15024817
Description
Mind Map by Luis Fernando Santuario Parra, updated more than 1 year ago
|
|
Created by Luis Fernando Santuario Parra
over 6 years ago
|
|
Recurrent Neural Network (RNN)
- ¿Qué es?
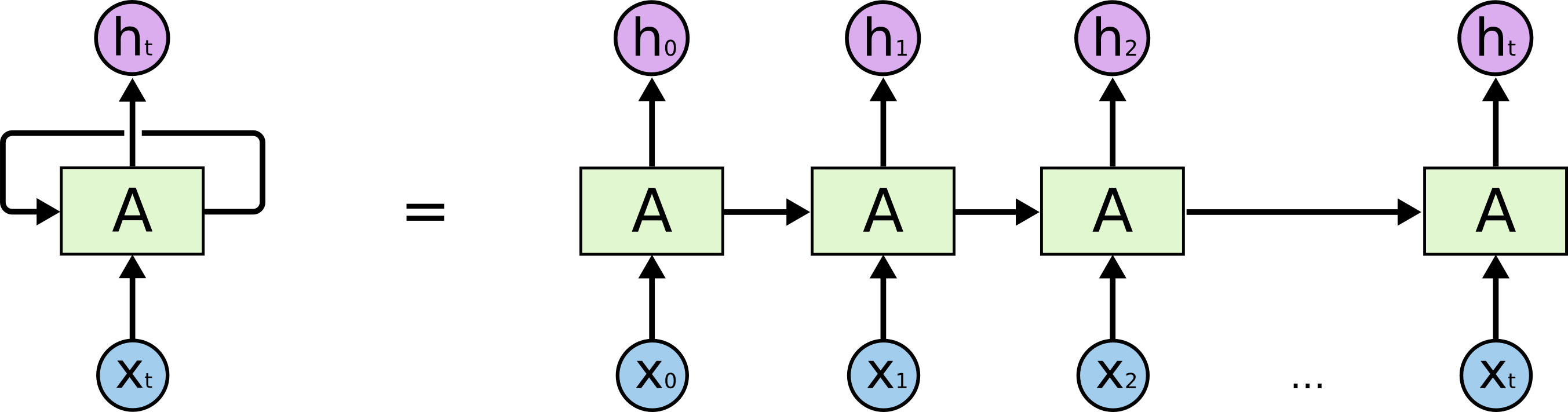
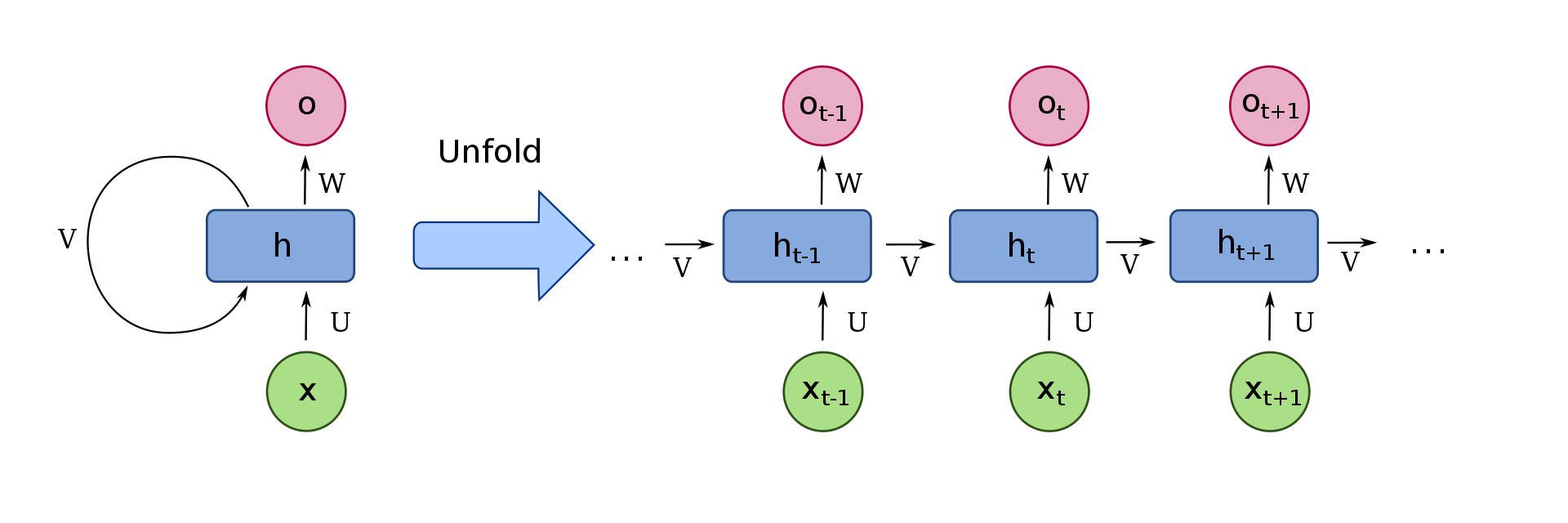
- Las RNN son un tipo de redes neuronales que poseen un ciclo que permite que la
información persista, este tipo de redes neuronales a pesar de que parecen algo
sorprendente no son tan diferentes de las redes neuronales comunes, de echo la
arquitectura de una red neuronal recurrente (RNN) se puede considerar como
múltiples copias de una misma red, de las cuales cada una pasa información a su
sucesor, dicho en otras palabras es una red neuronal cuyas salidas están
conectadas a sus entradas por lo cual tienen retroalimentación como se muestra
en la figura siguiente:[1][3]
- Las RNN son un tipo de redes neuronales que poseen un ciclo que permite que la
información persista, este tipo de redes neuronales a pesar de que parecen algo
sorprendente no son tan diferentes de las redes neuronales comunes, de echo la
arquitectura de una red neuronal recurrente (RNN) se puede considerar como
múltiples copias de una misma red, de las cuales cada una pasa información a su
sucesor, dicho en otras palabras es una red neuronal cuyas salidas están
conectadas a sus entradas por lo cual tienen retroalimentación como se muestra
en la figura siguiente:[1][3]
- Origenes
