37939494
Description
Mind Map by montserrat elizondo romero, updated more than 1 year ago
|
|
Created by montserrat elizondo romero
about 3 years ago
|
|
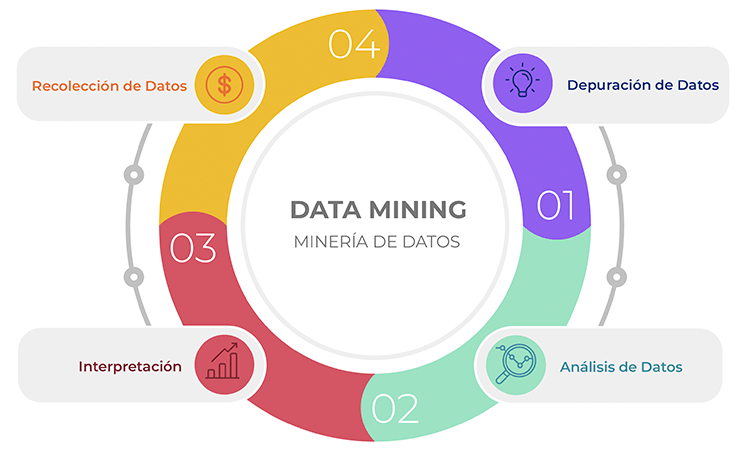
DATA MINING
- La minería de datos o data mining es un proceso técnico, automático
o semiautomático, que analiza grandes cantidades de información
dispersa para darle sentido y convertirla en conocimiento
- Busca anomalías, patrones o correlaciones entre millones de
registros para predecir resultados, como indica el SAS Institute,
uno de los referentes mundiales en analítica de negocios.
- Busca anomalías, patrones o correlaciones entre millones de
registros para predecir resultados, como indica el SAS Institute,
uno de los referentes mundiales en analítica de negocios.
- Gracias a la acción conjunta de analítica y minería de datos,
que combina estadística, Inteligencia Artificial y aprendizaje
automático, las empresas pueden crear modelos para
descubrir conexiones entre millones de registros.
- El data mining posibilita, entre otros aspectos:
- Limpiar los datos de ruido y repeticiones. Extraer la información
relevante y utilizarla para evaluar posibles resultados. Tomar
mejores decisiones de negocio con mayor rapidez.
- Limpiar los datos de ruido y repeticiones. Extraer la información
relevante y utilizarla para evaluar posibles resultados. Tomar
mejores decisiones de negocio con mayor rapidez.
- El data mining posibilita, entre otros aspectos:
- El minado de datos es un conjunto de técnicas y tecnologías que
permiten explorar grandes bases de datos
- intención o el objetivo de ayudar a comprender una enorme
cantidad de datos
- Su principal finalidad es explorar, mediante la utilización de
distintas técnicas y tecnologías, bases de datos enormes de
manera automática.
- Su principal finalidad es explorar, mediante la utilización de
distintas técnicas y tecnologías, bases de datos enormes de
manera automática.
- intención o el objetivo de ayudar a comprender una enorme
cantidad de datos
- Existe una relación entre los tipos de patrones que se
pueden descubrir y las tareas empleadas en el proceso de
Data Mining o minería de datos, son 7 en total.
- Caracterización o resumen
- La caracterización de datos consiste en la
realización de un resumen de las características
generales de los objetos de una clase y produce lo
que se denomina normas características.
- La caracterización de datos consiste en la
realización de un resumen de las características
generales de los objetos de una clase y produce lo
que se denomina normas características.
- Discriminación o contraste. .
- La discriminación de datos produce lo que se denomina normas
discriminantes, que consiste básicamente en la comparación de
las características generales de los objetos entre dos clases,
referidas como clase de objetivo y clase de contraste.
- La discriminación de datos produce lo que se denomina normas
discriminantes, que consiste básicamente en la comparación de
las características generales de los objetos entre dos clases,
referidas como clase de objetivo y clase de contraste.
- Discriminación o contraste. .
- Análisis de asociación es la búsqueda
de lo que comúnmente se llama como
reglas de asociación.
- Se estudia la frecuencia con la que los dos o más elementos
aparecen juntos en las bases de datos transaccionales, y sobre la
base de un umbral denominado apoyo, identifica los conjuntos
de elementos frecuentes.
- Se estudia la frecuencia con la que los dos o más elementos
aparecen juntos en las bases de datos transaccionales, y sobre la
base de un umbral denominado apoyo, identifica los conjuntos
de elementos frecuentes.
- Análisis de asociación es la búsqueda
de lo que comúnmente se llama como
reglas de asociación.
- Clasificación
- La clasificación se basa en el análisis de la organización de los
datos dentro de las clases. También se conoce como
clasificación supervisada, la clasificación usa las etiquetas de
la clase para ordenar los objetos dentro de la colección de
datos.
- La clasificación se basa en el análisis de la organización de los
datos dentro de las clases. También se conoce como
clasificación supervisada, la clasificación usa las etiquetas de
la clase para ordenar los objetos dentro de la colección de
datos.
- Predicción
- La predicción es una técnica muy interesante en un
contexto de negocios por su alto potencial y las
implicaciones en caso de pronóstico exitoso.
- La predicción es una técnica muy interesante en un
contexto de negocios por su alto potencial y las
implicaciones en caso de pronóstico exitoso.
- Clustering o detección de agrupamientos.
- Similar a la clasificación, el clustering consiste en la
organización de los datos dentro de clases.
- Similar a la clasificación, el clustering consiste en la
organización de los datos dentro de clases.
- Outlier analysis o detección de anomalías.
- Los valores atípicos son elementos de datos que no pueden ser
agrupados dentro de una clase dada o clúster. También se
conocen como excepciones, sorpresas o anomalías y a menudo
son muy importantes de identificar.
- Los valores atípicos son elementos de datos que no pueden ser
agrupados dentro de una clase dada o clúster. También se
conocen como excepciones, sorpresas o anomalías y a menudo
son muy importantes de identificar.
- Evolución y análisis de desviación
- La evolución y el análisis de desviación se refieren
al estudio de los datos y sus cambios dentro de una
escala temporal.
- La evolución y el análisis de desviación se refieren
al estudio de los datos y sus cambios dentro de una
escala temporal.
- Caracterización o resumen
- POR: MONTSERRAT ELIZONDO ROMERO
Media attachments
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Want to create your own Mind Maps for free with GoConqr? Learn more.