65095
Crash Course Computer Sciense

Description
Module Information
Description
No tags specified
Show more
Show less
The Abakus - the earliest computing machine. Is manually operated, and uses decimal count to store state, meaning every time the counter reaches 10 a 1 bid is move right and the decimal counter resets, thus holding state of count.
The step reckoner - The step reckoner was a digital mechanical calculator invented by the German mathematician Gottfried Wilhelm Leibniz around 1672.
Its basic function is to count, adding up & subtraction (similar to abakus), yet can also do multilications and devide, and could do all four of this operations automaticaly.
Charles Babage and the Difference Engine - much more complex machine that could approximate polynomials.
Plynomials:
In mathematics, a polynomial is an expression consisting of variables (also called indeterminates) and coefficients, that involves only the operations of addition, subtraction, multiplication, and non-negative integer exponents of variables. An example of a polynomial of a single indeterminate, x, is x2 − 4x + 7. An example in three variables is x3 + 2xyz2 − yz + 1.
Polynomials appear in many areas of mathematics and science. For example, they are used to form polynomial equations, which encode a wide range of problems, from elementary word problems to complicated problems in the sciences; they are used to define polynomial functions, which appear in settings ranging from basic chemistry and physics to economics and social science; they are used in calculus and numerical analysis to approximate other functions. In advanced mathematics, polynomials are used to construct polynomial rings and algebraic varieties, central concepts in algebra and algebraic geometry.
Charles Babage and the The Analytical Engine - was a proposed mechanical general-purpose computer designed by English mathematician and computer pioneer Charles Babbage.[2][3] It was first described in 1837 as the successor to Babbage's difference engine, a design for a mechanical computer.[4] The Analytical Engine incorporated an arithmetic logic unit, control flow in the form of conditional branching and loops, and integrated memory, making it the first design for a general-purpose computer that could be described in modern terms as Turing-complete.[5][6] In other words, the logical structure of the Analytical Engine was essentially the same as that which has dominated computer design in the electronic era.[3]
The tabulating machine - The tabulating machine was an electromechanical machine designed to assist in summarizing information stored on punched cards. Invented by Herman Hollerith, the machine was developed to help process data for the 1890 U.S. Census. Later models were widely used for business applications such as accounting and inventory control. It spawned a class of machines, known as unit record equipment, and the data processing industry.
was 10X faster than the analytical engine.
Electronic Computing
Harvard mark 1 - The IBM Automatic Sequence Controlled Calculator (ASCC), called Mark I by Harvard University’s staff,[1] was a general purpose electromechanical computer that was used in the war effort during the last part of World War II.
One of the first programs to run on the Mark I was initiated on 29 March 1944[2] by John von Neumann. At that time, von Neumann was working on the Manhattan project, and needed to determine whether implosion was a viable choice to detonate the atomic bomb that would be used a year later. The Mark I also computed and printed mathematical tables, which had been the initial goal of British inventor Charles Babbage for his "analytical engine".
Mechanical Relay - Mechanical relays are devices that can turn on or turn off the power supplied to another device, like a switch. However, instead of having a person flip the switch, mechanical relays switch when provided with a small amount of power. This allows high-power circuits to be controlled by low-power devices.
Thermionic valve - The type known as a thermionic tube or thermionic valve uses the phenomenon of thermionic emission of electrons from a heated cathode and is used for a number of fundamental electronic functions such as signal amplification and current rectification. Vacum tube.
Colossus mark 1 - Colossus was a set of computers developed by British codebreakers in the years 1943–1945 to help in the cryptanalysis of the Lorenz cipher. Colossus used thermionic valves (vacuum tubes) to perform Boolean and counting operations. Colossus is thus regarded[3] as the world's first programmable, electronic, digital computer, although it was programmed by switches and plugs and not by a stored program.
Transistors - A transistor is a semiconductor device used to amplify or switch electronic signals and electrical power. It is composed of semiconductor material usually with at least three terminals for connection to an external circuit. A voltage or current applied to one pair of the transistor's terminals controls the current through another pair of terminals. Because the controlled (output) power can be higher than the controlling (input) power, a transistor can amplify a signal. Today, some transistors are packaged individually, but many more are found embedded in integrated circuits.
