37873861
Description
Flashcards by Recursos UC, updated more than 1 year ago
|
|
Created by Recursos UC
about 2 years ago
|
|
| Question | Answer |
| Computación de alto rendimiento | Implica el uso agregado de ordenadores muy poderosos (super-ordenadores) o clústeres de cómputo distribuidos geográficamente para la resolución de problemas que requieren mucho cómputo y análisis de grandes volúmenes de datos. |
| Computación voluntaria | Modelo de cómputo distribuido y ubicuo en el que voluntarios distribuidos en el mundo donan su capacidad computacional ociosa a proyectos científicos. |
| Ejemplos de proyectos de computación voluntaria | Los proyectos pioneros en computación voluntaria son GIMPS (Great Internet Mersenne Prime Search) – 1996, para el descubrimiento de números primos muy grandes; Distributed.net – 1997, en el área de criptografía; SETI@home (Search for Extraterrestrial Intelligence) – 1999 – se detuvo en marzo 2020, buscaba vida extraterrestre; Folding@home (análisis de plegamiento de proteínas) y genome@home (proyecto del genoma humano) – 2000. |
| Computación en malla | Grid computing es un modelo de cómputo distribuido y ubicuo en el que organizaciones distribuidas en el mundo comparten sus recursos computacionales locales (capacidad de procesamiento, capacidad de almacenamiento, repositorios de datos, recursos computaciones especializados, etc.) para desarrollo de proyectos científicos de interés común. |
| Computación en la nube | Cloud computing es un modelo de cómputo distribuido y ubicuo en el que un proveedor con recursos distribuidos los ofrece como servicios a usuarios dispersos en el mundo para satisfacer sus requerimientos particulares de recursos. Los usuarios pagan por los recursos que usan y no deben mantenerlos localmente. |
| Computación en la nube | El NIST (National Institute of Standard and Technology en U.S) define cloud computing como el modelo cloud 5-3-4: 5 características fundamentales (amplio acceso a la red, elasticidad rápida, servicios a la medida, servicios bajo demanda, pool de recursos), 3 modelos de servicios (IaaS, PaaS, SaaS) y 4 modelos de despliegue (pública, privada, híbrida, comunitaria). |
| Modelos de datos | Big Data implica datos que se presentan en formatos que difícilmente pueden ser tratados por DBSM tradicionales, dado que no están organizados en formatos de tablas y la estructura puede variar (estructurados, semiestructurados y no estructurados), se generan en tiempo real en flujos continuos y provienen de distintas fuentes (dispositivos móviles, sensores, PCs, Laptops, objetos...) de forma desordenada y no predecible. Esto demanda el uso de diferentes modelos de representación de datos: SQL y NoSQL. |
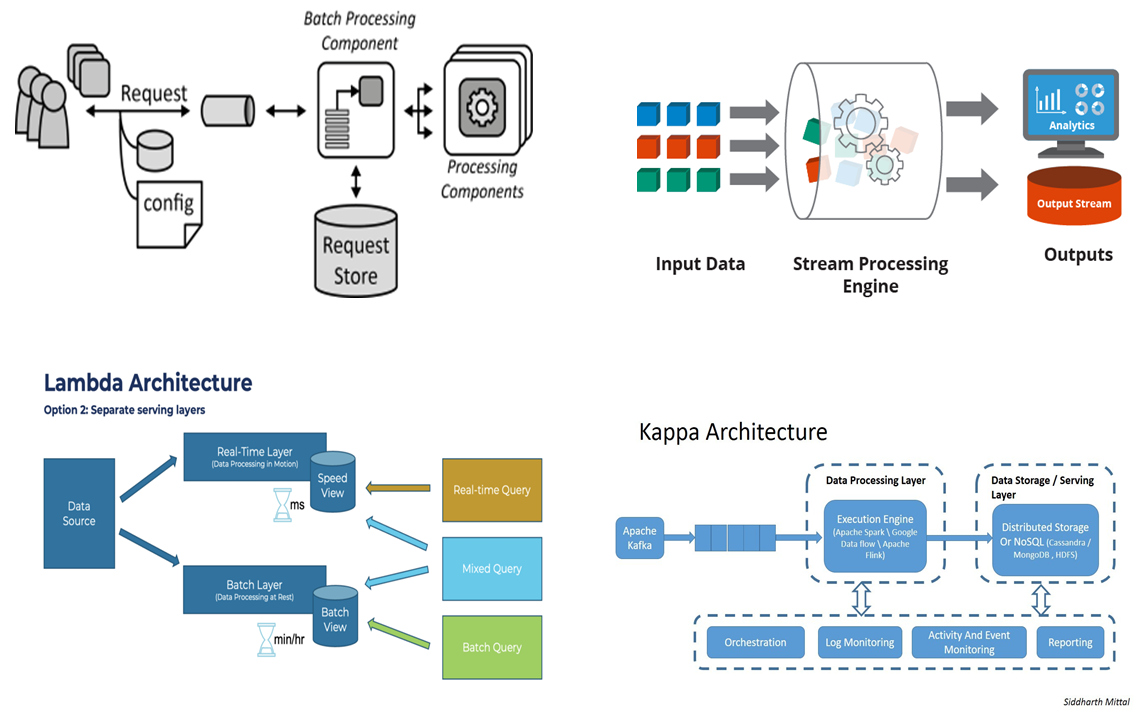
| Modelos de procesamiento | Big data implica nuevas formas de procesar los datos. Procesamiento batch, en el que los datos se recolectan, se almacenan y se procesan luego. Procesamiento en streaming, en el que los datos se procesan al momento que se generan. Procesamiento transaccional, en el que los datos se acceden con pequeñas transacciones que cumplen las propiedades ACID. Procesamiento hibrido que combina batch y streaming, como las arquitecturas Lambda y Kappa. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Want to create your own Flashcards for free with GoConqr? Learn more.