- Las redes neuronales recurrentes surgen en la
década de los 80's y en 1982 Hopfield desarrolla
las redes neuronales del mismo nombre que
hacen uso de las RNN las cuales se usan como
sistemas de memoria asociativa, estas redes
neuronales fueron originalmente inspiradas en la
física estadística en qué datos almacenados se
recuperan por asociación con los datos de
entrada, en lugar de por una dirección. [1][2][3]
- Las redes neuronales recurrentes surgen en la
década de los 80's y en 1982 Hopfield desarrolla
las redes neuronales del mismo nombre que
hacen uso de las RNN las cuales se usan como
sistemas de memoria asociativa, estas redes
neuronales fueron originalmente inspiradas en la
física estadística en qué datos almacenados se
recuperan por asociación con los datos de
entrada, en lugar de por una dirección. [1][2][3]
- Principales Capacidades
- Clasificador
- Regresor
- Clasificador
- Entre las principales
aplicaciones de las RNN
podemos encontrar [4]
- Time series anomaly detection
- Generating Sequences with recurrent neural networks
- Grammar learning
- Protein Homology Detection
- Time series prediction
- Imagen Captioning
- Procesamiento de lenguaje Natural
- Time series anomaly detection
- Las Redes neuronales recurrentes (RNN)
poseen diversas variantes entre las que
podemos destacar las siguientes: [2][4]
- RNN totalmente Recurrente: Es una red de nodos
organizados en capas sucesivas las cuales están
conectadas a cada otro nodo de la siguiente capa.