Semiconductors - A semiconductor material has an electrical conductivity value falling between that of a metal, like copper, gold, etc. and an insulator, such as glass. Their resistancedecreases as their temperature increases, which is behaviour opposite to that of a metal. Their conducting properties may be altered in useful ways by the deliberate, controlled introduction of impurities ("doping") into the crystal structure. Where two differently-doped regions exist in the same crystal, a semiconductor junction is created. The behavior of charge carriers which include electrons, ions and electron holes at these junctions is the basis of diodes, transistors and all modern electronics. Some examples of semiconductors are silicon, germanium, and gallium arsenide. After silicon, gallium arsenide is the second most common semiconductor[citation needed] used in laser diodes, solar cells, microwave frequency integrated circuits, and others. Silicon is a critical element for fabricating most electronic circuits.
Description
No tags specified
Show more
Show less
Boolean algebra - In mathematics and mathematical logic, Boolean algebra is the branch of algebra in which the values of the variables are the truth values true and false, usually denoted 1 and 0 respectively. Instead of elementary algebra where the values of the variables are numbers, and the prime operations are addition and multiplication, the main operations of Boolean algebra are the conjunction and denoted as ∧, the disjunction or denoted as ∨, and the negation not denoted as ¬. It is thus a formalism for describing logical relations in the same way that elementary algebra describes numeric relations.
NOT
True = false
false = true
BOOLEAN GATE
electrode in-current
|
/
control wire (input - on) -----|
\ output - on
electrode in-current
|
/
control wire (input - off) -----|
\ output - off
NOT ▶●
electrode in-current
|------ output (off)
/
control wire (input - on) -----|
\
|
V
ground
electrode in-current
|------> output (on)
/
control wire (input - off) -----|
\
|
ground
AND ⍾
True + True = True
False + False = False
False + True = False
True + False = False
current
|
/
Transistor (input A on) -----|
\
|
/
Transistor (input B on) -----|
\
|Output
V
current
|
/
Transistor (input A off) -----|
X
|
/
Transistor (input B on) -----|
\
|Output
V
current
|
/
Transistor (input A on) -----|
\
|
/
Transistor (input B off) -----|
X
|Output
V
OR ⍲
current
_____|_____
/ |
Transistor (input A on) -----| |
\ |
| |
| /
Transistor (input B on) -------(-------------|
| \
|__________|
|
V
current
____|______
/ |
Transistor (input A off) -----| |
X |
| |
| /
Transistor (input B on) -------(-------------|
| \
|__________|
|
V
current
____|______
/ |
Transistor (input A on) -----| |
\ |
| |
| /
Transistor (input B off) -------(-------------|
| X
|__________|
|
V
current
____|______
/ |
Transistor (input A off) -----| |
X |
| |
| /
Transistor (input B off) -------(-------------|
| X
|__________|
|
X
XOR GATE IS NOT COVERED
Description
No tags specified
Show more
Show less
Converting between base 10 and 2
BASE 10
263
100 X 2
+
10 X 6
+
1 X 3
BASE 2
101
1 X 1
+
2 X 0
+
4 X 1 = 5
another example
11011
1 X 1
+
2 X 0
+
4 X 1
+
8 X 1 = 27
8Bit size = Byte
1 2 3 4 5 6 7 8
_________________________________________________________
| 128's | 64's | 32's | 16's | 8's | 4's | 2's | 1's |
|________|______|______|______|_____|_____|_____|_____|
| 1 1 1 1 1 1 1 1 = 255 in UTF8 is ÿ
|______________________________________________________
_________________________________________________________
| 128's | 64's | 32's | 16's | 8's | 4's | 2's | 1's |
|________|______|______|______|_____|_____|_____|_____|
| 0 1 1 1 1 1 1 1 = 127 in ASCII is DEL
|______________________________________________________
_________________________________________________________
| 128's | 64's | 32's | 16's | 8's | 4's | 2's | 1's |
|________|______|______|______|_____|_____|_____|_____|
| 0 1 1 1 0 1 1 1 = 119 in ASCII is w
|______________________________________________________
_________________________________________________________
| 128's | 64's | 32's | 16's | 8's | 4's | 2's | 1's |
|________|______|______|______|_____|_____|_____|_____|
| 0 1 1 0 0 0 1 1 = 99 in ASCII is c
|______________________________________________________
16bit encoding came out later.
32bit & 64bit are the standard today.
TAKE NOTE
This is just like in decimal count
The number 1,654 is:
__________________________________
| 1000's | 100's | 10's | 1's |
|_________|________|______|_____|
| 1 6 5 4
|_________________________________
A number at each place is just a multiplacation of 10.
Representing floating numbers:
A floating number, lets say 625.9 can be represented in the following way
0.6259 * 10^3
|___| ^
| | exponent
Segnificant
Floating numbers are represented in a 32bit number storage.
