3600240
| Question | Answer |
| Why Use SEM? | • SEM allows the use of esoteric designs not available in normal techniques • SEM makes clearer, more pure estimates of variances, covariances, and if asked, means and intercepts |
| What is SEM? | • SEM is a procedure where we – Measure an important variable, like a DV – Specify some theoretical relationship – Estimate the variables that fit the relationship – Then CHECK how strongly the ESTIMATED variables AGREE with the ACTUAL variables |
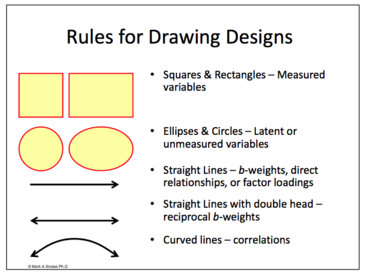
| What objects are used to draw a model in AMOS and what do they represent? | |
| Specifying a SEM model What features can be estimated in SEM? | means and intercepts variances and error covariances and factor loadings |
| Specifying a SEM model What do models consist of? | a structural model and/or a measurement model The structural model consists of all the latent variables and the relationships between them, and between them and the measured model The measurement model consists of all the measured variables and their error terms |
| what inferences do SEM models consist of? | latent variables errors, variances of observed variables disturbances, variance of latent or unobserved variables |
| What form can variables take in SEM? | observed unobserved exogenous (unexplained variables) endogenous (explained variables) |
| What are: observed-exogenous variables observed-endogenous variables unobserved-endogenous variables observed-exogenous variables? | |
| what are the three classes of relationships that exist between variables in a SEM model? | covariances or correlations direct factor loadings reciprocal factor loadings |
| How does SEM work? | • In SEM we fit some statistical model to the measured data. • The degree of agreement between the model and the data is called fit measured by the Chi square goodness of fit test |
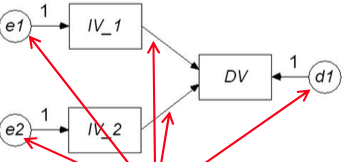
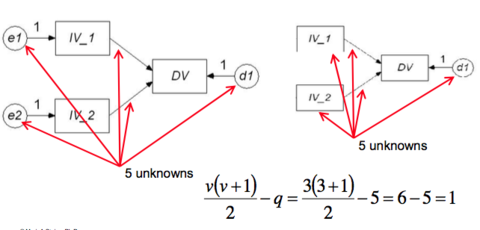
| What is identification in SEM? | •A model with more parameters than observations has df < = 0 & cannot be measured • Such a model is not identified Observations are measured variables and covariances between them Parameters are relationships |
| What is an over-identified model? | • model has more observations than it has parameters to be estimated |
| What is a just-identified model? | • model has the same number of observations as parameters – called a saturated model. |
| What is an under-identified model? | • model has fewer observations than it has parameters |
| What is different in identification in non-recursive models | an equal number of observations and parameters may result in an under-identified model recursive models only include unidirectional effects (causality flows one way) |
| Is this model identified? | over identified |
| Is this model identified? | just identified |
| Is this model identified? | under identified |
| What are model degrees of freedom? | |
| When considering sample size in SEM which two options are advised? | 1. The number of subjects should exceed the number of variables (observations) N > v or 2. The power rule for multiple regression N > (or = ) 50 + (v.8) this gives power = 0.80 for effect size = 0.20 & alpha = 0.05 |
| What is the factor analysis approach to sample size? | • Factor analysis approach • N=50 as poor N=100 as fair N=200 as good & N=300 as excellent |
| What are the regression approaches to sample size? | Estimation techniques • Asymptotically Distribution-Free Criterion – Requires at least 500 subjects, and better with 2000 (used for non-parametric data) • Satorra-Bentler approach (odd non-parametric data, biased normal data, kurtosis) – Requires at least 500 subjects • Maximum Likelihood, Ordinary Least Squares, General Least Squares – Requires at least 100 subjects |
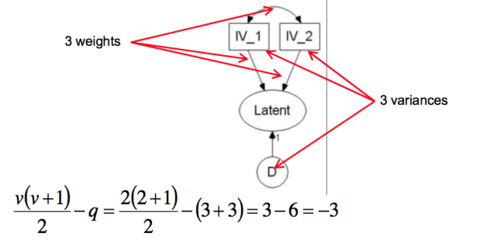
| What is the formula for the number of observations from a set of variables? | |
| What is factor analysis? | used to develop an understanding of the underlying themes (latent constructs) of a measure. Latent constructs/themes are referred to as factors in FA |
| What is exploratory factor analysis? | Factor analysis conducted on collected data used to generate theory from the data |
| What is confirmatory factor analysis? | • Confirmatory Factor Analysis (CFA) is type of SEM that relates specifically to Factor Analysis. • CFA allows the researcher to develop a model where the factor structure of a measure can be evaluated. |
| Does the term 'measurement model' refer to EFA or CFA? | CFA CFA allows the researcher to develop a model where the factor structure of a measure can be evaluated. |
| Is CFA theory generating or theory confirming? | Theory confirming CFA imposes theory (some hypotheses) about how the questionnaire items load (sort) onto factors |
