12071533
Descrição
Mapa Mental por Mark Otten, atualizado more than 1 year ago
|
|
Criado por Mark Otten
quase 7 anos atrás
|
|
Genetic Algorithm Essentials
- Related heuristics
- swarm algorithms
- fireworks
algorithms
- firefly algorthims
- simulated annealing
- swarm algorithms
- Optimization
- problems
- Traveling Salesman problem
- OneMax
- Traveling Salesman problem
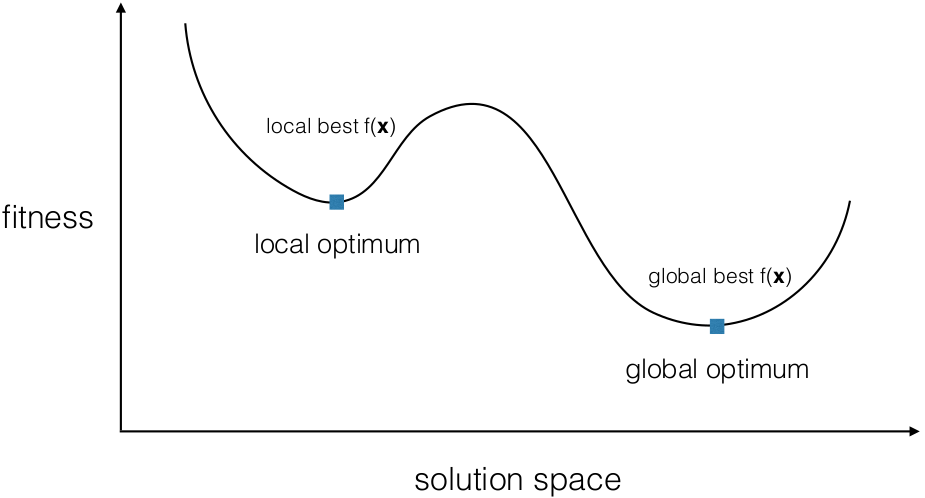
- Optima
- difficulty
- unsteadiness
- noise
- to many local optima
- unsteadiness
- found
- local
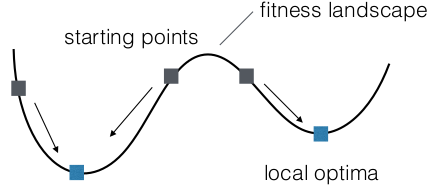
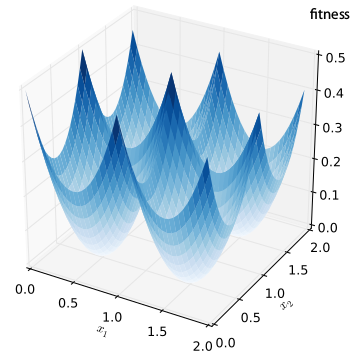
- 4 - Multimodality
- avoid getting stuck
- Restarts
- different starting conditions
- chance high to reach
new local optima
- different starting conditions
- Global mutation rates
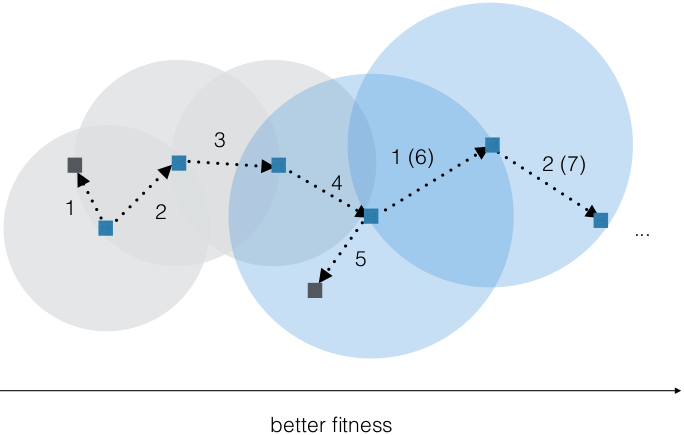
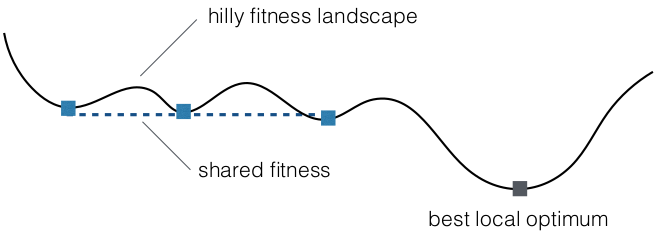
- Fitness sharing
Anotações:
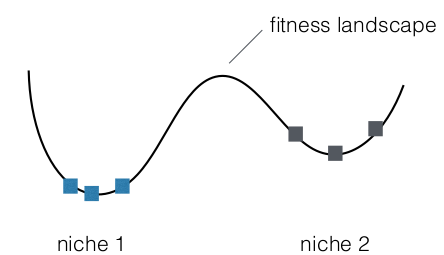
- • neighboring or the ones that belong to one cluster • clustering techniques like k-means or DBSCAN • evolutions within shared region is random walk
- hilly fitness landscape
- Novelty search
- avoid known solutions
- bias search towards
