Applied Business Research (Copenhagen Business School) exam preparation
|
|
Criado por Jonas Klint Westermann
aproximadamente 8 anos atrás
|
|
Fechar
|
|
Criado por Jonas Klint Westermann
aproximadamente 8 anos atrás
|
|
Suppose the demand for your product is a linear function of income, relative price and the quarter of the year. Assuming the slopes are the same, explain in detail exactly how you would test the hypothesis that ceteris paribus the demand for your product is identical in the spring, summer and fall.
2) Which of the following are consequences of heteroskedasticity?
a) The OLS coefficient estimates are inconsistent.
b) The usual F statistic no longer has an F distribution.
c) The OLS estimators are no longer BLUE.
Determine the sign of the expected bias introduced by omitting a variable from the specification:
In an earnings equation for workers, the impact on the coefficient of experience of omitting the variable for age.
Determine the sign of the expected bias introduced by omitting a variable from the specification:
In an equation for the demand for peanut butter, the impact on the coefficient of disposable income of omitting the price of peanut butter variable.
A friend has regressed kilograms of Brazilian coffee purchased on the real price of Brazilian coffee (PB), the real price of tea (PT), and real disposable income (Y). She found the wrong sign on PB with a t value of 0.5. She re-estimated the specification without PB and found little change in the other coefficient estimates, so she adopted the latter specification and concluded in her writeup that demand for Brazilian coffee is price inelastic. Before handing her project in she asks for your advice. What advice would you offer?
Consider a simple model to estimate the effect of personal computer (PC) ownership on grade point average for graduating students at a large university.
GPA = ß(0) + ß(1)PC + (error term)
where PC is binary variable indicating computer ownership.
In this specification, is there reason to believe PC to be correlated with the error term? Why or why not?
Consider a simple model to estimate the effect of personal computer (PC) ownership on grade point average for graduating students at a large university.
GPA = ß(0) + ß(1)PC + (error term)
where PC is binary variable indicating computer ownership.
Explain why PC is likely to be related to parents’ annual income. Does this mean that parental income is a good instrumental variable (IV) for PC? Why or why not?
What must a variable satisfy if it is to serve as an instrument in a regression?
Would these independent variables violate the assumption of no perfect collinearity among independent variables?
Right shoe size and left shoe size of students in your university.
Would these independent variables violate the assumption of no perfect collinearity among independent variables?
Consumption and disposable income in Denmark over 50-year period.
Would these independent variables violate the assumption of no perfect collinearity among independent variables?
Xi and 5Xi.
Would these independent variables violate the assumption of no perfect collinearity among independent variables?
Xi and (Xi)^3.
When estimating a demand function for a good where quantity demanded is a linear function of the price, you should not include an intercept because the price of the good is never zero. True, false or uncertain? Explain your reasoning.
Studenth = 19.6 + 0.73* Midparh; R2 = 0.45 (7.2) (0.10)
where Studenth is the height of students in inches, Midparh is the average of the parental heights and the standard errors are reported in the parentheses.
Interpret the estimated coefficients. What does the R2 tell you?
Studenth = 19.6 + 0.73* Midparh; R2 = 0.45 (7.2) (0.10)
where Studenth is the height of students in inches, Midparh is the average of the parental heights and the standard errors are reported in the parentheses.
If children, on average, were expected to be of the same height as their parents, then this would imply two hypotheses, one for the slope and one for the intercept. State the null hypotheses. From the info provided can you assess whether you will reject the nulls?
In a time series setting, what is a spurious regression? Are there circumstances when it is meaningful to estimate such regressions?
Assume that religion affects educational attainment, and also affects the level of earnings conditional on education. How could I estimate the total effect of religion on earnings, and how could I estimate the marginal effect of education on earnings? What is the difference in what these terms mean?
When there are omitted variables in the regression, which are determinants of the dependent variable, then this will always bias the OLS estimator of the included variable. True, false or uncertain? Explain your reasoning.
