6896246
Description
Mind Map by Ivan Hernandez, updated more than 1 year ago
|
|
Created by Ivan Hernandez
about 8 years ago
|
|
...Criptografía...
- "Encriptameinto"
- La búsqueda en árboles binarios es un método de
búsqueda simple, dinámico y eficiente considerado
como uno de los fundamentales en Ciencia de la
Computación.
- En las implementaciones que presentaremos sólo se
considerará en cada nodo del árbol un valor del tipo
tElemento aunque en un caso general ese tipo estará
compuesto por dos:una clave indicando el campo por el cual
se realiza la ordenación y una información asociada a dicha
clave o visto de otra forma,una información que puede ser
compuesta en la cual existe definido un orden.
- En las implementaciones que presentaremos sólo se
considerará en cada nodo del árbol un valor del tipo
tElemento aunque en un caso general ese tipo estará
compuesto por dos:una clave indicando el campo por el cual
se realiza la ordenación y una información asociada a dicha
clave o visto de otra forma,una información que puede ser
compuesta en la cual existe definido un orden.
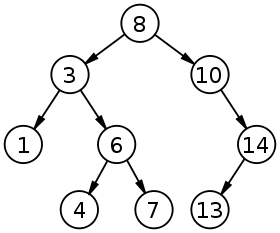
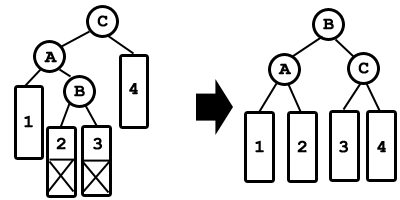
- Un árbol binario de búsqueda(ABB)
es un árbol binario con la propiedad
de que todos los elementos
almacenados en el subárbol
izquierdo de cualquier nodo x son
menores que el elemento
almacenado en x ,y todos los
elementos almacenados en el
subárbol derecho de x son mayores
que el elemento almacenado en x.
- "Operaciones con arboles"
- 1.- Inserción: El procedimiento de inserción en un árbol
binario de búsqueda es muy sencillo, únicamente hay que
tener cuidado de no romper la estructura ni el orden del
árbol. Cuando se inserta un nuevo nodo en el árbol hay que
tener en cuenta que cada nodo no puede tener más de dos
hijos, por esta razón si un nodo ya tiene 2 hijos, el nuevo
nodo nunca se podrá insertar como su hijo. Con esta
restricción nos aseguramos mantener la estructura del
árbol, pero aún nos falta mantener el orden. Para localizar
el lugar adecuado del árbol donde insertar el nuevo nodo se
realizan comparaciones entre los nodos del árbol y el
elemento a insertar. El primer nodo que se compara es la
raíz, si el nuevo nodo es menor que la raíz, la búsqueda
prosigue por el nodo izquierdo de éste. Si el nuevo nodo
fuese mayor, la búsqueda seguiría por el hijo derecho de la
raíz.
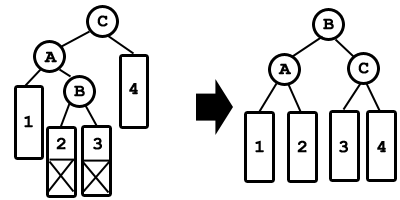
- 2.- Borrar El borrado en árboles binarios de
búsqueda es otra operación bastante sencilla
excepto en un caso. Vamos a ir estudiando los
distintos casos. Tras realizar la búsqueda del nodo
a eliminar observamos que el nodo no tiene hijos.
Este es el caso más sencillo, únicamente habrá
que borrar el elemento y ya habremos concuído la
operación. Si tras realizar la búsqueda nos
encontramos con que tiene un sólo hijo. Este caso
también es sencillo, para borrar el nodo deseado,
hacemos una especie de puente, el padre del
nodo a borrar pasa a apuntar al hijo del nodo
borrado.
- Otras operaciones: En los árboles de búsqueda la operación buscar
es muy eficiente. El algoritmo compara el elemento a buscar con la
raíz, si es menor continua la búsqueda por la rama izquierda, si es
mayor continua por la izquierda. Este procedimiento se realiza
recursivamente hasta que se encuentra el nodo o hasta que se llega
al final del árbol. Otra operación importante en el árbol es el
recorridod el mismo. El recorrido se puede realizar de tres formas
diferentes: Preorden: Primero el nodo raíz, luego el subárbol
izquierdo y a continuación el subárbol derecho. Inorden: Primero el
subárbol izquierdo, luego la raíz y a continuación el subárbol
derecho. Postorden: Primero el subárbol izquierdo, luego el
subárbol derecho y a continuación la raíz.
