14946573

| Questão | Responda |
| Why use databases? | businesses use to store files of information. loads storage stored easily on magnetic media Data accessed efficiently Data processed extremely fast speeds |
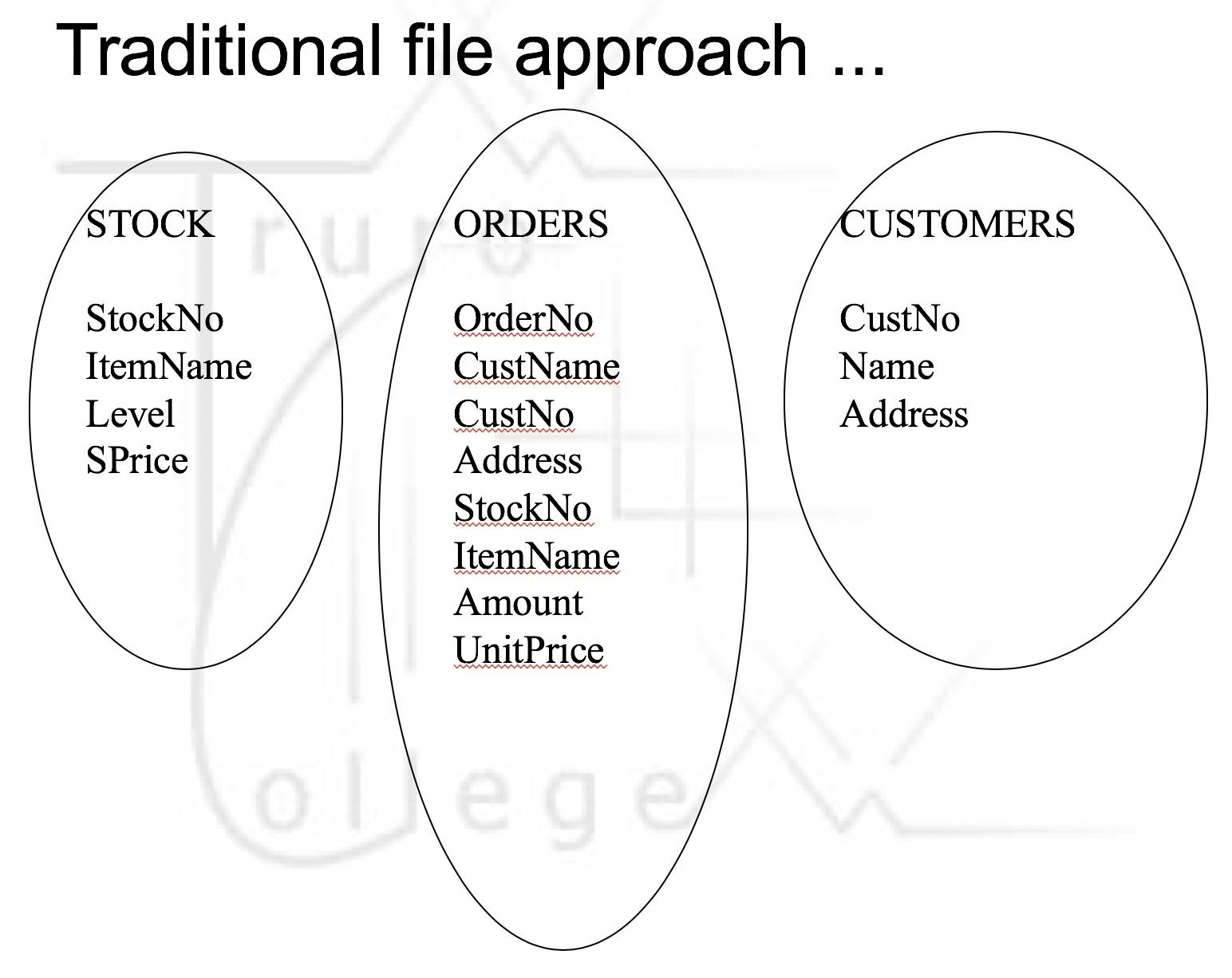
| Flat file problems | Redundancy: multiple same files used across many apps Inconsistency: redundancy = inconsistent data = errors Intergration&Control: hard to monitor/ control info in the system leads to confusion&incoherence in system |
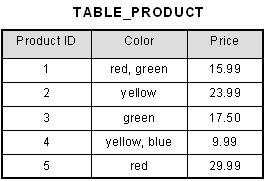
| Flat File Design |
Image:
Image (binary/octet-stream)
|
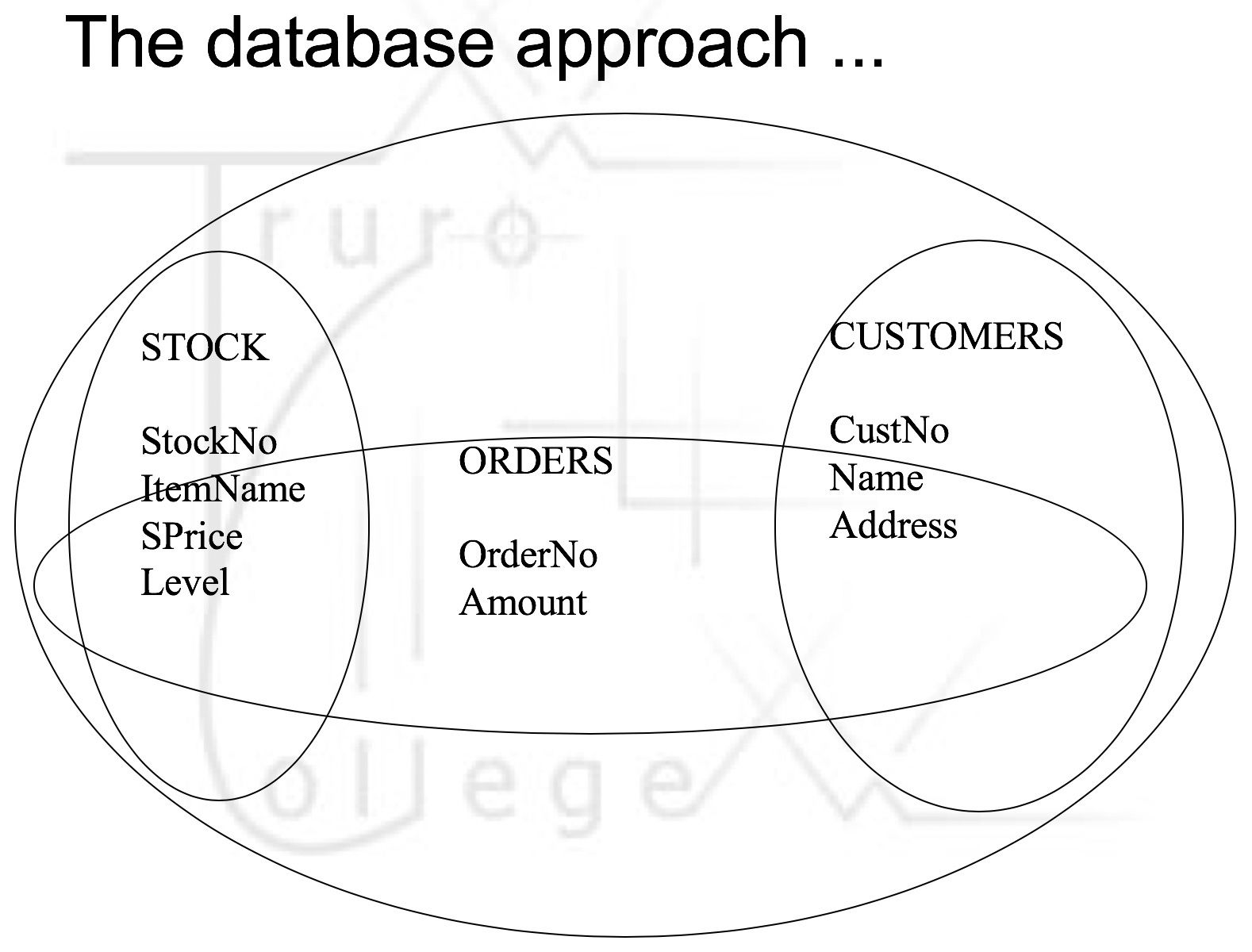
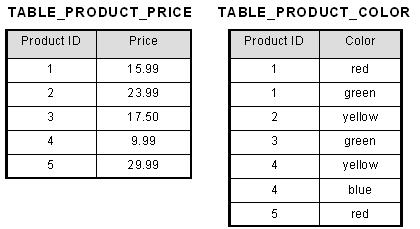
