32644372
Description
Flashcards by FRANCISCO JAVIER VALENCIA GARCIA, updated more than 1 year ago
|
|
Created by FRANCISCO JAVIER VALENCIA GARCIA
over 3 years ago
|
|
| Question | Answer |
| UNIVERSIDAD DE LAS AMÉRICAS Y DEL CARIBE ESTADÍSTICA APLICADA A LA INVESTIACIÓN | DOCTOR: ALEXÁNDER OROBIO DOCTORANDO: FRANCISCO JAVIER VALENCIA DOCTORADO EN LA ENSEÑANZA DE LAS MATEMÁTICAS |
|
Capítulo 3 Estadística descriptiva: medidas numéricas
Audio:
Audio Clip 2 (audio/mpeg)
|
LA ESTADÍSTICA EN LA PRÁCTICA SMALL FRY DESIGN* SANTA ANA, CALIFORNIA Fundada en 1997, Small Fry Design es una empresa de juguetes y accesorios que diseña e importa productos para niños pequeños. En un resumen reciente sobre el estado de las cuentas por cobrar se presentaron los siguientes estadísticos descriptivos sobre el tiempo que tenían las facturas pendientes. Media 40 días, Mediana 35 días y Moda 31 días La interpretación de dichos estadísticos indica que el tiempo promedio de una factura pendiente es 40 días. La mediana revela que la mitad de las facturas se quedan pendientes 35 días o más. La moda, 31 días, muestra que el tiempo que con más frecuencia permanece pendiente una factura es 31 días. |
| Medidas de localización Media muestral |
La medida de localización más importante es la media, o valor promedio, de una variable. La
media proporciona una medida de localización central de los datos.
Image:
C31 (binary/octet-stream)
|
| Ejemplo de la media muestral |
Image:
C35 (binary/octet-stream)
|
| Media poblacional |
Para calcular la media de una población use la misma fórmula, pero con una notación diferente para indicar que trabaja con toda la población. El número de observaciones en una población se denota N y el símbolo para la media poblacional es μ.
Image:
C32 (binary/octet-stream)
|
| Mediana |
La mediana es otra medida de localización central. Es el valor de enmedio en los datos ordenados de menor a mayor (en forma ascendente).
Image:
C33 (binary/octet-stream)
|
| Ejemplo de la mediana |
Image:
C34 (binary/octet-stream)
|
| Moda | La tercera medida de localización es la moda. La moda se define como sigue.La moda es el valor que se presenta con mayor frecuencia. |
| Ejemplo de la moda | Para ilustrar cómo identificar a la moda, considere la muestra del tamaño de los cinco grupos de la universidad. El único valor que se presenta más de una vez es el 46. La frecuencia con que se presenta este valor es 2, por lo que es el valor con mayor frecuencia, entonces es la moda. Para ver otro ejemplo, considere la muestra de los sueldos iniciales de los recién egresados de la carrera de administración. El único salario mensual inicial que se presenta más de una vez es $3480. Como este valor tiene la frecuencia mayor, es la moda. Hay situaciones en que la frecuencia mayor se presenta con dos o más valores distintos. Cuando esto ocurre hay más de una moda. Si los datos contienen más de una moda se dice que los datos son bimodales. Si contienen más de dos modas, son multimodales. En los casos multimodales casi nunca se da la moda, porque dar tres o más modas no resulta de mucha ayuda para describir la localización de los datos. |
