626708
Description
Flashcards by Thomas Welford, updated more than 1 year ago
|
|
Created by Thomas Welford
over 10 years ago
|
|
| Question | Answer |
| What is does the sigma factor do in the 'Transcription cycle in bacteria'? | Protein needed for the initiation of RNA synthesis, allows binding between RNA polymerase to gene promoters |
| What is the consensus sequence? | The bases that appear most often in the promoter collection |
| Where do the sigma factors interact with the DNA? | -10 and -35 hexametric elements |
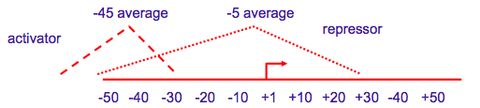
| Where do repressors and activators bind? (picture) | |
| Where do repressors and activators bind? | Activators bind upstream or partially overlapping region (-35 region) Repressors usually bind overlapping or downstream from promoter region |
| Where do most searches for regulatory elements focus on? | <300bp upstream of translation start |
| How is transcription initiation controlled? | each regulator controls a regulon e.g. Lac I controls lac operon (one or two other genes) |
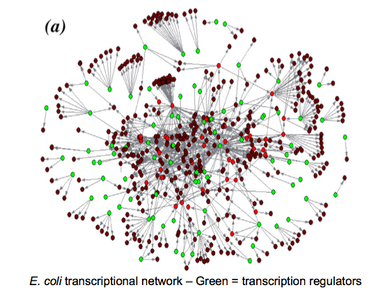
| What does the E.coli transcriptional network look like? | |
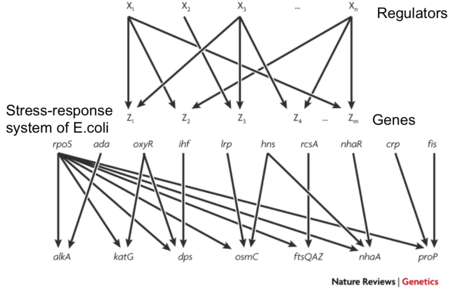
| What is a DOR? | Dense Overlapping Regulons A set of regulators control a group of target genes, where each gene is controlled by two or more of the regulators |
| What is a DOR (picture)? |
Image:
Untitled (image/png)
|
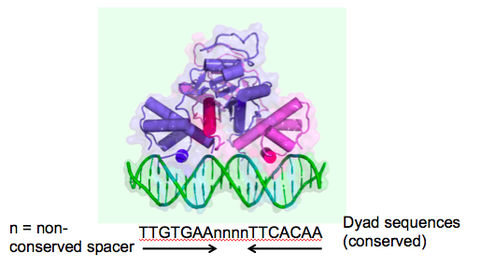
| Why are most DNA binding sites bipartite? | So can bind to more parts of the DNA |
| What do the bipartite DNA binding sites recognise? | Dyad sequences (highly conserved) that are separated by a non-conserved spacer |
| What does the interaction between a DNA binding complex and a dyad sequence look like? | |
| Do most sites match the consensus sequence? | NO - most regulators bind to a range of sites and have a range of affinities |
| How do you represent DNA motifs? | Visually - WebLOGO Sequence Patterns Position Specific Weighted Matrices (PSWM) |
| How do 'sequence patterns' work? | String of sequence using four nucleotides Variation captured using IUPAC codes |
| What is a disadvantage of sequence patterns? | Does not capture quantitative information on a particular position |
| How do you conduct a PSWM? | Capture frequency of nucleotides at each position |
| What is the IUPAC? | Code for representing degenerate nucleotide sequence patterns |
| What is a DNA sequence motif? | Short reoccurring patterns in DNA |
| How do you conduct a PSSM? | Start with data used to create consensus Related sites discovered using a search engine Align sequences then score each position Introduce pseudo counts Introduce background frequency |
| What do 'pseudocounts and background frequency of particular nucleotide in genome' solve? | Product of score for each does not equal 0 Score does not account for background GC content of genome |
| What is the formula used to work out PSSM? | Score (position, nucleotide) = (q+p) / (N + B) q=observed counts for nucleotide p=weighted pseudocounts=B*(overall frequency of nucleotide) B = total number of allocated pseudocounts N = total number of sequences (max number of observed counts) TOTAL SCORE = PRODUCT OF SCORE AT EACH POSITION |
| How do we identify regulatory motifs? | 1) Intra-genome searches for conserved motifs - DYADS 2) Inter-genome alignments of orthologues |
| What do the approaches for 'identifying regulatory motifs' rely on? | most DNA binding proteins bind to related sequences - SPECIFICALLY |
| When conducting an intra-genome search for dyads, what do we search for? | W1 NX W2 W1 = 3-5 nt sequence NX = spacer with any nucleotide of X nt length W2 = 3-5 nt sequence |
| What are "intra-genome searches for dyads" limited to ? | <300bp from translation start point |
| For "Intra-genome searches for dyads" what does statistical significance depend on? � | Length and GC content of Dyad Context of search e.g. length and GC content of upstream regions |
| What happens following identification of groups of significant dyads? � | cluster into subgroups based on conservation in surrounding nucleotides |
| What can a PSSM be used for within Intra-genome searches for dyads ? | Search for additional targets |
| What is an "Inter-genome comparison of - orthologues"? � | Genome sequences of groups of related but distinct (e.g. Genus level) make this very powerful method |
| What is the best approach to identify regulator motifs? | genome-wide ChIP analysis |
| What happens if "genome-wide ChIP analysis" is not available? � | 1) Known consensus sequence / PSSM generated using a limited data set 2) Microarray data indicating co-expressed genes (transcriptome analysis) |
| What are the benefits of a string search? | Can include mismatches and IUPAC symbols Can quickly identify close matches NOT good for degenerate motifs |
| What is a 'string search'? | Query is a string of nucleotides derived from consensus e.g. GTGnnnnCAC |
| PSSM-based search � | Query is a matrix-based pattern Weighted nature increases sensitivity Can identify degenerate motifs Trade-off between sensitivity and specificity |
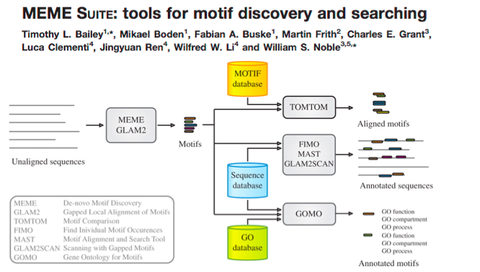
| What web based tools can be used for motif discovery and searching? |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Want to create your own Flashcards for free with GoConqr? Learn more.