C(t) =18.5−0.07P(t) +0.93YD(t) −0.74D1(t) −1.3D2(t) −1.3D3(t)
Ct is per-capita pounds of pork consumed in the United States in quarter t
Pt is the price of a hundred pounds of pork (in dollars) in quarter t
YDt is per capita disposable income (in dollars) in quarter t
D1t is a dummy equal to 1 in the first quarter (Jan.–Mar.) of the year and 0 otherwise
D2t is a dummy equal to 1 in the second quarter of the year and 0 otherwise D3t is a dummy equal to 1 in the third quarter of the year and 0 otherwise
(a) What is the meaning of the estimated coefficient of YD?
C(t) =18.5−0.07P(t) +0.93YD(t) −0.74D1(t) −1.3D2(t) −1.3D3(t)
Ct is per-capita pounds of pork consumed in the United States in quarter t
Pt is the price of a hundred pounds of pork (in dollars) in quarter t
YDt is per capita disposable income (in dollars) in quarter t
D1t is a dummy equal to 1 in the first quarter (Jan.–Mar.) of the year and 0 otherwise
D2t is a dummy equal to 1 in the second quarter of the year and 0 otherwise D3t is a dummy equal to 1 in the third quarter of the year and 0 otherwise
Specify expected signs for each of the coefficients. Explain your reasoning
Wi = -11,4 + 0,31Ai – 0,003Ai^2 + 1,02Si + 1,23Ui
(2,98) (1,49) (5,04) (1,21)
N = 34; Adjusted R2 = 0,14
Wi = the hourly wage (in Euros) of the ith worker
Ai = the age of the ith worker
Si = the number of years of education of the ith worker
Ui = a dummy variable equal to 1 if the ith worker is a union member, 0 otherwise
What is the meaning of including A2 in the equation? What relationship between A and W do the signs of the coefficients imply? Why doesn’t the inclusion of A and A2 violate the assumption of no perfect collinearity between two independent variables?
Wi = -11,4 + 0,31Ai – 0,003Ai^2 + 1,02Si + 1,23Ui
(2,98) (1,49) (5,04) (1,21)
N = 34; Adjusted R2 = 0,14
Wi = the hourly wage (in Euros) of the ith worker
Ai = the age of the ith worker
Si = the number of years of education of the ith worker
Ui = a dummy variable equal to 1 if the ith worker is a union member, 0 otherwise
Even though you have been told not to focus on the value of the intercept, isn’t -11,4 too low to just ignore? What should be done to correct this problem?
Wi = -11,4 + 0,31Ai – 0,003Ai^2 + 1,02Si + 1,23Ui
(2,98) (1,49) (5,04) (1,21)
N = 34; Adjusted R2 = 0,14
Wi = the hourly wage (in Euros) of the ith worker
Ai = the age of the ith worker
Si = the number of years of education of the ith worker
Ui = a dummy variable equal to 1 if the ith worker is a union member, 0 otherwise
Would your boss be happy with your regression results? Can you conclude that union membership improves workers’ well-being? Why or why not?
Suppose I estimate an OLS regression of the time series variable Y(t) on X(t) and find strong evidence that the residuals are serially correlated. Does this imply my coefficient estimates are inconsistent?
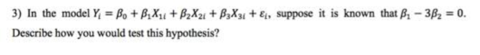
Suppose you compute a sample statistic q to estimate a population quantity Q. If q is an unbiased estimator of Q, then q = Q. True, false or uncertain. Explain your reasoning carefully.
In the presence of heteroskedasticity coefficient estimates from a logistic regression are biased and inconsistent. True, false or uncertain? Explain your reasoning.
Omitting a relevant explanatory variable that is uncorrelated with the other independent variables causes bias and a decrease in standard errors. True, false or uncertain? Explain your reasoning.
Imagine you estimate a model where earnings is a function of a bunch of independent variables that are inter-related (they cause each other), and nothing in the model is statistically significant. Does that mean that these independent variables do not influence earnings? If you believed that they really did influence earnings, what might you do?