unknown solution areas
- use outlier detection methods
- avoid known solutions
- Niching
- clustering techniques
- k-means
- DBSCAN
Anotações:
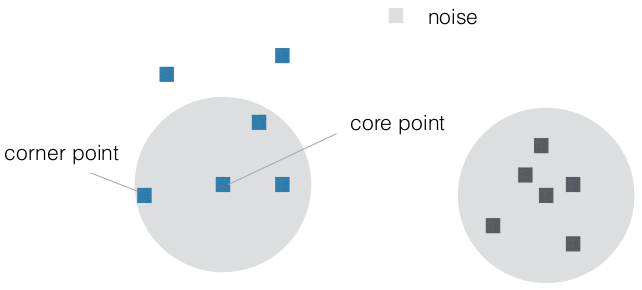
- • define core points with density of solutions • if more than minPts solutions in epsilon radius, point is core point • core points that have core points in their neighborhood belong to one cluster • points that are within radius of core points but are not core points are corner points • rest is noise
- hierarchical
clustering
- k-means
- run separate GA
- Tree Niching
- Follow the worse solution
for g generations
- After g generations
follow better branch
- Follow the worse solution
for g generations
- clustering techniques
- avoid getting stuck
- 4 - Multimodality
- global
- local
- difficulty
- find min or max
- problems
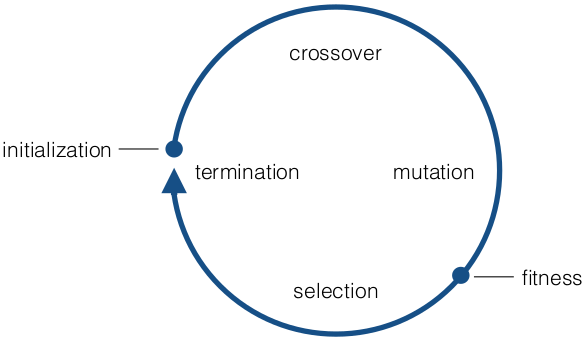
- 2 - Algorithm
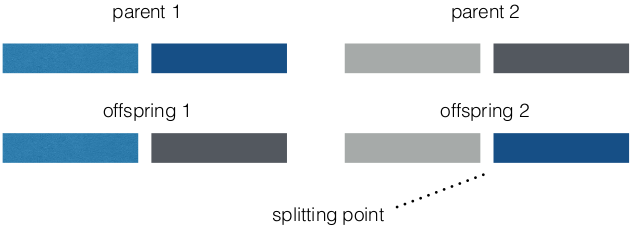
- crossover
- 1-Point crossover
- Arithmetic crossover
- Dominant crossover
- 1-Point crossover
- mutation
- properties
- Reachability
Anotações:
- each point in solution space must be reachable from an arbitrary point in solution space .