| Database Design |
Image:
Image (binary/octet-stream)
|
| why/n wot Database Design | -need for accurate information businesses -Instead of having separate files for separate applications -organized into a set of underlying files application draws the data that is relevant to them. -Information is a common resource shared by different applications. |
| Advantages: Database approach :) | -Control over Redundancy: common data in multiple apps occ ONLY 1 -Data Consistency: when updated its on all -Greater security and integrity of data: integration of data automatic/n central control becomes achievable -Data independence: no re-prog data independent to the program. -productivity: user make own queries |
| Disadvantages: Database approach :( | -Larger size: DBMS require disk space & powerful computers than w/replaces. -Greater complexity: DBMS must be carefully designed(expert), or not useful. -Possible inefficiency/poor performance: Can be considerably M/less efficient/n purpose-built software. -Greater impact of system failure: database fails everyone is affected. -More complex recovery procedures: requires more complex procedures to recover. |
|
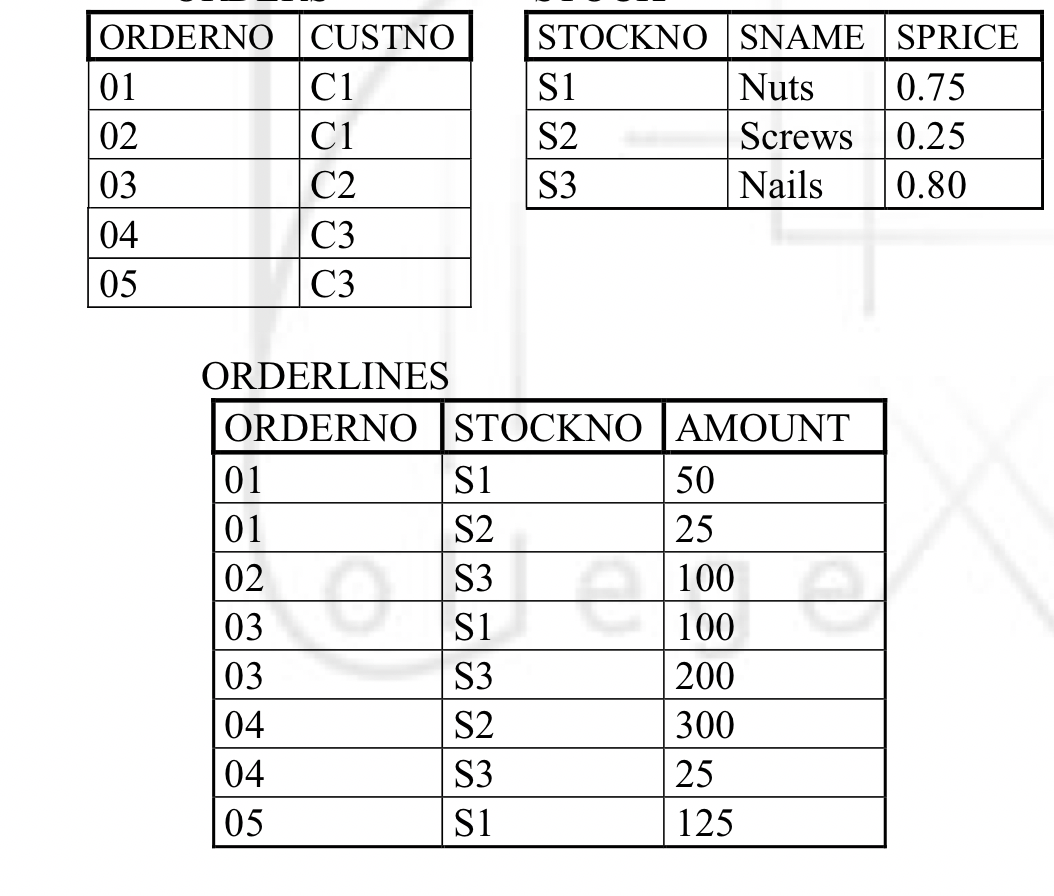
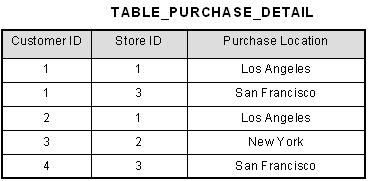
1) What?Files treated as what?
2) tables referred as
3) columns?
4) rows/ records in file?
5) unique identifier?