| How is CFA different to EFA? | – CFA is a hypothesis testing procedure whereby the researcher designates which items will load on which factors – measurement models are thus specified a priori unlike EFA – CFA accounts for measurement error in each item of the scale and in the factors themselves |
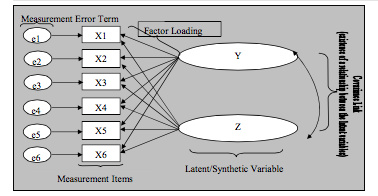
| Does this represent CFA or EFA and why? | EFA Variables (items) load on each factor to determine which they belong to |
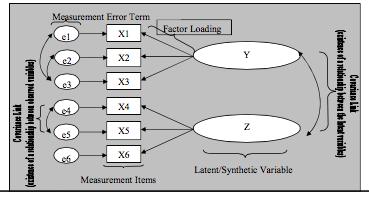
| Does this represent CFA or EFA and why? | CFA Observed variables load onto separate factors (determined by theory) can estimate error observed items can covary (error terms) |
| How do we test CFA model fit? | Chi-square goodness of fit between the implied measurement model and the data |
| What is factor and error scaling? | a unit of measure for the latent and error terms |
| Why do you need factor and error scaling? | A unit of measure is needed to generate factor loadings any arbitrary number can be used by 1 is the most common error scaling is usually done automatically by the program but the researcher sets the factor scales |
| What is a specification search in CFA? | If a model is a poor fit a series of statistics can be examined to understand the source. The statistics are: Modifications indices Expected parameter change (EPC) The standardised residual covariance matrix post-hoc respecifications can only be made on the basis of theory |
| What is the MI statistic? | Modification Indices (Langrage multiplier) A Chi-square value and represents the approximate reduction in the chi- square ML if the modification was to be specified. |
| At what value of the MI do you modify the model? | – there are no clear rules as to the value that an MI should be to consider specifying a given modification – some programs specify a threshold value of 4.00 this is because the critical value for a significant chi-square difference at 1 df is 3.84 Byrne (2001) suggests that values ≥ 10 are worth considering an alternative is to examine the range of MIs and specify modifications for those MIs that seem well outside the modal range |
| What is the expected parameter change statistic? | Represents the unstandardised expected parameter value of the change if it were to be estimated in the model. – this value doesn’t tell us anything about the overall chi-square. It’s just the estimation of what that value would be – the value may either either be positive or negative for each of the fixed parameters in the model bigger is better |
| What is the standardised residual covariance matrix | Provides the average amount of error (the difference) between the relationships in the real data matrix and your hypothesised/implied matrix |
| At what value of the standardised residual covariance matrix do you modify the model? | generally values above 2.0 are regarded as large (2 SD apart) a good fitting model would have about 95% of the standardised residual covariance values fall between +/- 2.0 |
| When does respecification of a CFA model commence? | as soon as you make any changes to the model |
| What are the two ways to change a CFA model? | 1. Model Building - adding links to the model 2. Model Trimming - deleting aspects of the model (paths or variables) if they no longer make a significant contribution to the model |
| What are the benefits to trimming a CFA model? | It makes the model more parsimonious and less complex Some fit indices penalise a model that is complex |
| What is the process for modifying a CFA model | Always build before you trim. – First look at the MIs, EPCs and zresidual covariance matrix to determine what parameters need to be freely estimated • But... After every modification you make to the model, you must test to see if the change has done anything to the model: – in the case of model building you want the addition of a pathway to significantly improve the model – in the case of model trimming you want the deletion to result in non- significance o this tells you that the path or variable was not making a significant contribution, so getting rid of it should make no difference to the model |
| How do you know if modification to a CFA model has had an impact? | You must test to see if each change has done anything to the model: – in the case of model building you want the addition of a pathway to significantly improve the model – in the case of model trimming you want the deletion to result in non- significance o this tells you that the path or variable was not making a significant contribution, so getting rid of it should make no difference to the model |