- Unbiasedness
Anotações:
- The mutation operator should not induce a drift of the search to a particular direction.
- Scalability
Anotações:
- The mutation rate should be adjustable.
- Reachability
- examples
- Bit flip
- Random resetting
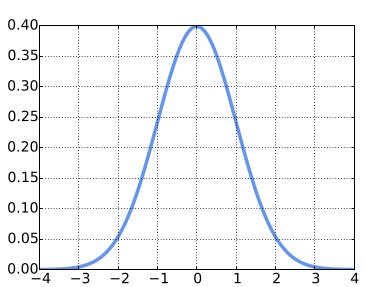
- Gaussian mutation
Anotações:
- x_ = x + sigma * np.random.standard_normal(10)
- x' = x + σ · N (0, 1)
- Bit flip
- mutation rate sigma
- Selft-adaptation
- sigma' = simgma' * exp(tau * N(0,1))
- each chromosome
gets an own σ
- sigma' = simgma' * exp(tau * N(0,1))
- Mutation Rate Controls
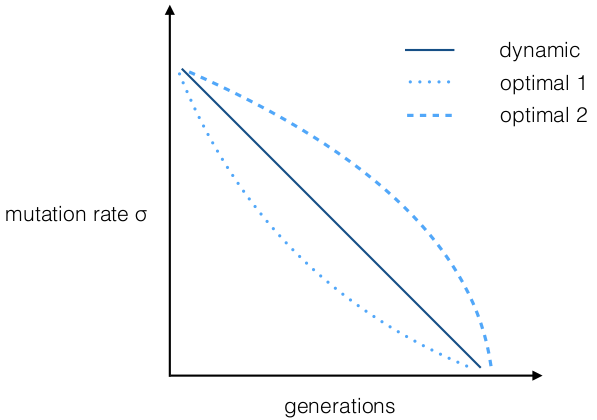
- Dynamic Control
- adapt parameter
depending on
- time
- generation
counter
- time
- changes parameter
during run
- adapt parameter
depending on
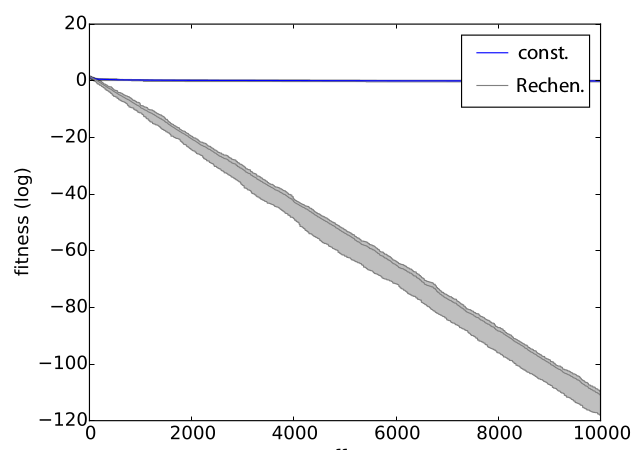
- Rechenberg
- success (>1/5)
-> σ' = σ · τ
- no success (<1/5)
-> σ' = σ / τ
- rate -> 1/5 = keep
σ constant
- success (>1/5)
-> σ' = σ · τ
- Constant mutation rate
- Dynamic Control
- Selft-adaptation
- properties
- Genotype-Phenotype
Mapping
Anotações:
- • map chromosome to solution to evaluate fitness • example: map bit string to pipeline of machine learning commands in sklearn
- fitness
- effiiciency
- find optimum
- approximation in
fitness evaluations
- find optimum
- 6 - Multiple Objectives
- two or more
objectives at a time
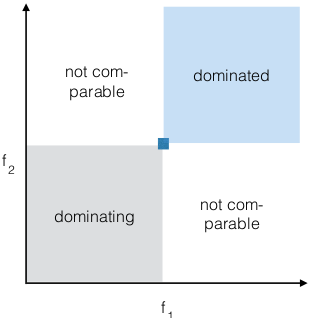
- Pareto
- op. sol. in single-objective
optimization corresponds to
Pareto-set in multi-objective
optimization
- not dominated solutions
are Pareto-optimal
- Pareto-set
- formal
- f = w · f 1 + (1 - w) · f 2
- w \in (0, 1)
- f = w · f 1 + (1 - w) · f 2
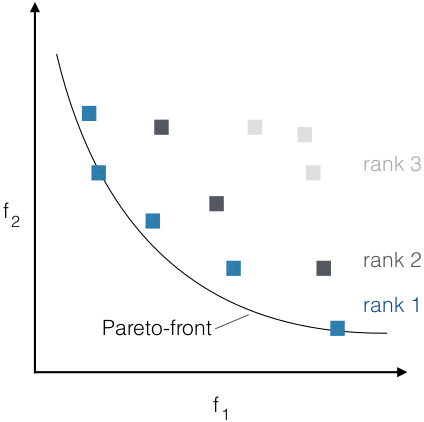
- Non-dominated sorting
- non-dominated = rank 1
- if remove rank i, remaining