Image:
Image (binary/octet-stream)
|
1) Relational Model, two dimensional models: Rows/ Collumns 2) Relations/ Entities 3) Attributes 4) Tuples 5) Primary Key |
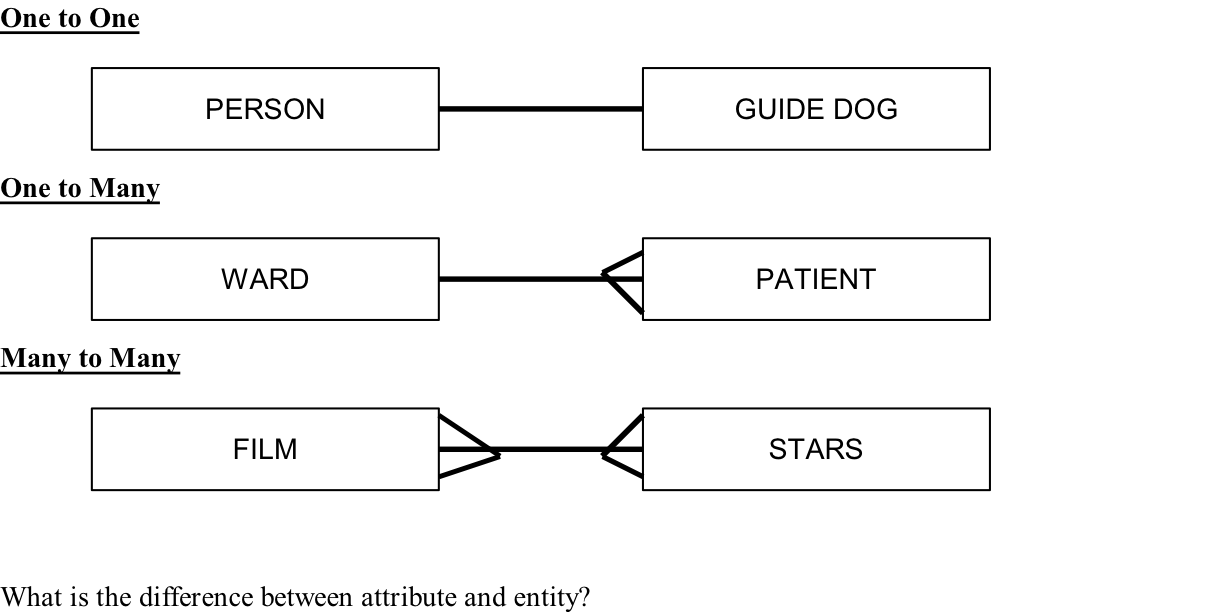
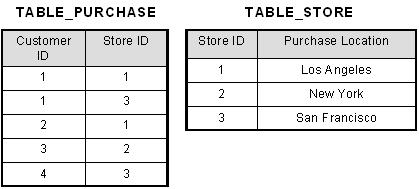
| Types of Relational Databases (3) |
1) one to one, Radio
2) one to many, Speaker
3) many to many, Video Chat
Image:
Image (binary/octet-stream)
|
| Stages of Design: | 1) Identify all the entities 2) list the relationship pairs between these entities 3) draw an entity relationship diagram. - Conceptual model |
|
Standard Notation: Database tables
Image:
Image (binary/octet-stream)
|
Same form used for defining relationships.
Image:
Image (binary/octet-stream)
|
| ANF: What is Normalisation? 1) What Does it Do? 1.5) How should Tables Conform? 2) Tables should Allow? 3) The structure should enable? 4) Most commonly used levels? 5) | 1)-A term for ensuring the database is structured in the best possible way. 1.5)- relating tables together 2)- no data is unnecessarily duplicated data should be consistent 3)- allow adding as many items as required 4)- Complex querying, relating data from different tables. 5)- 1st, 2nd & 3rd normal form. |
|
1st Normal Form if?
Image:
Image (binary/octet-stream)
|
-Contains only atomic values
-There are no repeating groups
Image:
Image (binary/octet-stream)
|
|
2nd Normal Form if?
Image:
Image (binary/octet-stream)
|
All 1NF &:
-It is in first normal form
-All non-key attributes are fully functional dependent on the primary key
Image:
Image (binary/octet-stream)
|
|
3rd Normal Form if?