| How do you test significance of the change to a CFA model? | The significance test conducted to examine the effect of adding or deleting a pathway is a chi-square difference test (∆X2). • Generally, in adding or deleting a pathway you are either reducing or increasing the degrees of freedom by 1. • Thus, whenever you perform a ∆X2 test the X2critical = 3.84 for a change of 1 df. |
| Which table in the AMOS output shows the factor loadings? | Unstandardised regression coefficients table shows if items make a significant contribution to the factors |
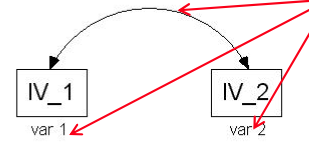
| When analysing the MIs & EPC covariances in CFA models what suggested respecifications are impossible to make? | Correlations between errors and factors, you can only correlate errors with errors |
| When analysing the MIs & EPC regression co-efficients in CFA models what suggested respecifications are impossible to make? | Factor loadings from one item to another item, factor loadings can only occur between item and factor |
| What are the minimum requirements for a one factor CFA model to be identifiable? | A minimum of three uncorrelated indicators (items/observed variables) are required with four items or more, errors can be correlated |
| What are the minimum requirements for a two or more factor CFA model to be identifiable? | Two items can be loaded onto each factor providing each factor is correlated with at least one other factor – generally three indicators per latent factor is recommended for identifiability |
| How might multicollinearity show up in SEM | Out of range correlations (r more than 1 or -1) Negative variances (SD < 0) Non-positive definite matrices (error message) |
| How do you know a SEM model is misspecified? | Model Chi-square is increased by the degree the model is misspecified basically a poorer fitting model |
| What is the SEM process? | 1. check measurement model eg. no neg. variances (multicollinearity) , missing data etc. 2. Specify inferred paths and structure 3. Run the model 4. Refine the model to check all possible models and exclude misspecified models |
| SEM Interpretation What is NPAR? | number of parameters |
| SEM interpretation What is CMIN? | The Chi-square |
| SEM interpretation What p values are ideal? | non significant values indicates no significant difference between the model and the data |
| SEM interpretation What is CMIN/DF | Indicates remaining error per degree of freedom the smaller the better (0-3 is acceptable) |
| SEM interpretation What is the independence model? | ascientific model Theory: Nothing is related to anything No parameters are assumed fits are poorest possible Error is maximum, chi-square = variance |
| SEM interpretation What is the saturated model? | Theory: Everything is related to everything maximum parameters are assumed fits are best possible error is minimum, chi-square = 0 |
| SEM interpretation What is the default model? | Theory: As specified parameters are specified by user fits and error result from specification error is dependent, chi-square = ? |
| What is multi-level modelling (MLM)? | A flexible framework to model relationships between variables in situations where data are clustered – Multilevel regression, – Multilevel path analysis, – Multilevel CFA, etc. |
| What is clustering (MLM)? | Sometimes referred to as nesting or hierarchies, data may be referred to as having hierarchical or nested structure |
| How does MLM model clusters? | • MLM effectively models natural hierarchies or clusters within dataset by: (1) recognising which variables belong at different levels of the model, and (2) separating variance in the DV |
| What type of variable is used in a MLM general linear mixed model? | continuous |
| What type of variable is used in a MLM generalised linear mixed model? | categorical |
| What is a MLM fixed effect? | a parameter (intercept or slope) is consistent across clusters • Can also think of the fixed effect as the average effect across all clusters • Sometimes, the fixed effect will be sufficient because although we have different clusters, the relationship of interest is roughly the same magnitude across clusters – e.g., the relationship between motivation and performance is of the same magnitude across classes |
| What is a MLM random effect? | a parameter that varies across groups • MR forces parameters to be fixed; MLM allows for fixed and random effects • Sometimes we need both fixed and random effects in hierarchical datasets, other times a fixed effect is sufficient • Intra-class correlations (ICCs) and significance testing of random effects useful for determining need for random effects |
| What are cross level interactions? | interactions between variables measured at different levels in hierarchically structured data e.g. interaction between a student characteristic and a teacher characteristic |