______________________________________________________________________________________________________________________________________________________________
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 |25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 |
|__||_______________________________||______________________________________________________________________________________________________________________|
^ ^ ^
| | |
sign exponent Segnificant
(-/+) 8bits 23bits
1bit
Description
No tags specified
Show more
Show less
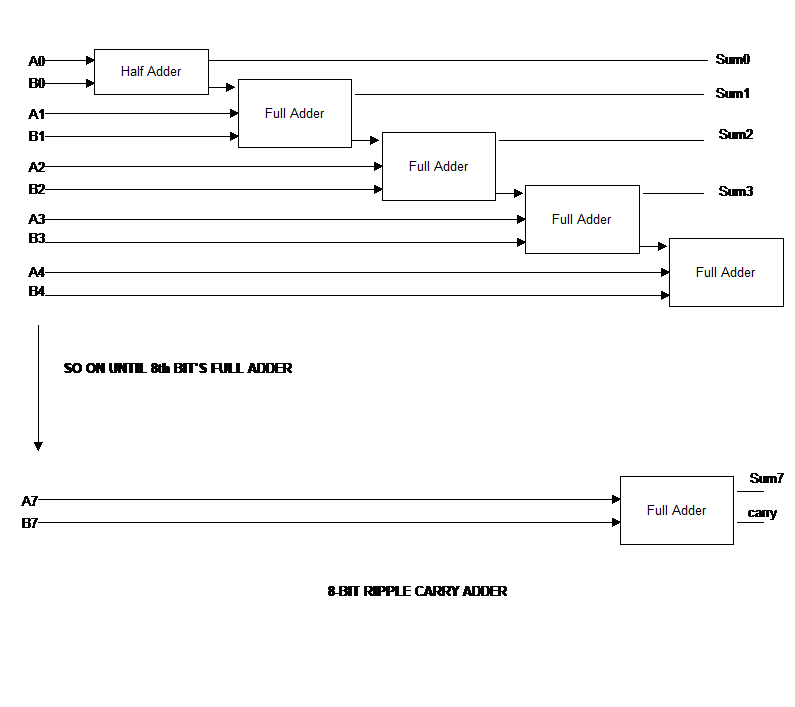
The ALU - An arithmetic logic unit (ALU) is a combinational digital electronic circuit that performs arithmetic and bitwise operations on integer binary numbers.
This is in contrast to a floating-point unit (FPU), which operates on floating point numbers.
An ALU is a fundamental building block of many types of computing circuits, including the central processing unit (CPU) of computers, FPUs, and graphics processing units (GPUs).
single CPU, FPU or GPU may contain multiple ALUs.
The inputs to an ALU are the data to be operated on, called operands, and a code indicating the operation to be performed; the ALU's output is the result of the performed operation. In many designs, the ALU also has status inputs or outputs, or both, which convey information about a previous operation or the current operation, respectively, between the ALU and external status registers.
Arithmetic unit
Add: A and B are summed and the sum appears at Y and carry-out.
Add with carry: A, B and carry-in are summed and the sum appears at Y and carry-out.
Subtract: B is subtracted from A (or vice versa) and the difference appears at Y and carry-out. For this function, carry-out is effectively a "borrow" indicator. This operation may also be used to compare the magnitudes of A and B; in such cases the Y output may be ignored by the processor, which is only interested in the status bits (particularly zero and negative) that result from the operation.
Subtract with borrow: B is subtracted from A (or vice versa) with borrow (carry-in) and the difference appears at Y and carry-out (borrow out).
Two's complement (negate): A (or B) is subtracted from zero and the difference appears at Y.
Increment: A (or B) is increased by one and the resulting value appears at Y.
Decrement: A (or B) is decreased by one and the resulting value appears at Y.
Pass through: all bits of A (or B) appear unmodified at Y. This operation is typically used to determine the parity of the operand or whether it is zero or negative, or to load the operand into a processor register.
Bitwise logical operations unit
AND: the bitwise AND of A and B appears at Y.
OR: the bitwise OR of A and B appears at Y.
Exclusive-OR: the bitwise XOR of A and B appears at Y.
Ones' complement: all bits of A (or B) are inverted and appear at Y.
Description
No tags specified
{kind=link}
{kind=link}
Description
No tags specified
Show more
Show less
* The standard definition for an array is a linear collection of elements, where the elements
can be accessed via indices, which are usually integers used to compute offsets.
A JavaScript array is actually a specialized type of JavaScript object, with the indices
being property names that can be integers used to represent offsets. However, when
integers are used for indices, they are converted to strings internally in order to conform
to the requirements for JavaScript objects.
Accessor functions
functions that retrieve the indices of wanted values, for example in javascript, the function Array.prototype.indexOf() is an Accessor function.