non-dominated solutions get rank i+1
- non-dominated = rank 1
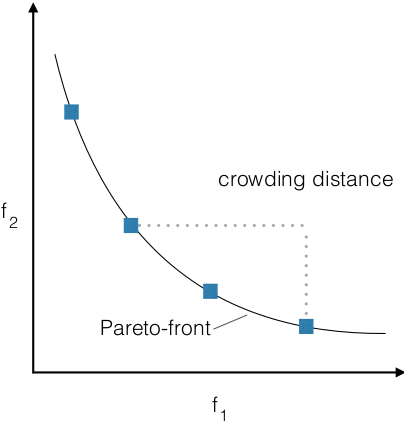
- NSGA-II
- selection solutions with
maximal crowding distance
- seeks for a
broad coverage
- sum of differences between
fitness of left and right
- selection solutions with
maximal crowding distance
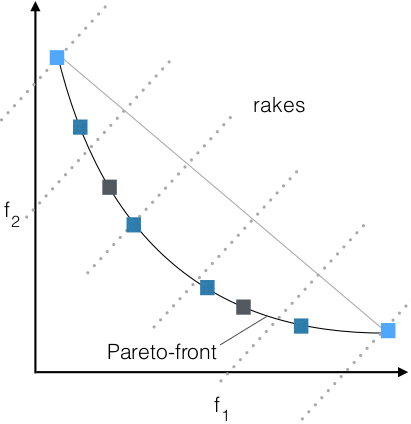
- Rake
- affords evolution
of corner points
- rake selection selects the ones that
minimize the distance to closest rake
- rake base between leftest
and rightest solution
- affords evolution
of corner points
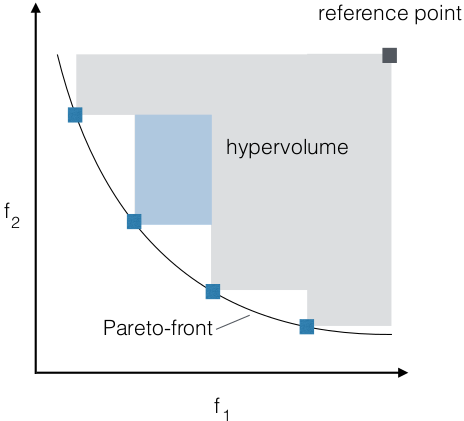
- Hypervolume
- greedy heuristic: (μ + 1)-GA that
discards solution with least
hypervolume contribution
- reference point = badly
dominated solution
- exhaustive for n > 3
- each solution dominates area (n = 2)
or volume (n > 2)
- S-metric selection
- greedy heuristic: (μ + 1)-GA that
discards solution with least
hypervolume contribution
- op. sol. in single-objective
optimization corresponds to
Pareto-set in multi-objective
optimization
- conflicting: price
and performance
- multiple fitness
functions
- no single optimal solution
- two or more
objectives at a time
- effiiciency
- selection
Anotações:
- • To allow convergence towards optimal solutions, the best offspring solutions have to be selected to be parents for the new parental population. • Surplus of offspring is generated, best parents are selected to allow approximation
- Elitist selection
- plus selection
- comma selection
- plus selection
- Forgetting
- Roulette wheel selection
- Tournament
- to overcome
- Roulette wheel selection
- Termination
- after # fitnessfunctions
- after # generations
- after stagnation
- after # fitnessfunctions
- Experiments
