17809001
Description
Mind Map by Edgar Reverón, updated more than 1 year ago
|
|
Created by Edgar Reverón
over 5 years ago
|
|
Big Data
- Definición
- Tradicional
- Big Data (del idioma inglés “grandes
datos”) es en el sector de tecnologías de la
información y la comunicación una
referencia a los sistemas que manipulan
grandes conjuntos de datos (o data sets).
- Big Data (del idioma inglés “grandes
datos”) es en el sector de tecnologías de la
información y la comunicación una
referencia a los sistemas que manipulan
grandes conjuntos de datos (o data sets).
- Gartner
- Gartner define “Biga data” como un conjunto
de datos de gran volumen, de gran velocidad y
procedente de gran variedad de fuentes de
información que demandan formas
innovadoras y efectivas de procesar la
información.
- Gartner define “Biga data” como un conjunto
de datos de gran volumen, de gran velocidad y
procedente de gran variedad de fuentes de
información que demandan formas
innovadoras y efectivas de procesar la
información.
- Tradicional
- Beneficios al Negocio?
- Mejor Toma de Decisiones
- Ganadores y Rezagados de la Industria
- Ventaja Competitiva
- Prevenir e Identificar Cyberatáques
- Mejor Toma de Decisiones
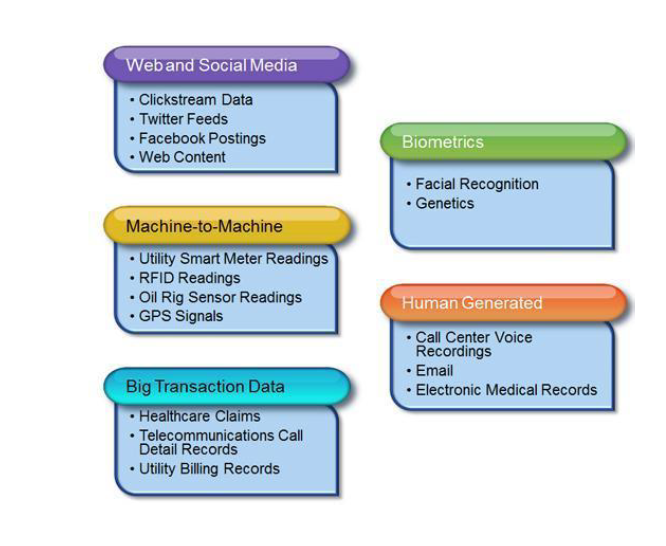
- Tipos de Datos
- Smart Data
- Son todos los datos referentes al negocio
(tanto online, como offline). En este grupo
se puede encontrar desde las cifras de
ventas, datos sobre los clientes, datos
sobre nuestra actividad online, etc. Todo
aquello que esté relacionado con la
consecución de los objetivos de la empresa.
- Son todos los datos referentes al negocio
(tanto online, como offline). En este grupo
se puede encontrar desde las cifras de
ventas, datos sobre los clientes, datos
sobre nuestra actividad online, etc. Todo
aquello que esté relacionado con la
consecución de los objetivos de la empresa.
- Identity Data
- Son todos los datos que nos permiten
identificar a nuestros clientes actuales y
potenciales: datos sobre sus gustos, historial
de compras, perfil de internauta, tipo de
interacción con nuestros contenidos (web,
redes sociales, blog, mobile)entre otros.
- Son todos los datos que nos permiten
identificar a nuestros clientes actuales y
potenciales: datos sobre sus gustos, historial
de compras, perfil de internauta, tipo de
interacción con nuestros contenidos (web,
redes sociales, blog, mobile)entre otros.
- Open Data
- Agrupa al resto de datos externos a la empresa y
que son accesibles por todo el mundo. Por su
volumen y diversidad, nos será más difícil sacarles
partido. Pero una vez encontrada la fuente de
datos (e integrada), los beneficios que podemos
sacar de esta información son enormes.
- Agrupa al resto de datos externos a la empresa y
que son accesibles por todo el mundo. Por su
volumen y diversidad, nos será más difícil sacarles
partido. Pero una vez encontrada la fuente de
datos (e integrada), los beneficios que podemos
sacar de esta información son enormes.
- Smart Data
- Retos Actuales
- Variedad
- Han surgido nuevos tipos de datos
que se quieren almacenar: datos no
estructurados. Las BD Relacionales no
pueden almacenar este tipo de datos.
- Han surgido nuevos tipos de datos
que se quieren almacenar: datos no
estructurados. Las BD Relacionales no
pueden almacenar este tipo de datos.
- Escalabilidad
- En búsqueda de la rapidez y rendimiento
en consultas o procesamiento de datos se
busca escalar siempre en horizontal. Es
decir, si necesitamos más rendimiento
añadimos una CPU a nuestro conjunto de
trabajo para poder aumentar nuestras
prestaciones en conjunto y aumentar el
rendimiento reduciendo el tiempo de
búsqueda o almacenamiento.