To retrieve the value of an element in an array you use an expression, denoted using the bracket syntax: array[10].
this expression does a resolution to a variable adress in memory that holds an array object, than accesses the memory adress designated for the item at index of 10 in the space designated for the array.
In javascript arrays are objects, so this bracket expression will retrieve the value of the "10" property under the array object, stored in the adress reached by resolution of the array variable.
Mutator Functions
Mutator functions change the structure of an array variable, for example add items to the array, remove items, or retrieve parts of the array.
For example in javascript: pop(), push(), shift(), unshift(), splice(), concat()
Iterator Function
Iterator functions apply a selected function to each array item, either returning a value, a set of values, or a new array after all array item have been iterated over with the selected function.
In javascript examples for these kind of functions are: forEach(), map(), reduce(), filter(),findIndex() (not an accessor function since it applies a function to each item)
Multi-Dimensional Arrays (arrays of arrays or matrix)
To represent complex data structures mutidimesional arrays are often used, for example for image processing, where an image is a matrix of pixels represented by a two dimensional array, representing the X & Y axis to access the different pixels in the grid.
To create multidimensional arrays its better to use the grid approach of columns and rows, defining a function that takes a number of row a colums.
Multi-Dimensional Jagged Arrays
Are multidimensional array that contain diferent sizes of arrays for each column or row.
Sparse Arrays:
Sparse arrays are arrays that have undassigned (undefined) elements in it, making the real size of the array different than the arrays size.
Description
No tags specified
Show more
Show less
Lists
Lists are one of the most common organizing tools people use in their day-to-day lives.
We have to-do lists, grocery lists, top-ten lists, bottom-ten lists, and many other types.
Our computer programs can also use lists, particularly if we only have a few items to
store in list form. Lists are especially useful if we don’t have to perform searches on the
items in the list or put them into some type of sorted order. When we need to perform
long searches or complex sorts, lists become less useful, especially with more complex
data structures.
Description
No tags specified
Show more
Show less
Stacks
* Stacks are efficient data structures because data can be added or removed only from the
top of a stack, making these procedures fast and easy to implement.
*Stacks are used extensively in programming language implementations for everything from expression
evaluation to handling function calls.
LIFO (Last-In First-Out)
A stack is a list of elements that are accessible only from one end of the list, which is
called the top. One common, real-world example of a stack is the stack of trays at a
cafeteria. Trays are always removed from the top, and when trays are put back on the
stack after being washed, they are placed on the top of the stack. The stack is known as
a last-in, first-out (LIFO) data structure.
Stack operations
Operation on a stack:
push() - adds another stack item to the top of the list
peek() - returns the value of the item at the top of the list
pop() - remove the item from the top of the list
The different uses of stacks
There are several problems for which a stack is the perfect data structure needed for the
solution. In this section, we look at several such problems.
Multiple Base Conversions
First lets go trough the mathematical way of converting bases.
The simplest way to convert from decimal to binary is to divide by 2 and kepping the reminder, then dividing the result of step 1 by 2 and keeping the reminder.
So on until you deplete your number.
Example:
16 % 2 = 8 reminder 0
8 % 2 = 4 reminder 0
4 % 2 = 2 reminder 0
2%2 = 1 reminder 0
1% 2 = 0 reminder 1
Then reverse the array of the reminders to get the binary number for 16, which is 10000
The same is done to convert between other bases, for example to convert to base 6 you just deviding by 6, following the same steps.
This procedure, is perfect for stacks, because you create a stack of the reminders (array/list), then you go from top to bottom (from end of the array/list) pushing the top number into a new array, thus reversing the array. This a LIFO procedure because you operate only on the top of the stack, meaning the last item pushed to the top of the array will be the first to be pushed to the second array.
Palindromes
Palindromes are words that are spelled the same when reversed, if excluding strings a simple flip procedure on a stack will give us the same string as the original string.
Take for example the string "race car". if the space character is extracted the string will be the same value after a flip.
So, the steps for this algorithms are:
1. split the string into an array off characters.
2. iterate over the array to find the indices to any space characters.
3. extract those space characters out of the array.
4. iterate over the resulting string from top to bottom (FILO, from end of array), pushing each value into a new array.
Demonstrating Recoursion
Since recursion creates a stack of active functions, its an excellent way to demonstrate stacks.
A good way to demonstrate recursion and the how it creates stacks of function calls is using factorials.
for example, taking the factorial of 5, 5! = 5*4*3*2*1. We can open up a stack of function calls, each passing up the previous number minus one, till the number is 1.