- Otras operaciones: En los árboles de búsqueda la operación buscar
es muy eficiente. El algoritmo compara el elemento a buscar con la
raíz, si es menor continua la búsqueda por la rama izquierda, si es
mayor continua por la izquierda. Este procedimiento se realiza
recursivamente hasta que se encuentra el nodo o hasta que se llega
al final del árbol. Otra operación importante en el árbol es el
recorridod el mismo. El recorrido se puede realizar de tres formas
diferentes: Preorden: Primero el nodo raíz, luego el subárbol
izquierdo y a continuación el subárbol derecho. Inorden: Primero el
subárbol izquierdo, luego la raíz y a continuación el subárbol
derecho. Postorden: Primero el subárbol izquierdo, luego el
subárbol derecho y a continuación la raíz.
- 2.- Borrar El borrado en árboles binarios de
búsqueda es otra operación bastante sencilla
excepto en un caso. Vamos a ir estudiando los
distintos casos. Tras realizar la búsqueda del nodo
a eliminar observamos que el nodo no tiene hijos.
Este es el caso más sencillo, únicamente habrá
que borrar el elemento y ya habremos concuído la
operación. Si tras realizar la búsqueda nos
encontramos con que tiene un sólo hijo. Este caso
también es sencillo, para borrar el nodo deseado,
hacemos una especie de puente, el padre del
nodo a borrar pasa a apuntar al hijo del nodo
borrado.
- 1.- Inserción: El procedimiento de inserción en un árbol
binario de búsqueda es muy sencillo, únicamente hay que
tener cuidado de no romper la estructura ni el orden del
árbol. Cuando se inserta un nuevo nodo en el árbol hay que
tener en cuenta que cada nodo no puede tener más de dos
hijos, por esta razón si un nodo ya tiene 2 hijos, el nuevo
nodo nunca se podrá insertar como su hijo. Con esta
restricción nos aseguramos mantener la estructura del
árbol, pero aún nos falta mantener el orden. Para localizar
el lugar adecuado del árbol donde insertar el nuevo nodo se
realizan comparaciones entre los nodos del árbol y el
elemento a insertar. El primer nodo que se compara es la
raíz, si el nuevo nodo es menor que la raíz, la búsqueda
prosigue por el nodo izquierdo de éste. Si el nuevo nodo
fuese mayor, la búsqueda seguiría por el hijo derecho de la
raíz.
- "Operaciones con arboles"
- La búsqueda en árboles binarios es un método de
búsqueda simple, dinámico y eficiente considerado
como uno de los fundamentales en Ciencia de la
Computación.
- "Hashing"
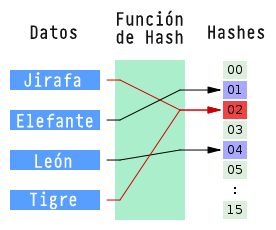
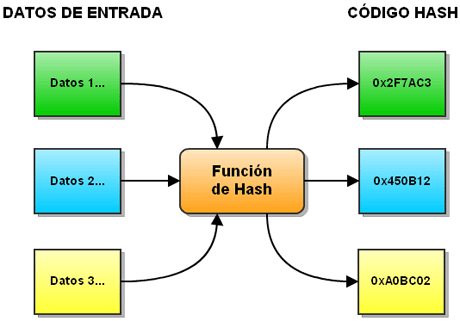
- El término hashing se refiere en realidad a un tipo de función con
un fin dado (que vamos a ver más adelante) que se llaman
funciones hash. Ésta es una función que dado un algoritmo
mapea, un set de datos de longitud variable a otro set fijo.
- ...Utilidad general de funciones hash...
- En seguridad: criptografía mejor dicho, se utiliza para varias funciones, pero la más
simple es por ejemplo para guardar una contraseña, donde no queremos guardar el
texto en plano ya que cualquiera podría leerlo así como está. Entonces la aplicación
le aplica una función para generar una representación que solo será legible para
quien conozca el algoritmo, es decir para ella misma.