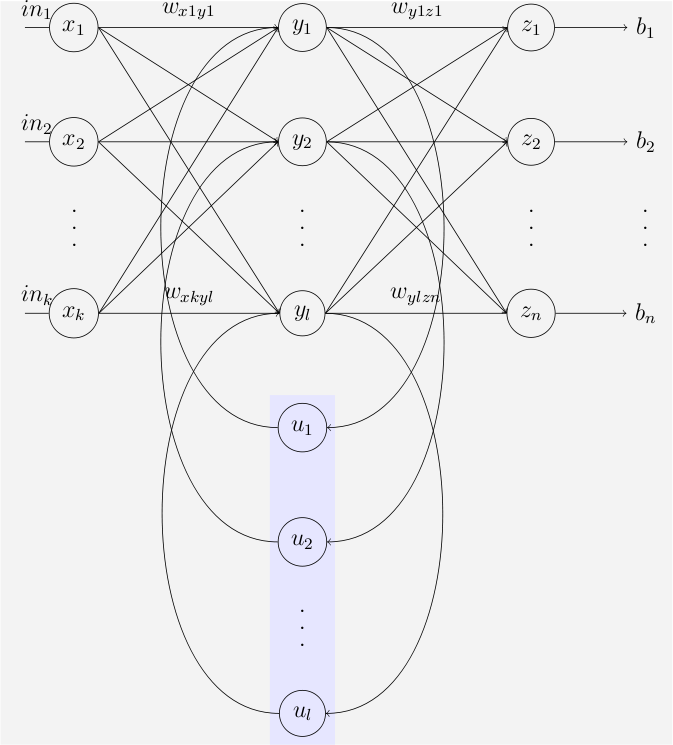
- Redes de Elman y Jordania: Este tipo de redes neuronales
recurrentes se conocen también como "redes recurrentes
simples" y esta organizada en tres capas dispuestas
horizontalmente como X,Y y Z
- RNN independiente: Este tipo de neuronas se caracteriza
porque cada una de ellas es independiente de la historia
de la otra evitando de esta manera los problemas de la
RNN tradicional
- RNN de segundo orden: Este tipo de RNN permite un
mapeo directo a una maquina de estados finitos y un
ejemplo de esto es la memoria a corto plazo, sin embargo
no tiene pruebas de estabilidad ni asignaciones formales
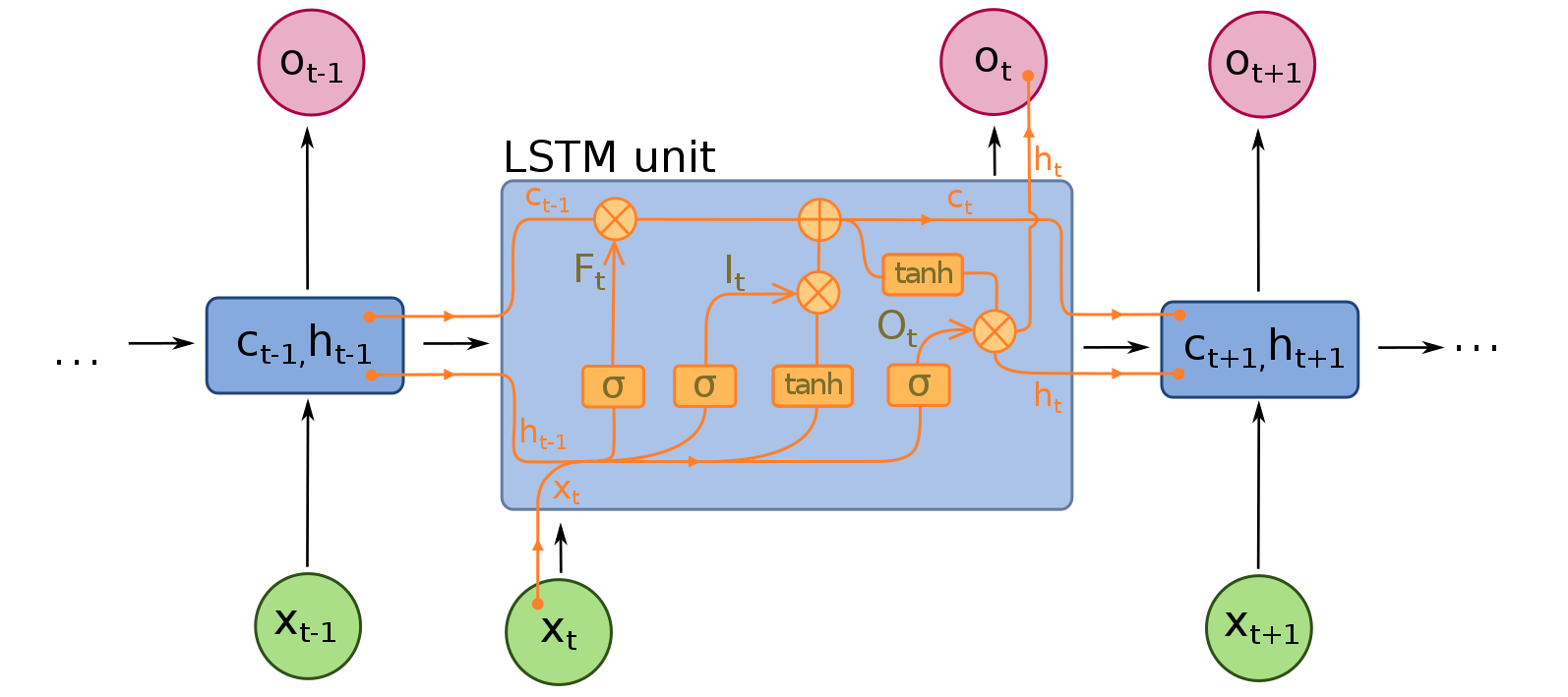
- Larga memoria a corto plazo(LSTM): La unidad LSTM
común se compone de una celda , una puerta de entrada ,
una puerta de salida y una puerta de olvido . La célula
recuerda los valores en intervalos de tiempo arbitrarios y
las tres puertas regulan el flujo de información dentro y
fuera de la celda
- RNN totalmente Recurrente: Es una red de nodos
organizados en capas sucesivas las cuales están
conectadas a cada otro nodo de la siguiente capa.