When we reach the number 1 we start returning results, resolving the stack as each function returns the value for the multiplication of n * n-1.
Example:
function factorial(n) {
if (n === 0) {
return 1;
}
else {
return n * factorial(n-1);
}
}
which will look like:
factorial(5)
|_> factorial(4)
|_> factorial(3)
|_>factorial(2)
|_> factorial(1)
|_> factorial(0)
return 1 <_|
return 1 <_|
return 2 <_|
return 6 <_|
return 24 <_|
return 120 <_|
Description
No tags specified
Show more
Show less
Queues
The two primary operations involving queues are inserting a new element into a queue
and removing an element from a queue. The insertion operation is called enqueue, and
the removal operation is called dequeue. The enqueue operation inserts a new element
at the end of a queue, and the dequeue operation removes an element from the front of
a queue. Example:
enqueue(a,arr) result [a]
enqueue(b,arr) result [a,b]
enqueue(c,arr) result [a,b,c]
enqueue(d,arr) result [a,b,c,d]
enqueue(e,arr) result [a,b,c,d,e]
dequeue(operateOnDequeuedFunc) [b,c,d,e]
dequeue(operateOnDequeuedFunc) [c,d,e]
dequeue(operateOnDequeuedFunc) [d,e]
dequeue(operateOnDequeuedFunc) [e]
dequeue(operateOnDequeuedFunc) []
Some uses of queues
Simulations: since queue operates in a natural order, meaning the first thing that happens is
the first thing to be resolved. It is good for simulating events happening on a timeline.
For example the browsers event queue:
User is clicking on things, creating Javascript tasks that are added to the event loop queue.
These tasks need to be resolved in the order the user made them happen, in order to reflect the real nature of the timeline of the event, and resolve the users interaction propely.
There is also the Dance Party simulation used to demonstrate queues:
REFER TO: Data structures and algorithms with javascript -> Chapter:5
Sorting data with queues (radix sort):
Priority Queues
Description
No tags specified
Show more
Show less
Shortcomings of Arrays
* In many languages arrays are fixed in size, making it hard to add new elements to the array.
* Deleting elements from an array demand changing the position of all elements in an array, same with deletion.
* In Javascript arrays are less eficient since they are really array like objects, unlike in languages like Javas or C++.
* Linked lists can be useful whenever a one dimensional array is needed, unless random access is needed
Insertion to a linked list
Insertion to a linked lists a very simple procedure.
You basically travel down the next properties of the linked list, and when you reach the node that you looking for (to insert an adjacent object after) you simply reference the its next property to the new object, and you reference the new objects next property to the previously linked object, to the object the was linked to its parent.
Removing a node from the list
To remove a node from the list, you need to traverse the list until you find it.
The you have to do 2 things:
1) point the next attribute of the previous node to the node after the node you want to remove.
2) point the removed node's next property to NULL
Doubly Linked Lists
Traversing a linked list from one end to the other is easy, but to traverse the link back to the start will need that each node has a reference to the the previous node, usually using a property called parent.
* deletion - do delete a node form a doubly linked list you need to do 4 things:
1) change the previous nodes next property to point to the node after the removed node.
2) change the parent property, on the node after the removed node, to point to previous node (now the parent)
3) change the removed nodes parent to NULL
4) change the removed nodes next property to null.
Circularly linked list
A linked list has a Header object which is the first object of the list, in a Circularly Linked List the last node's next property does not point to NULL, but rather back to the Header node
Why circularly linked list - if you want to be abale to traverse back in a linked list but you do not want the over head of creating a doubly linked node for each link, a circular linked list can enable geting back to the start of the list easily by just traversing to the end of it once.
Description
No tags specified
Show more
Show less
A dictionary
is a data structure that stores data as key-value pairs, such as the way a
phone book stores its data as names and phone numbers. When you look for a phone
number, you first search for the name, and when you find the name, the phone number
is found right next to the name. The key is the element you use to perform a search, and
the value is the result of the search.
The JavaScript Object class is designed to operate as a dictionary.
Description
No tags specified
Show more
Show less
What are hash tables good for
Hash tables are typically used to store large numbers of objects.
Hashing table are good for retrieving data, since its based on the dictionary principle, we access the data directly using an index, which is the result of a hash function.
The hash function preforms some algorithms to process the unique value and returns, what should be, a unique index.
Retrieving data from Hash Tables should have, optimally, a static time for each retrieve operation, this is since you retrieve directly without search.
Hash Table size
The size of the hash table is important. it should be big enough to hold future data, and it should be the size of a primary number.