| Percentiles | Un percentil aporta información acerca de la dispersión de los datos en el intervalo que va del menor al mayor valor de los datos. El percentil p es un valor tal que por lo menos p por ciento de las observaciones son menores o iguales que este valor y por lo menos (100 - p) por ciento de las observaciones son mayores o iguales que este valor. |
| Ejemplo de percentiles |
Image:
C36 (binary/octet-stream)
|
| Cuartiles | Con frecuencia es conveniente dividir los datos en cuatro partes; así, cada parte contiene una cuarta parte o 25% de las observaciones. En la figura 3.1 se muestra una distribución de datos dividida en cuatro partes. A los puntos de división se les conoce como cuartiles y están definidos como sigue: Q1 primer cuartil, o percentil 25 Q2 segundo cuartil, o percentil 50 Q3 tercer cuartil, o percentil 75 |
| Ejemplo de cuariles |
Image:
C37 (binary/octet-stream)
|
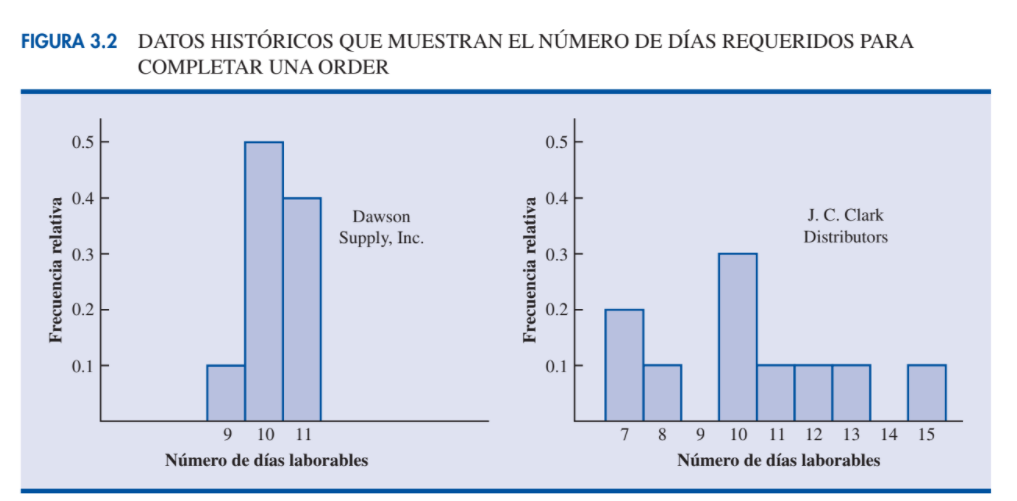
| Medidas de variabilidad | Además de las medidas de localización, suele ser útil considerar las medidas de variabilidad o de dispersión. Suponga que usted es el encargado de compras de una empresa grande y que con regularidad envía órdenes de compra a dos proveedores. Después de algunos meses de operación, se percata de que el número promedio de días que ambos proveedores requieren para surtir una orden es 10 días. |
| Ejemplo de medidas de variabilidad |
En la figura 3.2 se presentan los histogramas que muestran el número de días que cada uno de los proveedores necesita para surtir una orden. Aunque en ambos casos este número promedio de días es 10 días, ¿muestran los dos proveedores el mismo grado de confia-
bilidad en términos de tiempos para surtir los productos? Observe la dispersión, o variabilidad, de estos tiempos en ambos histogramas. ¿Qué proveedor preferiría usted?
Image:
C38 (binary/octet-stream)
|
| Rango | La medida de variabilidad más sencilla es el rango. Este se calcula así: Rango (R) = Valor mayor -Valor menor |
| Ejemplo de rango | De regreso a los datos de la tabla 3.1 sobre sueldos iniciales de los recién egresados de la carrera de administración, el mayor sueldo inicial es 3925 y el menor 3310. El rango es 3925 -3310 = 615. |
| Rango intercuartílico |
Una medida que no es afectada por los valores extremos es el rango intercuartílico (RIC). Esta medida de variabilidad es la diferencia entre el tercer cuartil Q3 y el primer cuartil Q1. En otras palabras, el rango intercuartílico es el rango en que se encuentra el 50% central de los datos.
Image:
C39 (binary/octet-stream)
|
| Ejemplo de rango intercuartílico | En los datos de los sueldos mensuales iniciales, los cuartiles son Q3 3600 y Q1 3465. Por lo tanto el rango intercuartílico es 3600 - 3465 = 135. |
| Varianza poblacional |
La varianza es una medida de variabilidad que utiliza todos los datos. La varianza está basada en la diferencia entre el valor de cada observación (xi) y la media. La varianza sirve para comparar la variabilidad de dos o más variables.
En la mayor parte de las aplicaciones de la estadística, los datos a analizar provienen de una
muestra. Cuando se calcula la varianza muestral, lo que interesa es estimar la varianza poblacional σ2.
Image:
C310 (binary/octet-stream)
|
| Varianza muestral |
La varianza muestral s2 es
el estimador de la varianza
poblacional σ2 .