- Vertical
- Horizontal
- Vertical
- En búsqueda de la rapidez y rendimiento
en consultas o procesamiento de datos se
busca escalar siempre en horizontal. Es
decir, si necesitamos más rendimiento
añadimos una CPU a nuestro conjunto de
trabajo para poder aumentar nuestras
prestaciones en conjunto y aumentar el
rendimiento reduciendo el tiempo de
búsqueda o almacenamiento.
- Modelo Relacional
- El modelo relacional no da soporte para
todos los problemas. No podemos atacar
todos los problemas con el mismo
enfoque, queremos optimizar al 100%
nuestro sistema y no podemos ajustar
nuestros sistemas a estas BD. Por ejemplo,
en el modelo relacional no podemos tener
herencia de objetos o no podemos tener
columnas variables según las filas...
- El modelo relacional no da soporte para
todos los problemas. No podemos atacar
todos los problemas con el mismo
enfoque, queremos optimizar al 100%
nuestro sistema y no podemos ajustar
nuestros sistemas a estas BD. Por ejemplo,
en el modelo relacional no podemos tener
herencia de objetos o no podemos tener
columnas variables según las filas...
- Velocidad
- La velocidad de generación de datos hoy en día es muy elevada,
simplemente hay que verlo con las redes sociales actuales, aunque las
empresas medias y muchas de las grandes no se ven afectadas por ello.
Donde sí influye la velocidad es en el procesamiento de todo este
conjunto ingente de datos, pues cuantos más datos tengamos más
tiempo requieren. Por ello, se necesita un ecosistema que sea capaz de
escalar en horizontal para trabajar en paralelo y ahorrar tiempo.
- La velocidad de generación de datos hoy en día es muy elevada,
simplemente hay que verlo con las redes sociales actuales, aunque las
empresas medias y muchas de las grandes no se ven afectadas por ello.
Donde sí influye la velocidad es en el procesamiento de todo este
conjunto ingente de datos, pues cuantos más datos tengamos más
tiempo requieren. Por ello, se necesita un ecosistema que sea capaz de
escalar en horizontal para trabajar en paralelo y ahorrar tiempo.
- Variedad
- Áreas de Aplicación
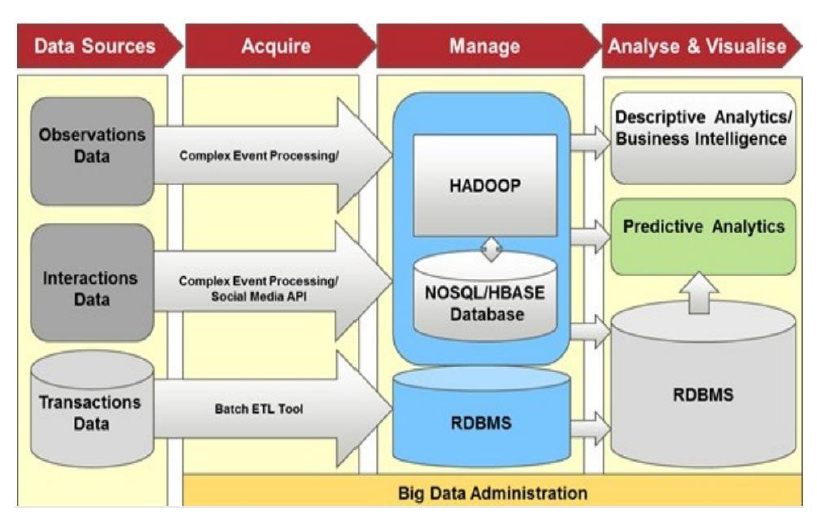
- Arquitectura
- Soluciones Big Data
- No SQL
- Sistema de archivos distribuido
para garantizar escalabilidad
- El corazón del BigData, el concepto del algoritmo MapReduce y Hadoop,
el primero es un algoritmo que permite procesar grandes volúmenes de
información de forma sencilla y resumida, el segundo es una
herramienta que garantiza ejecutar programas MapReduce hechos por
usuarios en nodos distribuidos. Esta herramienta tiene un sistema de
archivos HDFS el cual provee la distribución de trabajos a diferentes
nodos que ejecutarán en paralelo este algoritmo de reducción.
- El corazón del BigData, el concepto del algoritmo MapReduce y Hadoop,
el primero es un algoritmo que permite procesar grandes volúmenes de
información de forma sencilla y resumida, el segundo es una
herramienta que garantiza ejecutar programas MapReduce hechos por
usuarios en nodos distribuidos. Esta herramienta tiene un sistema de
archivos HDFS el cual provee la distribución de trabajos a diferentes
nodos que ejecutarán en paralelo este algoritmo de reducción.
- No SQL
Media attachments
{kind=link}
{kind=link}
{kind=link}
Want to create your own Mind Maps for free with GoConqr? Learn more.