Depending on the colission strategy you choose (Open Adressing or Closed Adrressing), you should choose an array size that is the Closest Primary Number , this is because the array size will be used in the hash function, and a primary number will be most beneficial for this.
Hashing function
The hash function takes a key value, a value by which we search the item, could be a unique string, for example: last name + first name, and calculates and returns an index.
The value should be the value of a predetermaned attribute that represents the key, and should exists on every object that is inserted into the table.
Lets say for example the table is a table of costumers, and a costumer looks like the following:
costumerObject = {
lastname:'katz',
firstname:'tomas',
payments:12,
eachpayment:20,
currency:'$'
}
and we have an object for a costumer request for payment information that looks like this:
paymentRequestObject = {
fullname:"tomas katz",
requesttime:1349294394234524
}
we might pass the fullname property as the hash function input because we know that costumerObject.firstname+' '+ costumerObject.lastname, will hash to the same key.
So to store the object we will store it to the index value of hashFunction(costumerObject.firstname+' '+ costumerObject.lastname)
And to retrieve it we will access the array trough the index value of hashFunction(paymentRequestObject.fullname).
Hashing Algorithms
A simple hashing algorithm might do the following:
1) calculate the ASCII sum of the input string
2) then return the Modulu of that sum with the Primary array size.
And this is only is the key is a string.
Handling Collisions
Since we a have a limited number of items in an array, but unlimited possible value, collisions of keys will happen.
Colissions of keys happend when two different values hash to the same key value, and given a big enough number of items these collision will happen.
Handeling collisions fall into two strategies, Open Adressing & Closed Adressing .
Open Adressing
Is a strategy where, collision are considered in the size of the array, the aproximate size of the array is calculated and the size of the is trippled.
That way, if a collision happens, the next available open slot is probed for, and since the array size is triple that of our aproximation, that means that 2 open slots might be open next to the adress where the collision happened.
Since the place where the collision happend is already occupied, we start a linear probe and check the next index, if its also occupied we check the next, and so on until an open space occurs where we can insert the value.
This way retrieving gives us the best possible place to start a probe, in best case scenarion a static time of imidate retrival, since no collisions happned before, at worst case a full linear probe of the whole array, in case multiple collisions already happened and all open spaces were occupied and the last place to store the value was the last place open in the array.
[item,if colision,if colision,if colision,item,colided,if colision,item,colided,colided]
Closed addresing
Closed adressing is a collision strategy where, when a collision occurres we create an array inside the item at the index where the collision occurred, pushing items that collided with the already occupied index into the array at that index.
Thus we dont need to enlarge the array size to hold more items then it should.
And in case we search for an item that colided, we reach the index than start a search only on the collision items, no linear probing is needed, we know that our item is in this index, which is an array, and all we need to do is probe that array to find our item, and not the whole array.
[item,item [collision item,collision item,collision item],item]
Description
No tags specified
Show more
Show less
BST (Binary Search Trees) Defined
A binary search tree is basically a linked node list, or a node tree , the only main difference is how the tree is arranged.
To understand how a BST is arranged we first need to look at the types of nodes it holds:
Root node
Is the node at the very top of the tree, and even though its called a root its at the top of the tree.
Child node & Parent Node
If the a node is not a root node than its a Child Node of some other node that is a Parent node.
The only nodes that are not Parent Nodes are Leaf Nodes.
A regular node tree can have any number of child nodes, but in Binary Search Tree's the number of children is limited to only two.
Left Node & Right Node
The left node holds the a value that is lower than the Parent Node, and the Left Node hold a value that is greater than the Parent Node.
The Left Node and Right Node are also called Edges, and by following a certain edge yo can clearly travel down a path of lower or higher values then the node you looking at.
Path
Path is the series of edges you travel trough, and visiting all nodes in a tree in a perticular order is called tree traversal
Leaf Nodes
Leaf nodes have no Child Nodes, and thus they are not Parent Nodes either.
Levels
Levels are the maximum number of edges you can travel down the tree in one direction.
The root node is at level 0, the direct Child Nodes are at level 1, the children of all level 1 nodes are level 2 nodes, and so on...
BST Insertion Procedure
The insertion procedure is made of a preperation stage prior to traversing the tree for insertion, and the traversing itself.
The preperations stage:
1) First we need to create a Node instance from the value we want to insert.
2) Then we need to position our selves in the root node of the tree, for that we will use a current variable, this variable will also be used to keep track of the current node were at at each traversal iteraton, if the root property of the BST is null then the tree is empty, we insert the node and exit the function.
3) Otherwise we start traversing the tree with a while loop, starting with the current root node.