Image:
C311 (binary/octet-stream)
|
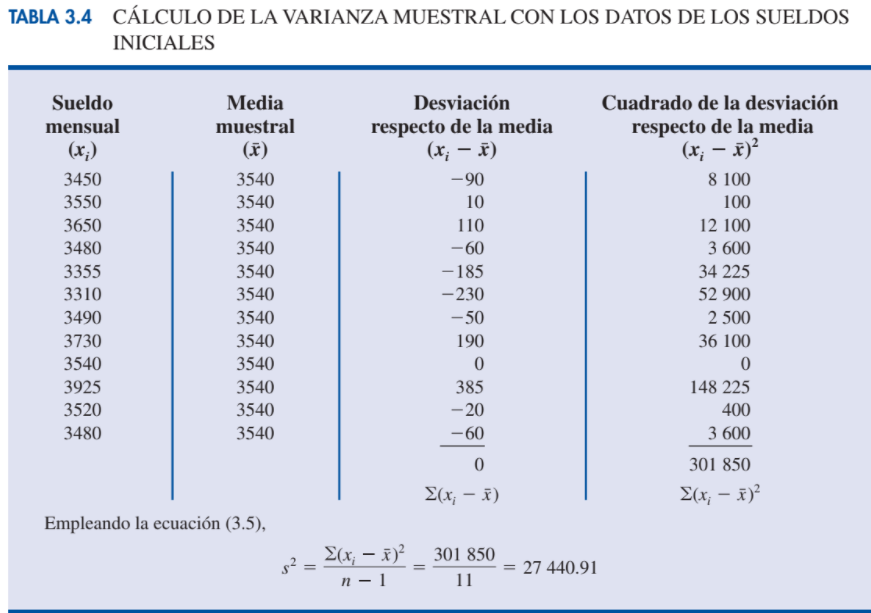
| Ejemplo de la varianza muestral |
Image:
C315 (binary/octet-stream)
|
| Desviación estándar La desviación estándar es más fácil de interpretar que la varianza debido a que la desviación estándar se mide en las mismas unidades que los datos. |
Se define como la raíz cuadrada positiva de la varianza. Continuando
con la notación adoptada para la varianza muestral y para la varianza poblacional, se emplea S para denotar la desviación estándar muestral y σ para denotar la desviación estándar poblacional.
Image:
C313 (binary/octet-stream)
|
| Ejemplo de desviación estándar |
Image:
C314 (binary/octet-stream)
|
| Coeficiente de variación |
El coeficiente de variación es una medida relativa de la variabilidad; mide la desviación estándar en relación con la media.
Image:
C316 (binary/octet-stream)
|
| Ejemplo de coeficiente de variación | En los datos de los tamaños de los cinco grupos de estudiantes, se encontró una media muestral de 44 y una desviación estándar muestral de 8. El coeficiente de variación es [(8/44) x 100]%=18.2%. Expresado en palabras, el coeficiente de variación indica que la desviación estándar muestral es 18.2% del valor de la media muestral. |
|
Capítulo 10:
Audio:
Audio Clip 3 (audio/mpeg)
|
Inferencia estadística acerca de medias y de proporciones con dos poblaciones. La estadística tiene un papel muy importante en la investigación farmacéutica, para la cual existen disposiciones gubernamentales estrictas y rigurosas. En las pruebas preclínicas suelen emplearse pruebas estadísticas en las que intervienen dos o tres poblaciones para determinar si se debe continuar con las pruebas de uso prolongado y confiabilidad del nuevo medicamento. |
| Inferencias acerca de la diferencia entre dos medias poblacionales: σ1 y σ2 conocidas | Sean μ1 la media de la población 1 y μ2 la media de la población 2, lo que interesa aquí son inferencias acerca de la diferencia entre las medias: μ1 μ2. Para hacer una inferencia acerca de esta diferencia, se elige una muestra aleatoria simple de n1 unidades de la población 1 y otra muestra aleatoria simple de n2 unidades de la población 2. |
| Estimación por intervalo de μ1 μ2 |
La estimación puntual de la diferencia entre las dos medias poblacionales es la diferencia entre las dos medias muestrales.
Image:
C101 (binary/octet-stream)
|
| Error estándar |
El error estándar de x 1 - x2 es la desviación
estándar de la distribución
muestral de x1 y x2.
Image:
C102 (binary/octet-stream)
|
| Marge de error |
El margen de error se
obtiene multiplicando el
error estándar por zα/2.
Image:
Cn5 (binary/octet-stream)
|
| Prueba de hipótesis |
Image:
Cn6 (binary/octet-stream)
|
| Estadístico de prueba |
Image:
Cn (binary/octet-stream)
|
| Inferencias acerca de la diferencia entre dos proporciones poblacionales | Sea p1 una proporción de la población 1 y p2 una proporción de la población 2, a continuación se considerarán inferencias acerca de la diferencia entre dos proporciones poblacionales: p1 p2. Para las inferencias acerca de estas diferencias, se seleccionan dos muestras aleatorias independientes, una de n1 unidades de la población 1 y otra de n2 unidades de la población 2. |
| Estimación por intervalo para p1 p2 |
Image:
T (binary/octet-stream)
|
| Error estándar |
Image:
R (binary/octet-stream)
|
| Margen de error |
Aproximando la distribución muestral de P1- P2 mediante una distribución normal, se podrá usar como margen de error zα/2 , Sin embargo, como es dada por la ecuación (10.11) no se puede usar directamente porque no se conoce ninguna de las dos proporciones poblacionales p1 y p2. Usando la proporción muestral 1 para estimar p1 y la proporción muestral 2 para estimar p2, el margen de error queda como sigue.
