8225961
Descripción
Mapa Mental por Elisa Antolli, actualizado hace más de 1 año
|
|
Creado por Elisa Antolli
hace casi 8 años
|
|
Word2Vec
- RNN
- semplice -> not DNN
- utile per una DNN
- utile per una DNN
- 3 layers: input, hidden,
output
- spazio vettoriale: similitudine matemat.
- rappresentazione distribuita
- rappresentazioni solo 1-to-N sono poche informative
- tante dimensioni che rappresentano "features"
- similitudine tra le "feature"
- con le operazioni giuste posso trovare similitudine SEMANTICHE E SINTATICHE
- es.: [vector(“King”) - vector(“man”) + vector(“woman”)]
- cosine distance
- es.: [vector(“King”) - vector(“man”) + vector(“woman”)]
- con le operazioni giuste posso trovare similitudine SEMANTICHE E SINTATICHE
- rappresentazioni solo 1-to-N sono poche informative
- rappresentazione distribuita
- semplice -> not DNN
- Word Embedding
- diverso dai modelli classici come "n-gram" poichè questi sono discreti
- modello simile ad un "autoencoder"
- codifica le parole in vettori: non si usano string (of course)
- si cerca di ricostruire ciò che è dato come input
- funzione per la codifica e per la decodifca: noi abbiamo solo encoding
- codifica le parole in vettori: non si usano string (of course)
- 2 approcci
- Continuous Bag of
Words
- corpus; vocabolario; frasi; parola target; contesto.
- Modello - 3 layers: Input, Hidden, Output
- INPUT: contesto
- OUTPUT: parola focus
- Obiettivo: Massimizzare la probabilità condizionata
- HIDDEN: media
- "C" input, somma delle linne "1" e divisione per C
- funzione di attivazione lineare
- "C" input, somma delle linne "1" e divisione per C
- INPUT: contesto
- corpus; vocabolario; frasi; parola target; contesto.
- Skip-gram
- Modello - 3 layers: Input, Hidden, Output
- INPUT: parola focus
- OUTPUT: contesto
- Obiettivo: massimizzare l'average log probability - contesti >> parola
- T = lunghezza sentenza (w1,w2,...,wT)
- c = lunghezza max. contesto
- j = indice spostamento
- wt = parola centrale
- Calcolo della probabilità p( wt+j | wt )
- softmax
- Pro: semplice
- Contro: Costo comp. proporzionale alla dim. vocabolario (C)
- Pro: semplice
- hierarchical softmax
- limita n° vettori output che sono aggiornati
- rappresentazione in albero binario
- Pro: invece di valutare "v" parole per vettore (C*v), valuto log(v)
- limita n° vettori output che sono aggiornati
- negative sampling
- softmax
- T = lunghezza sentenza (w1,w2,...,wT)
- Modello - 3 layers: Input, Hidden, Output
- Continuous Bag of
Words
- diverso dai modelli classici come "n-gram" poichè questi sono discreti
Recursos multimedia adjuntos
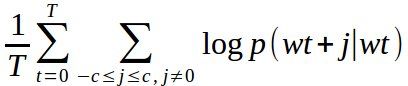{kind=link}
¿Quieres crear tus propios Mapas Mentales gratis con GoConqr? Más información.