The traversal stage
1) We by setting the parent variable to the current node.
2) If our value is smaller then the current nodes value, we set the the current node to the left node, keeping the parent node pointing to the previous current node.
3) If the new current node is null, we insert the new node here by changing the parent node's left property to our new node, otherwise skip to next iteration.
4) if our new value is higher the the current node, we set the current node to the right node, keeping the parent variable pointing to the previously current node.
5) if the new current node is null we insert and exit, otherwise we continue to the iteration.
an insert function might look something like this:
function insert(data) {
var n = new Node(data, null, null);
if (this.root == null) {
this.root = n;
}
else {
var current = this.root;
var parent;
while (true) {
parent = current;
if (data < current.data) {
current = current.left;
if (current == null) {
parent.left = n;
break;
}
}
else {
current = current.right;
if (current == null) {
parent.right = n;
break;
}
}
}
BST Search procedures
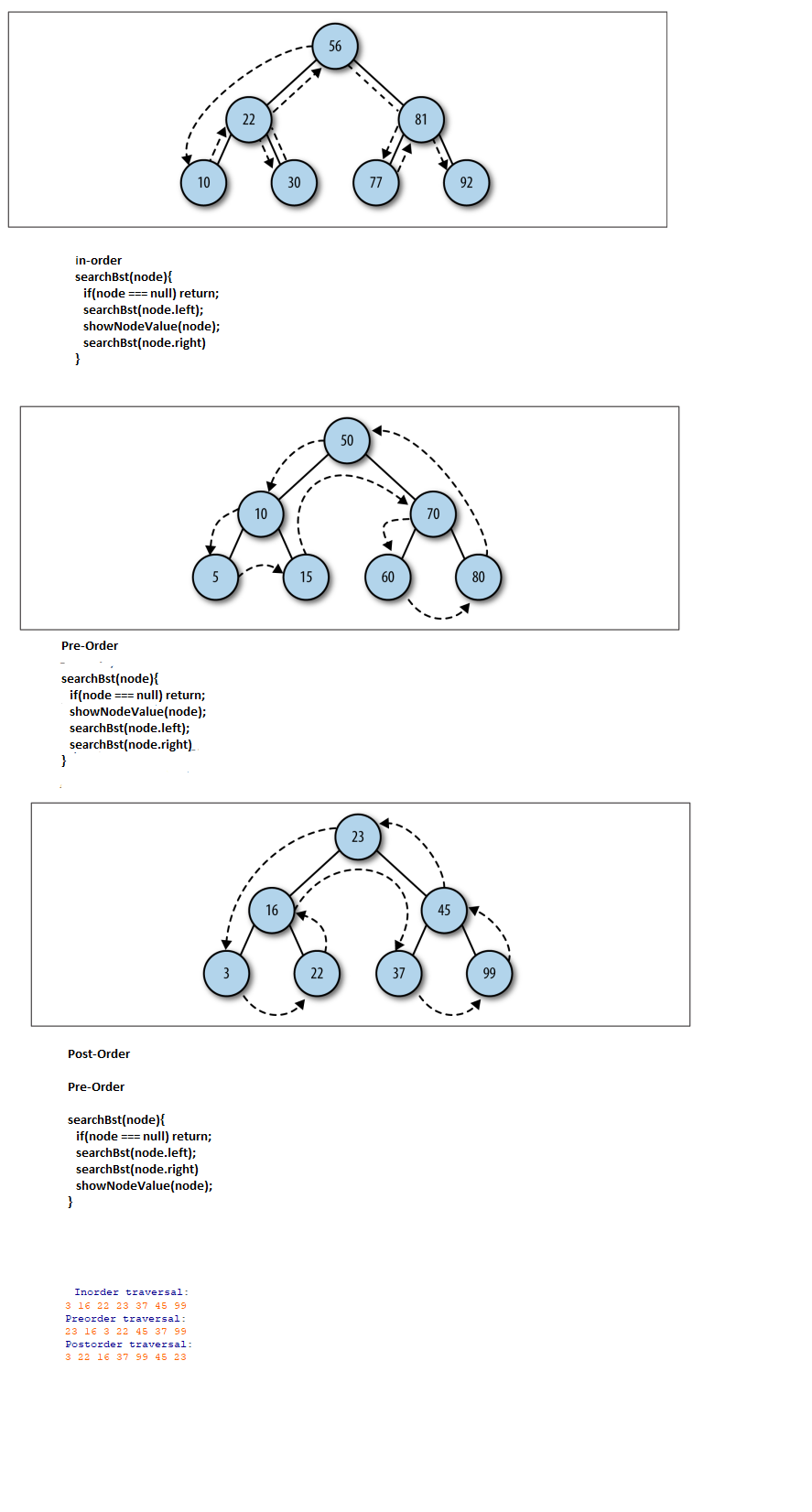
Search procedures in computer science are recursive functions that travel the trees edges (left node, right node) in a certain order, for different purposes.