Image:
S (binary/octet-stream)
|
| Estimación por intervalo |
Image:
A (binary/octet-stream)
|
| Ejemplo de intervalo de confianza |
Image:
Cf (binary/octet-stream)
|
| Prueba de hipótesis |
Image:
Tr (binary/octet-stream)
|
| Error estándar |
Image:
W (binary/octet-stream)
|
| Estimador combinado de p |
Image:
X (binary/octet-stream)
|
| Estadístico de prueba |
Image:
P (binary/octet-stream)
|
| Ejemplo de estadístico de prueba |
Image:
Pr (binary/octet-stream)
|
{kind=link}
{kind=link}
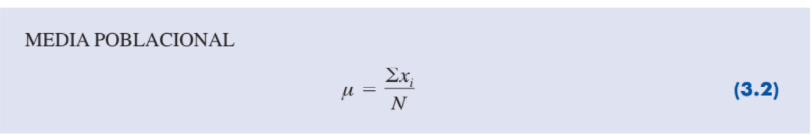{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
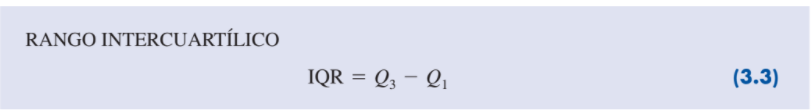{kind=link}
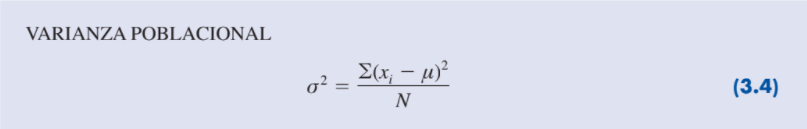{kind=link}
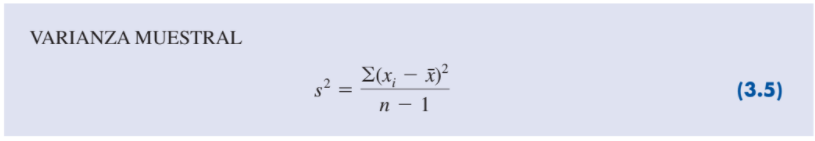{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
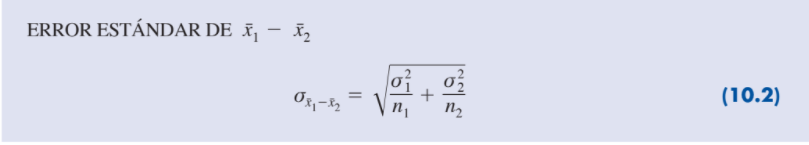{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
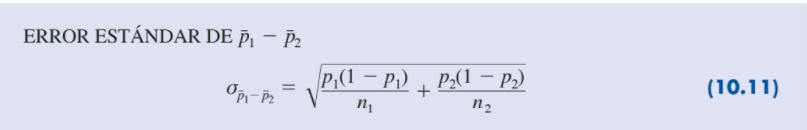{kind=link}
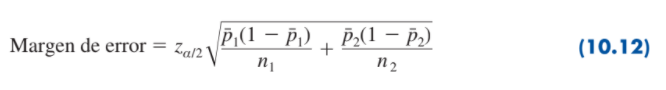{kind=link}
{kind=link}
{kind=link}
{kind=link}
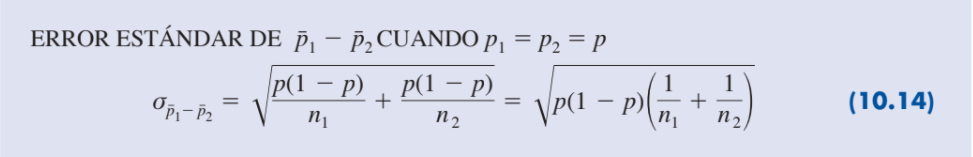{kind=link}
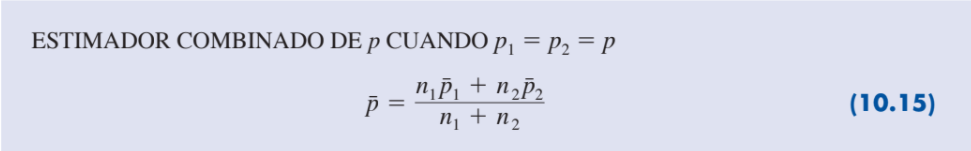{kind=link}
{kind=link}
{kind=link}
Want to create your own Flashcards for free with GoConqr? Learn more.