- measure
means
- standard deviiantion
- Best and worste fitness
- measure
means
- 3 - Parameter
- Meta-GA
- inefficient, but effective
- GA tunes
GA
- MGA starts GA to optimize
the GA Parameters like tau
- inefficient, but effective
- tuning
- Meta-GA
- 5 - Contraints
- Penalty functions
Anotações:
- penalty functions deteriorate fitness for infeasible solutions
- walk into infeasible
- deteriorate fitness
Anotações:
- verschlechtern
- f'(x) = f(x) + alpha * G(x)
- fitness function evaluations
are not always possible
- Penalty adaptation
- at the end
- depending on
- generation number
- number of infeasible solutions
- increase/decrease at
border of feasibility
- generation number
- at the end
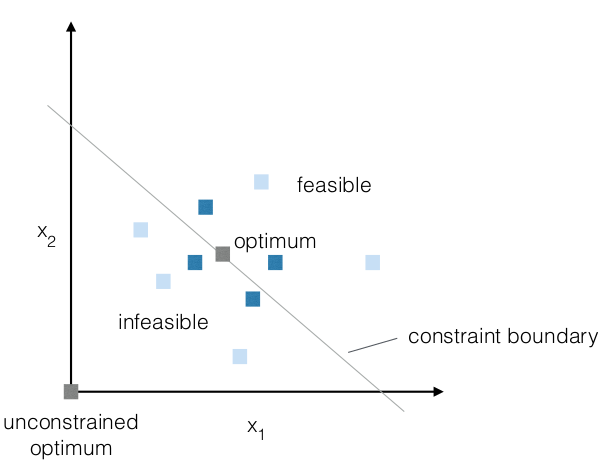
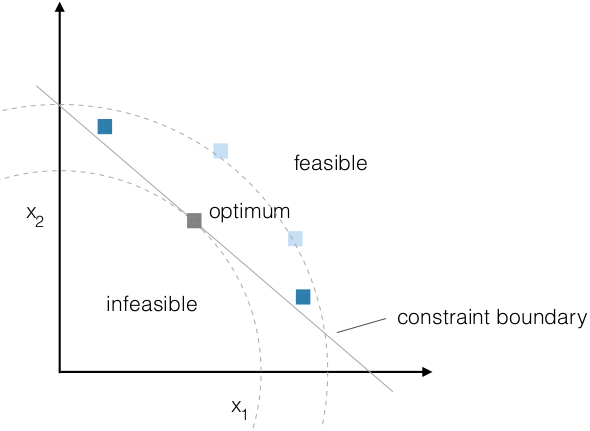
- Solution space
- formal
- g(x) < 0 is constraint function
- G(x) = max (0, g(x))
- f(x) is fitness function
- g(x) < 0 is constraint function
- Death penalty
- in such cases does
not terminate
- may suffer from
premature stagnation
- in such cases does
not terminate
- Repair function
- depending on representation
and problem structure
- examples
- linear projection in
continuous solution spaces
- TSP problem:
repair tour
- linear projection in
continuous solution spaces
- for consistence
of GA search
- depending on representation
and problem structure
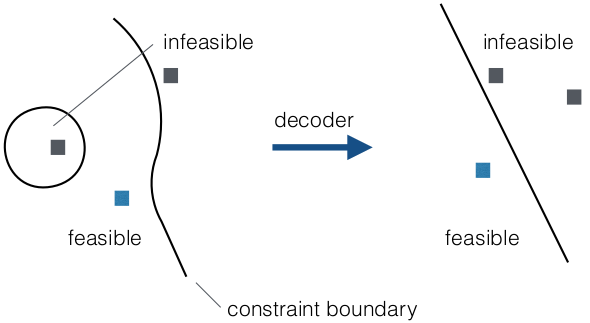
- Decoders
- map constrained solution
space to
- an unconstrained one
- solution space with less
difficult conditions
- an unconstrained one
- mapping must capture
characteristics of solution space
- neighboring solutions in original
space must be neighboring in
decoder space
- map constrained solution
space to
- Premature Stagnation
- How to prevent?