- En el transporte de información: habrán visto que a veces cuando bajan un archivo
de internet también está disponible otro más chiquito con un nombre como
CHECKSUM. La idea de este uso es checkear de alguna forma si el contenido del
archivo que uno bajó, coincide con el original del servidor. Ahora, como sería muy
poco práctico volver a comparar byte por byte, resulta que el servidor ya generó un
número hash del archivo original, mediante un algoritmo conocido por todos.
Entonces cuando uno se baja el archivo, le aplica el mismo algoritmo y así genera
otro hash. Si ambos son distintos, entonces quiere decir que en algún punto la
información se corrompió. Acá ya vemos la idea de "eficiencia", aplicamos hash
para hacer la comparación de dos archivos que podrían ser muy grandes, de forma
más eficiente.
- Estructuras de datos: ésta es la aplicación que más nos va a interesar a nosotros.
Algunas estructuras contenedoras de datos utilzan una técnica basada en
funciones de hash para almacenar sus elementos. Esto es lo que vamos a ver en
esta unidad.
- Estructuras de datos: ésta es la aplicación que más nos va a interesar a nosotros.
Algunas estructuras contenedoras de datos utilzan una técnica basada en
funciones de hash para almacenar sus elementos. Esto es lo que vamos a ver en
esta unidad.
- En el transporte de información: habrán visto que a veces cuando bajan un archivo
de internet también está disponible otro más chiquito con un nombre como
CHECKSUM. La idea de este uso es checkear de alguna forma si el contenido del
archivo que uno bajó, coincide con el original del servidor. Ahora, como sería muy
poco práctico volver a comparar byte por byte, resulta que el servidor ya generó un
número hash del archivo original, mediante un algoritmo conocido por todos.
Entonces cuando uno se baja el archivo, le aplica el mismo algoritmo y así genera
otro hash. Si ambos son distintos, entonces quiere decir que en algún punto la
información se corrompió. Acá ya vemos la idea de "eficiencia", aplicamos hash
para hacer la comparación de dos archivos que podrían ser muy grandes, de forma
más eficiente.
- En seguridad: criptografía mejor dicho, se utiliza para varias funciones, pero la más
simple es por ejemplo para guardar una contraseña, donde no queremos guardar el
texto en plano ya que cualquiera podría leerlo así como está. Entonces la aplicación
le aplica una función para generar una representación que solo será legible para
quien conozca el algoritmo, es decir para ella misma.
- ...Utilidad general de funciones hash...
- "Características de la Función Hash"
- Determinística: significa que dada una misma entrada,
siempre va a generar el mismo valor como salida. Es decir
que no depende de una variable externa. Se dice que tiene
transparencia referencial.
- Determinística: significa que dada una misma entrada, siempre
va a generar el mismo valor como salida. Es decir que no
depende de una variable externa. Se dice que tiene
transparencia referencial.
- Determinística: significa que dada una misma entrada, siempre
va a generar el mismo valor como salida. Es decir que no
depende de una variable externa. Se dice que tiene
transparencia referencial.
- Determinística: significa que dada una misma entrada,
siempre va a generar el mismo valor como salida. Es decir
que no depende de una variable externa. Se dice que tiene
transparencia referencial.
- El término hashing se refiere en realidad a un tipo de función con
un fin dado (que vamos a ver más adelante) que se llaman
funciones hash. Ésta es una función que dado un algoritmo
mapea, un set de datos de longitud variable a otro set fijo.
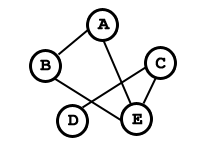
- ...Grafos...
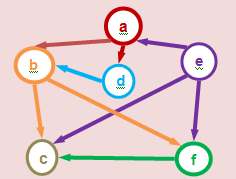
- Un grafo en el ámbito de las ciencias de la computación es un tipo abstracto de
datos (TAD), que consiste en un conjunto de nodos (también llamados vértices)
y un conjunto de arcos (aristas) que establecen relaciones entre los nodos. El
concepto de grafo TAD desciende directamente del concepto matemático de
grafo.
- Formas de representación
- Matriz de adyacencias: se asocia cada fila y cada columna a
cada nodo del grafo, siendo los elementos de la matriz la
relación entre los mismos, tomando los valores de 1 si existe la
arista y 0 en caso contrario.