| Why do we use centring in MLM? | To aid interpretation prevent multicollinearity customary at level 1 optional at level 2 (has no impact on multicollinearity, still useful for interpretation) |
| What is grand mean centring? | Scores are centred using the grand mean (subtracted from original scores) retains shape and dispertion of raw data |
| What is group mean centring? | Scores are centred using group means (original score - group mean) alters shape and dispertion of raw data |
| When would you use grand mean centring? | Your primary interest is a level 2 predictor and you just want to control for level 1 predictors preferable for level 2 interactions |
| When would you use group mean centring? | When you are interested in level 1 associations The group mean is more meaningful than the grand mean preferable for level 1 effects and cross-level interactions |
| What is the problem with group mean centring? | It removes between-individual variation in the level 1 DV-IV relationship To recover this include group mean scores for IV at level 2 |
| What are the benefits of MLM? | MLM can model variability in regression slopes Errors don't need to be independent Does not require complete data sets |
| What is the intraclass correlation? | The ICC is a measure of whether a contextual variable (level 2 variable) is having an effect on the outcome Measures the variability within the cluster and compares it with variability between clusters Small ICC = small impact of contextual variable |
| When do you use MLM? | When the data is in a hierarchical structure When data are clustered errors are unlikely to be uncorrelated can answer novel research questions poorly handled by GLM-based analysis |
| What are the advantages of MLM over a single level regression for clustered data? | The problem with using a single level regression is that it assumes independence of errors If this assumption is violated, N is overestimated and it can lead to an inflated type I error rate Atomistic fallacy |
| What are the advantages of MLM over a regression using just the clusters? | Reduction in power (smaller sample size) leading to increased type II error rate Ignores variability within the class ecological fallacy |
| What are the advantages of MLM over a corrective approach/adjustment to standard errors (Huber-white sandwich estimate)? | It can accommodate random effects Can use level 2 variables to predict random effects (cross level interactions) Uses information at level 2 that would be missed with the correction MLM is necessary if you want to quantify the level of variation in the level 1 relationship across clusters and account for this variation using level 2 variables |
| What is the ecological fallacy? | An ecological fallacy (or ecological inference fallacy) is a logical fallacy in the interpretation of statistical data where inferences about the nature of individuals are deduced from inference for the group to which those individuals belong. |
| What is the atomistic fallacy? | An erroneous inference about causal relationships in groups made on the basis of relationships observed in individuals |
| What are the assumptions of MLM? | 1. MR assumptions apply to all levels of MLM (outlier, normality, multicollinearity, linearity, homoscedasticity) 2. Correlated predictors are especially problematic 3. Groups (at higher levels) assumed to be random sampling of all possible groups 4. Random sampling of participants 5. Random effects are normally distributed 6. Suitability of MLM for dataset |
| What are the sample size recommendations for MLM? | Power increases with number of groups at level 2 rather than increasing numbers of individuals At least 50 groups at level 2 to test cross-level interactions (random effects) For fixed effects (interested in level 1effects only) 20 groups will be enough |
| How do you know if MLM is a suitable approach? | ICC above .05 if ICC = 0 use standard multiple regression ICCs range from 0 - 1 |
| How do you assess the predictors in MLM? | t-test (fixed effects) Wald z-test (random effects/can be unreliable) model comparison (chi-square approach) - compare with and without the IV of interest |
| What are the issues with effect size estimation in MLM? | can result in negative R2 values need to centre predictors to prevent confounding error can increase when IVs are added in SPSS output need to assume slopes are fixed Snider & Bosker formula produces positive R2 values |
{kind=link}
{kind=link}
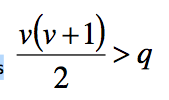{kind=link}
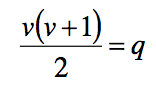{kind=link}
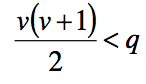{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
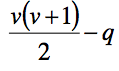{kind=link}
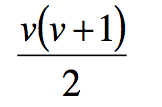{kind=link}
{kind=link}
{kind=link}
Want to create your own Flashcards for free with GoConqr? Learn more.