C(t) =18.5−0.07P(t) +0.93YD(t) −0.74D(1)(t) −1.3D(2)(t) −1.3D(3)(t)
C(t) = per-capita pounds of pork consumed in the United States in quarter t
P(t) = the price of a hundred pounds of pork (in dollars) in quarter t
YD(t) = per capita disposable income (in dollars) in quarter t
D(1)(t) = dummy equal to 1 in the first quarter (Jan.–Mar.) of the year and 0 otherwise
D(2)(t) = dummy equal to 1 in the second quarter of the year and 0 otherwise
D(3)(t) = dummy equal to 1 in the third quarter of the year and 0 otherwise
What is the meaning of the estimated coefficient of YD?
C(t) =18.5−0.07P(t) +0.93YD(t) −0.74D(1)(t) −1.3D(2)(t) −1.3D(3)(t)
C(t) = per-capita pounds of pork consumed in the United States in quarter t
P(t) = the price of a hundred pounds of pork (in dollars) in quarter t
YD(t) = per capita disposable income (in dollars) in quarter t
D(1)(t) = dummy equal to 1 in the first quarter (Jan.–Mar.) of the year and 0 otherwise
D(2)(t) = dummy equal to 1 in the second quarter of the year and 0 otherwise
D(3)(t) = dummy equal to 1 in the third quarter of the year and 0 otherwise
Suppose we changed the definition of D(3)(t) so that it was equal to 1 in the fourth quarter and 0 otherwise and re-estimated the equation with all the other variables unchanged. Which of the estimated coefficients would change?
Briefly explain the meaning of the following terms:
• A time series integrated of order 2
• Stochastic error term
• Endogenous variable
• Unobserved heterogeneity
A:Y = 125.0−15.0X1 −1.0X2 +1.5X3 R2 = 0.75
B:Y = 123.0−14.0X1 +5.5X2 −3.7X4
R2 = 0.73
Where Y = the number of joggers on a given day, X1 = inches of rain that day, X2 = hours of sunshine that day, X3 = the high temperature for that day (in Celcius), and X4 = the number of classes with term papers due the next day.
Which of the two (admittedly hypothetical) equations do your prefer and why?
A:Y = 125.0−15.0X1 −1.0X2 +1.5X3 R2 = 0.75
B:Y = 123.0−14.0X1 +5.5X2 −3.7X3
R2 = 0.73
Where Y = the number of joggers on a given day, X1 = inches of rain that day, X2 = hours of sunshine that day, X3 = the high temperature for that day (in Celcius), and X4 = the number of classes with term papers due the next day.
How is it possible to get different estimate signs for the coefficient of the same variable using the same data?
Carefully outline (be brief!) a description of the problem typically referred to as pure heteroskedasticity.
(a) What is it?
(b) What are its consequences?
(c) How do you diagnose it?
(d) What do you do to get rid of it?
Suppose I estimate an OLS regression of the time series variable Yt on Xt and find strong evidence that the residuals are serially correlated. Does this imply my coefficient estimates are inconsistent?
What examples are there of data reduction techniques? Purpose of data reduction?
Main issue of cluster analysis.
When is non-parametric statistics used?
In an OLS regression, what does BLUE stand for?
Interpret ß(1) in each of the equations.
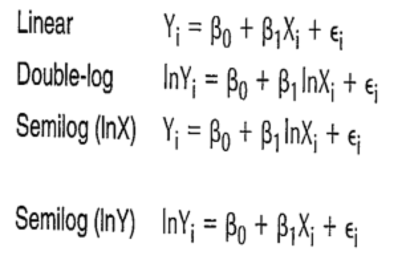
Describe omitted variable issue.
- What is it?
- What are the consequences?
- How can it be detected?
- How can it be corrected?
What reason is there to include quadratic terms in regressions?
- When testing for multicollinearity through VIFs, what value should not be exceeded?
- What value should not be exceeded when looking at bivariate coefficient of correlation in Stata? What is the command?
For the residuals to have a normal distribution, what value must the coefficient of skewness lie in between?
What value should a t-statistic be in order to reject the null?
When do you use logit/probit models?
Difference in cluster and factor analysis