- Lista de adyacencias: se asocia a cada nodo del grafo una lista que
contenga todos aquellos nodos que sean adyacentes a él.
- Especificación de los tipos abstractos de datos de un
grafo no dirigido
- Generadores: Crear un grafo vacío: Devuelve un grafo
vacío. op crearGrafo : -> Grafo [ctor] . Añadir una arista: Dado
un grafo, añade una relación entre dos nodos de dicho grafo.
op añadirArista : Grafo Nodo Nodo -> [Grafo] [ctor] . Añadir un
nodo: Dado un grafo, incluye un nodo en él, en caso en el que
no exista previamente. op añadirNodo : Grafo Nodo -> Grafo
[ctor] .
- Constructores: Borrar nodo: Devuelve un grafo sin un nodo y las
aristas relacionadas con él. Si dicho nodo no existe se devuelve el grafo
inicial. op borrarNodo : Grafo Nodo -> Grafo . Borrar arista: Devuelve un
grafo sin la arista indicada. En caso de que la arista no exista devuelve el
grafo inicial. op borrarArista : Grafo Nodo Nodo -> Grafo .
- Selectores: Grafo Vacío: Comprueba si un grafo no
tiene ningún nodo. op esVacio : Grafo -> Bool .
Contener Nodo: Comprueba si un nodo pertenece a
un grafo. op contiene : Grafo Nodo -> Bool .
Adyacentes: Comprueba si dos nodos tienen una
arista que los relacione. op adyacentes : Grafo
Nodo Nodo -> Bool . Para la especificación de un
grafo dirigido tenemos que modificar algunas de
las ecuaciones de las operaciones borrarArista y
añadirArista para que no se considere el caso de
aristas bidireccionales. Y sustituir la operación
adyacentes por: op predecesor : Grafo Nodo Nodo
-> Bool . op sucesor : Grafo Nodo Nodo -> Bool .
- Selectores: Grafo Vacío: Comprueba si un grafo no
tiene ningún nodo. op esVacio : Grafo -> Bool .
Contener Nodo: Comprueba si un nodo pertenece a
un grafo. op contiene : Grafo Nodo -> Bool .
Adyacentes: Comprueba si dos nodos tienen una
arista que los relacione. op adyacentes : Grafo
Nodo Nodo -> Bool . Para la especificación de un
grafo dirigido tenemos que modificar algunas de
las ecuaciones de las operaciones borrarArista y
añadirArista para que no se considere el caso de
aristas bidireccionales. Y sustituir la operación
adyacentes por: op predecesor : Grafo Nodo Nodo
-> Bool . op sucesor : Grafo Nodo Nodo -> Bool .
- Constructores: Borrar nodo: Devuelve un grafo sin un nodo y las
aristas relacionadas con él. Si dicho nodo no existe se devuelve el grafo
inicial. op borrarNodo : Grafo Nodo -> Grafo . Borrar arista: Devuelve un
grafo sin la arista indicada. En caso de que la arista no exista devuelve el
grafo inicial. op borrarArista : Grafo Nodo Nodo -> Grafo .
- Generadores: Crear un grafo vacío: Devuelve un grafo
vacío. op crearGrafo : -> Grafo [ctor] . Añadir una arista: Dado
un grafo, añade una relación entre dos nodos de dicho grafo.
op añadirArista : Grafo Nodo Nodo -> [Grafo] [ctor] . Añadir un
nodo: Dado un grafo, incluye un nodo en él, en caso en el que
no exista previamente. op añadirNodo : Grafo Nodo -> Grafo
[ctor] .
- Especificación de los tipos abstractos de datos de un
grafo no dirigido
- Lista de adyacencias: se asocia a cada nodo del grafo una lista que
contenga todos aquellos nodos que sean adyacentes a él.
- Matriz de adyacencias: se asocia cada fila y cada columna a
cada nodo del grafo, siendo los elementos de la matriz la
relación entre los mismos, tomando los valores de 1 si existe la
arista y 0 en caso contrario.
- Formas de representación
- Un grafo en el ámbito de las ciencias de la computación es un tipo abstracto de
datos (TAD), que consiste en un conjunto de nodos (también llamados vértices)
y un conjunto de arcos (aristas) que establecen relaciones entre los nodos. El
concepto de grafo TAD desciende directamente del concepto matemático de
grafo.
Media attachments
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Want to create your own Mind Maps for free with GoConqr? Learn more.