Image:
Image (binary/octet-stream)
|
All 2NF &: -there is no transitive functional dependency (A is functionally dependent on B, and B is functionally dependent on C. In this case, C is transitively dependent on A via B.) |
| How do you Manipulate Data/ restrict it? | Manipulating and Restricting access to data is done through the DBMS |
| How can a Database Administrator restrict a users access to data? | -Can Restrict 'views' and 'rights' i.e. allowed to view data from certain machines. -A user could be given just a selection of READ/WRITE rights from a combination of: READ data, ADD data, DELETE data, AMEND data. |
| Data validation and verification can be done How? (2) Forms of validation checks? (6) | 1)Can be applied through automation (macros and SQL) 2)Through DBMS settings Presence (required) Range (validation rule) Length (field size) Format/Picture (input mask) Type (datatype) File Lookup (lookup) |
| Purpose of Query Language? (Searching) | Large Datasets, Query Languages are efficient at processing. |
| Querying Large Data Sets to? (4) | - Searching for data: based on criteria (sometimes complex with multiple criteria) -Sorting: (on multiple values) -Other query processes include: updating datasets, creating datasets, inserting new data into datasets, deleting and summarizing data (mathematically and logically) |
| Name for queries applied to the results of other queries? | - Subqueries |
| Purpose of DBMS? (5) | -Data Storage, retrieval and update -Creation and maintenance of the data dictionary -Managing the facilities for sharing the database -Backup and recovery -Security |
| DBA - Database Administration What are their Roles? (6) | -Design of the database -User Information -Maintenance of the data dictionary -Assigning Access Privileges for users -Allocating User passwords -Training provision for users |
| What's Contained in a Data Dictionary? (8) | · What tables and columns are present · Names of current tables and columns. · Data information · Restrictions on column values · Meaning of data fields · Relationships between items of data · Which programs access data · Whether data may be read or changed |
| What is Big Data? | -refers to data sets so large and complex that it becomes difficult to process using standard database techniques -It refers to three main features the Volume of data, the growth of data and the Variety. |
| What is a Predictive Analytic? | is a form of advanced analytics that uses both new and historical data to forecast future activity, behaviour, and trends. |
| How does a predictive Analytic predict trends? (2) | -Apply statistical analysis techniques -Analytical queries and automated machine learning algorithms to data sets to create predictive models that place a numerical value, or score, on the likelihood of a particular event happening. |
| What is Data Warehousing? | It's the store of large amounts of historical data. i.e. the archiving of past transactions |
| Why Data Warehouse? How? a) | -Can be analysed to support management decision making a) -don’t replace transactional databases Instead, they provide ‘periodic snapshots’ for example monthly trends of sales |
| What is Data Mining? Why? | Data Warehouses r mined for relevant data -Associations/ Correlations in the data -Trends over time (e.g. A person is buying more healthy food and is drinking less alcohol) |
| How Data Mine? | 'Drill down' in hunt for meaningful data found by data mining software and shown in graphs and tables. |
|
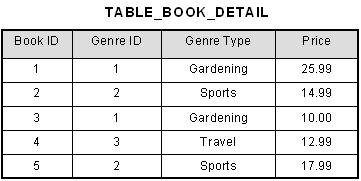
Centralised processing systems
What is it?
Image:
Image (binary/octet-stream)
|
Large central mainframe the norm into the seventies All processing carried out on the central machine Only on-line access was via ‘dumb’ terminals i.e. no processor of their own |
| Centralised processing systems, Common? Example? | -This kind of system less common, but still exists for some applications with some local processing e.g. ATM systems in banks Central system allows access from any terminal in the country |
|
Decentralised
Image:
Image (binary/octet-stream)
|
-With cheaper hardware, processing power moved to users’ desks -In the 80s standalone computers appeared throughout large companies -Word processing and spreadsheet packages became very popular |
| Decentralised Shortcomings | -Computers can't communicate with one another -Many companies – (even Big 1s) had no policy to control the purchase of these systems -Work often duplicated Expertise was not necessarily shared within a company |
|
Distributed
Image:
Image (binary/octet-stream)
|
-Now PCs and Servers would be linked using networks (Via a combination of cables and telecommunications) -Each unit in the business can enjoy a level of selecting systems that suit its operation At the same time, it can share information and core common functions with other units when required |
| When moving from Centralised to Distributed: 1) What is Replaced? 2) What can the move enable? (2) 3) What Decisions are to be made? (3) | 1) Minicomputers and microcomputers replace a central mainframe 2) -They directly serve local and regional branches -Data can be passed to regional and HQ offices 3) -Location of processing power and databases -How to connect the nodes -What levels to place systems at Large companies may have several layers of systems to cater to global requirements |
| Distributed System Benefits? | -Often more efficient to store data on a number of different computers in different locations to maximise performance -Both processing and data are distributed -Computers, applications and databases can be distributed |
| Distributed System Downfall? | -Difficult to make sure all the data in the computer is always up to date – (Integrity vs availability) -Global access to one central database becomes very expensive and time delays + risks increase -Separate versions of a database -Security considerations |
| Methods of Distributing DataBase | Replicated or Duplicated OR Partitioned or Fragmented |
| Distributed Databases: Advantages (3) | -reduce the dependence on a single, central database. -increase responsiveness to local users’ and customers’ needs -reduced communications traffic |
| Distributed Databases: Downfall (3) | -dependent on powerful and reliable telecoms systems -local databases can sometimes depart from central data definitions and standards -security can be compromised when distribution widens access to sensitive data. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Quer criar seus próprios Flashcards gratuitos com GoConqr? Saiba mais.