10400176
Description
Flashcards by ANGELLY ARAUJO, updated more than 1 year ago
|
|
Created by ANGELLY ARAUJO
about 7 years ago
|
|
| Question | Answer |
| BIG DATA: PROCESAMIENTO Y CALIDAD DE DATOS Gracias al desarrollo del Internet ;nuestros datos tienen mayor volumen , velocidad y variedad. | Una baja calidad de datos, puede causar una mala calidad del conocimiento extraído,algunos factores pueden ser: ruido, valores perdidos,inconsistencias y un tamaño demasiado grande. |
| smart data: gira alrededor de dos im- portantes características, la veracidad y el valor de los datos, cuyo objetivo es filtrar el ruido y mantener los datos valiosos.los cuales son necesarios para la toma de decisiones importantes. El uso de los datos: a) los datos deben ser lo que se dice, es importante la calidad de datos; b) los datos deben ser escalables para su procesamiento; c) los datos deben estar disponibles y preparados para adaptarse;estas son características para datos exactos procesables y ágiles. | El objetivo de este trabajo es presentar la importancia del pre procesamiento de datos en Big Data,también , estudiar las herramientas y técnicas de análisis de datos que soportan la tarea del pre procesamiento de datos masivos. |
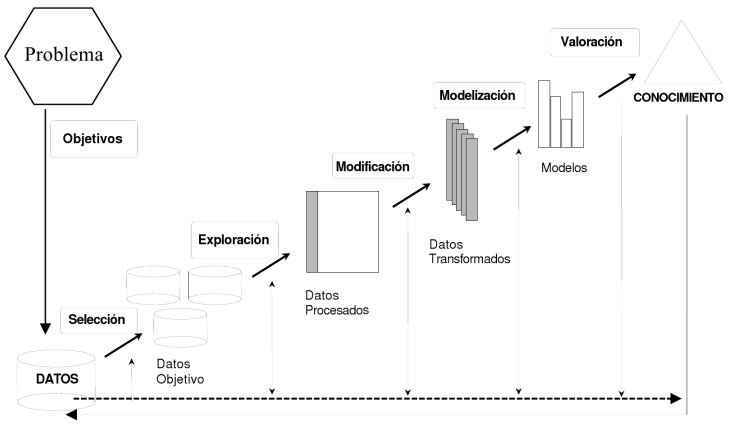
| BIG DATA: *volumen *variedad *veracidad *valor *velocidad | PROCESAMIENTO DE DATOS Esta etapa es esencial y se encarga de la limpieza de datos, su integración, transformación y reducción para la siguiente fase de minería de datos . |
| “La preparación de datos está formada por una serie de técnicas que tienen el objetivo de inicializar correctamente los datos que servirán de entrada para los algoritmos de minería de datos” | El valor del conocimiento extraído es uno de los aspectos esenciales de Big Data. |
| Algunos nuevos escenarios nuevos con presencia de datos masivos son : las redes sociales, el Internet de las cosas y las industrias. | |
| La necesidad de procesar y extraer conocimiento valioso de tal inmensidad de datos se ha convertido en un desafío considerable para científicos de datos y expertos en la materia. | Google diseñó MapReduce en 2003 [8] que es considerada como la plataforma pionera para el procesamiento de datos masivos. |
| Una contribución reseñable para el preprocesamiento de datos masivos, y en particular, para selección de atributos, es el algoritmo fast-mRMR . | Son necesarios nuevos algoritmos que deben centrarse en problemas tales como la selección de instancias o el tratamiento de datos imperfectos (ruido y valores perdidos). |
| Smart Data son datos de calidad, prestos para ser utilizados en la extracción de conocimiento y la toma de decisiones inteligente basada en datos. | CONCLUSIÓN: ¡Decisiones de calidad deben estar soportadas por datos de calidad! |
{kind=link}
Want to create your own Flashcards for free with GoConqr? Learn more.