- adaptation of mutation ellipsoid to
increase success probabilities
- minimum mutation rate, but
this also prevents convergence
- adaptation of mutation ellipsoid to
increase success probabilities
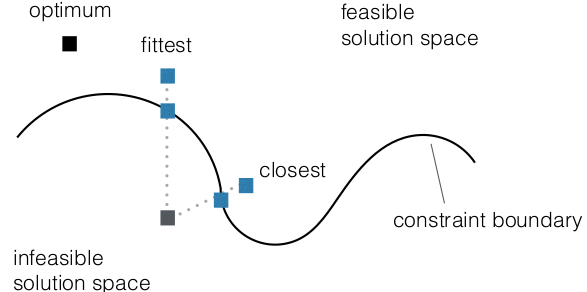
- at boundary of infeasible solution space
success probabilities are often low
- good solutions can be further away
from unconstrained optimum
- How to prevent?
- Penalty functions
- crossover
- GA variants
- genetic alogrithm 1960 (John Holland)
- evolution strategies (Ingo Rechenberg)
- evolutionary programing
- genetic programming
- genetic alogrithm 1960 (John Holland)
- 7 - Theory
- No Free Lunch
- there is no overall superior optimization
algorithm that is able to solve all kinds
of optimization problems
- algorithm that performs well on one problem,
will probably fail on many other problems
- Good News
- it is possible to design algorithms
working well on broad problem class
- it is possible to design algorithms
working well on broad problem class
- there is no overall superior optimization
algorithm that is able to solve all kinds
of optimization problems
- Runtime Analysis
- Laufzeitanalyse für (1+1)-GA
- O(N log N)
- k/N * (1 - 1/N)^(N - 1)
- flip k 0 bits
- do not flip N-1 bits
- flip k 0 bits
- proof
- O(N log N)
- fitness-based partitions
- Laufzeitanalyse für (1+1)-GA
- Markov Chains
- treat populations in each
generations as states
- modelled with matrix of
transition probabilities
- independent of current
state from predecessor
- convergence to global
optimum with elitism
- a GA optimizing a function over an arbitrary finite
space converges to optimum with probability one
- treat populations in each
generations as states
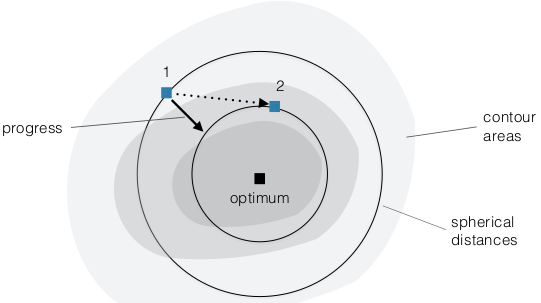
- Progress Rates
- local convergence
measures evaluating
amelioration power of GAs
- population-based GA with plus selection always
performs better than with comma selection
- local convergence
measures evaluating
amelioration power of GAs
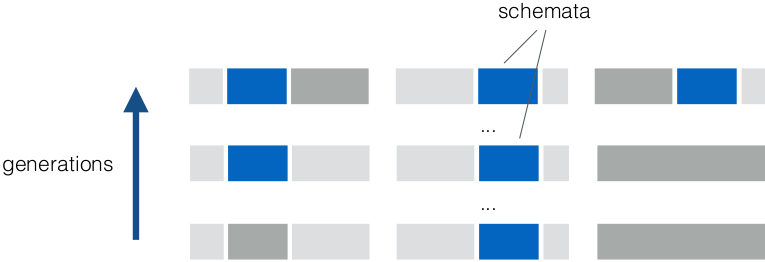
- Schema Theorem
- proportion of individuals representing schema at
subsequent time-steps is product of probabilities of being
selected and not being disrupted
- proportion of individuals representing schema at
