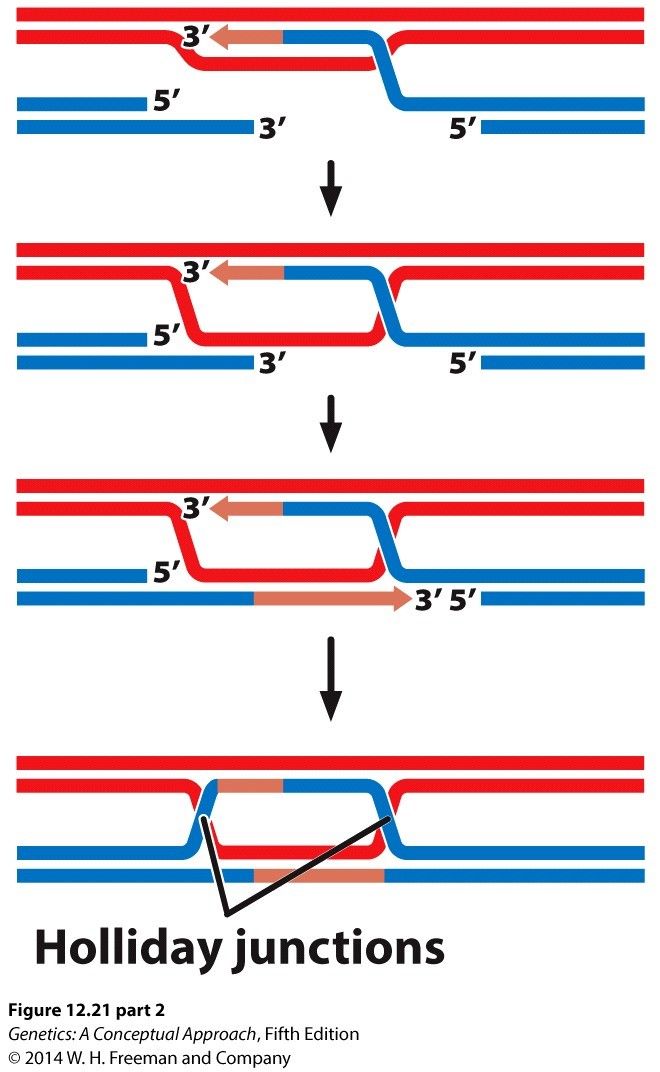
- Double-stranded DNA breaks
- Repaired by Homologous
recombination or Nonhomologous
end-joining
- Homologous recombination results in
exchange of genetic information
between homologous chromosomes
- Recombination provides a
means to generate new
combinations of genes
- generates genetic diversity
- generates genetic diversity
- Blocks of genes are exchanged
between homologous
chromosomes
- Can be used as
a repair system
- When there is a Double
stranded break on one
chromosome The other is
used as a template for
repair, resulting in exchange
of genetic material
- When there is a Double
stranded break on one
chromosome The other is
used as a template for
repair, resulting in exchange
of genetic material
- Recombination provides a
means to generate new
combinations of genes
- Nonhomologous end-joining Protein recognise
broken chromosomes and join the ends together
(no base pairing involved)
- Error prone
- Wrong ends could be
joined, causing
translocations
- Insertions or deletions
may occur during joining
- Wrong ends could be
joined, causing
translocations
- Error prone
- Homologous recombination results in
exchange of genetic information
between homologous chromosomes
- Repaired by Homologous
recombination or Nonhomologous
end-joining
- UV light causes pyrimidine
dimers to form – usually
thymine
- Replication errors
- Mutations
Recursos multimedia adjuntos
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
¿Quieres crear tus propios Mapas Mentales gratis con GoConqr? Más información.