- Algoritmos de aprendizaje que usa
- Gradient descent
- Simplemente se usa para encontrar los valores de los parámetros
de una función (coeficientes) que minimizan una función de costo
en la medida de lo posible. Mide el cambio en todos los pesos con
respecto al cambio en el error. También puede pensar en un
gradiente como la pendiente de una función. Cuanto más alto es
el gradiente, más pronunciada es la pendiente y más rápido
puede aprender un modelo. Pero si la pendiente es cero, el
modelo deja de aprender.[5]
- Simplemente se usa para encontrar los valores de los parámetros
de una función (coeficientes) que minimizan una función de costo
en la medida de lo posible. Mide el cambio en todos los pesos con
respecto al cambio en el error. También puede pensar en un
gradiente como la pendiente de una función. Cuanto más alto es
el gradiente, más pronunciada es la pendiente y más rápido
puede aprender un modelo. Pero si la pendiente es cero, el
modelo deja de aprender.[5]
- Global optimization methods
- El entrenamiento de los pesos en una red neuronal se puede modelar como
un problema de optimización global no lineal . Se puede formar una función
objetivo para evaluar la aptitud o error de un vector de peso particular
- El entrenamiento de los pesos en una red neuronal se puede modelar como
un problema de optimización global no lineal . Se puede formar una función
objetivo para evaluar la aptitud o error de un vector de peso particular
- Gradient descent
- Lenguajes de programación en los que se ha usado
- Python
- https://github.com/dennybritz/rnn-tutorial-rnnlm/
- https://pythonprogramming.net/rnn-tensorflow-python-machine-learning-tutorial/?completed=/recurrent-neural-network-rnn-lstm-machine-learning-tutorial/
- https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/content/recurrent_neural_networks.html
- https://github.com/dennybritz/rnn-tutorial-rnnlm/
- Matlab
- https://github.com/yabata/pyrenn/archive/master.zip
- https://github.com/yabata/pyrenn/archive/master.zip
- Python
- Referencias
- [1]"Understanding LSTM Networks -- colah's blog", Colah.github.io, 2018. [Online]. Available:
https://colah.github.io/posts/2015-08-Understanding-LSTMs/. [Accessed: 09- Sep- 2018].
- [2]"Recurrent neural network", En.wikipedia.org, 2018. [Online]. Available:
https://en.wikipedia.org/wiki/Recurrent_neural_network#cite_note-schmidhuber1993-5.
[Accessed: 09- Sep- 2018].
- [3]M. Hagan, H. Demuth, M. Beale and O. De Jesús, Neural network design. [S. l.: s. n.], 2016.
- [4]"RNN and its applications", Es.slideshare.net, 2018. [Online]. Available:
https://es.slideshare.net/samchoi7/rnnerica. [Accessed: 09- Sep- 2018].
- [5]"Gradient Descent in a Nutshell – Towards Data Science", Towards Data Science, 2018.
[Online]. Available:
https://towardsdatascience.com/gradient-descent-in-a-nutshell-eaf8c18212f0. [Accessed: 11-
Sep- 2018].
- [1]"Understanding LSTM Networks -- colah's blog", Colah.github.io, 2018. [Online]. Available:
https://colah.github.io/posts/2015-08-Understanding-LSTMs/. [Accessed: 09- Sep- 2018].
- Santuario Parra Luis Fernando 3CM1
Media attachments
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Want to create your own Mind Maps for free with GoConqr? Learn more.