subsequent time-steps is product of probabilities of being
selected and not being disrupted
- Building Block Hypothesis
- while schema theorem only
considers disruptive effects, BBH
considers constructive effects
- O(N 2 log N) with crossover
- O(N^k) without Crossover
- while schema theorem only
considers disruptive effects, BBH
considers constructive effects
- No Free Lunch
- 8 - Maschine Learning
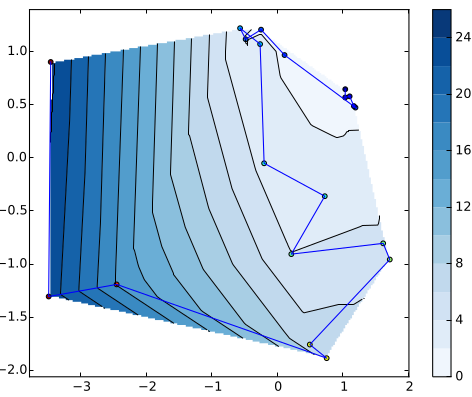
- Covariance Matrix
- lets the mutation operator adapt
to solution space characteristics
- covariance matrix estimated during
an optimization run of a GA on
Sphere function
- lets the mutation operator adapt
to solution space characteristics
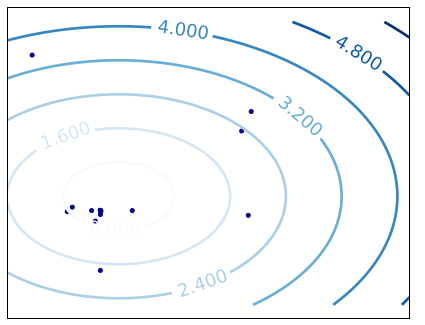
- Fitness meta-modeling
- use f to predict fitness of x
- comprise solution x and fitness
f(x) pair as pattern- label pair
- exploration strategy: try new solutions
for optimization or for improvement
of meta-model
- use f to predict fitness of x
- data space is
solution space
- Supervised learning
- learning with labels
- training set T = {(x 1 ,y 1 ),
(x 2 ,y 2 ), ..., (x N ,y N )}
- classification
- y = 0 or 1, feasible or infeasible
- y = 0 or 1, feasible or infeasible
- regression
- y is numerical (e.g. 0.634,
12.39, fitness values)
- y is numerical (e.g. 0.634,
12.39, fitness values)
- learning with labels
- Constraint meta-modeling
- same works for constraints
- comprise constraint satisfaction
prediction as classification problem
- same works for constraints
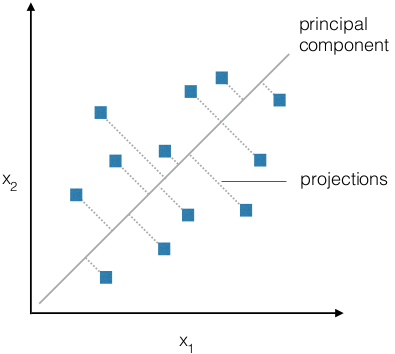
- Dimensionality reduction
- Dimensionality reduction
for visualization
- mapping of high-dimensional
population to low dimensional space
- mapping of high-dimensional
population to low dimensional space
- map high-dimensional patterns to
abstract low- dimensional spaces
- principal component analysis
- PCA detects axes in the data
that employ highest variances
- projections of patterns
onto these axes
- PCA detects axes in the data
that employ highest variances
- Dimensionality reduction
for visualization
- Covariance Matrix
Anexos de mídia
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Quer criar seus próprios Mapas Mentais gratuitos com a GoConqr? Saiba mais.