These certain orders of traversal are inorder, preoder and postorder.
An in order function might look something like this:
searchBst(node){
if(node === null) return;
searchBst(node.left);
showNodeValue(node);
searchBst(node.right)
}
The stack that is opened here, first travel all the way down the left edges of the tree, then performs a procedure on each node, then opens up a stack for the right nodes. this way the lowest values are visited first.
in compersion see next slide.
BST Searching for the minimum & maximum value
Searching for minimum and maximum values with a binary search tree is quite simple.
For the minimum value you only have to travel the left edge of the tree.
function getMin() {
var current = this.root;
while (!(current.left == null)) {
current = current.left;
}
return current.data;
}
For the maximum value you just have to travel the right edge:
function getMax() {
var current = this.root;
while (!(current.right == null)) {
current = current.right;
}
return current.data;
}
BST Searching for a specific value
To search for a specific value you need to add a comparision fanction to decide which node to check next, the left or the right node.
function find(data) {
var current = this.root;
while (current.data != data) {
if (data < current.data) {
current = current.left;
}
else {
current = current.right;
}
if (current == null) {
return null;
}
}
return current;
}
Description
No tags specified
{kind=link}
Description
No tags specified
Show more
Show less
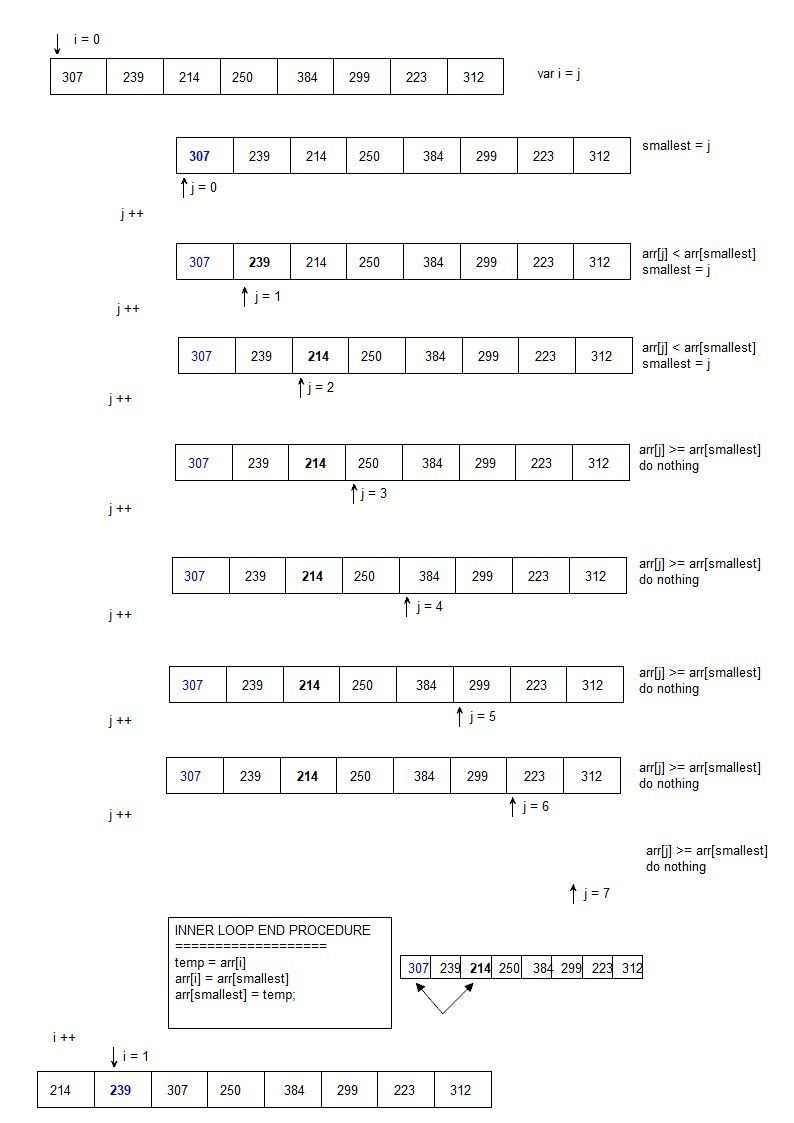
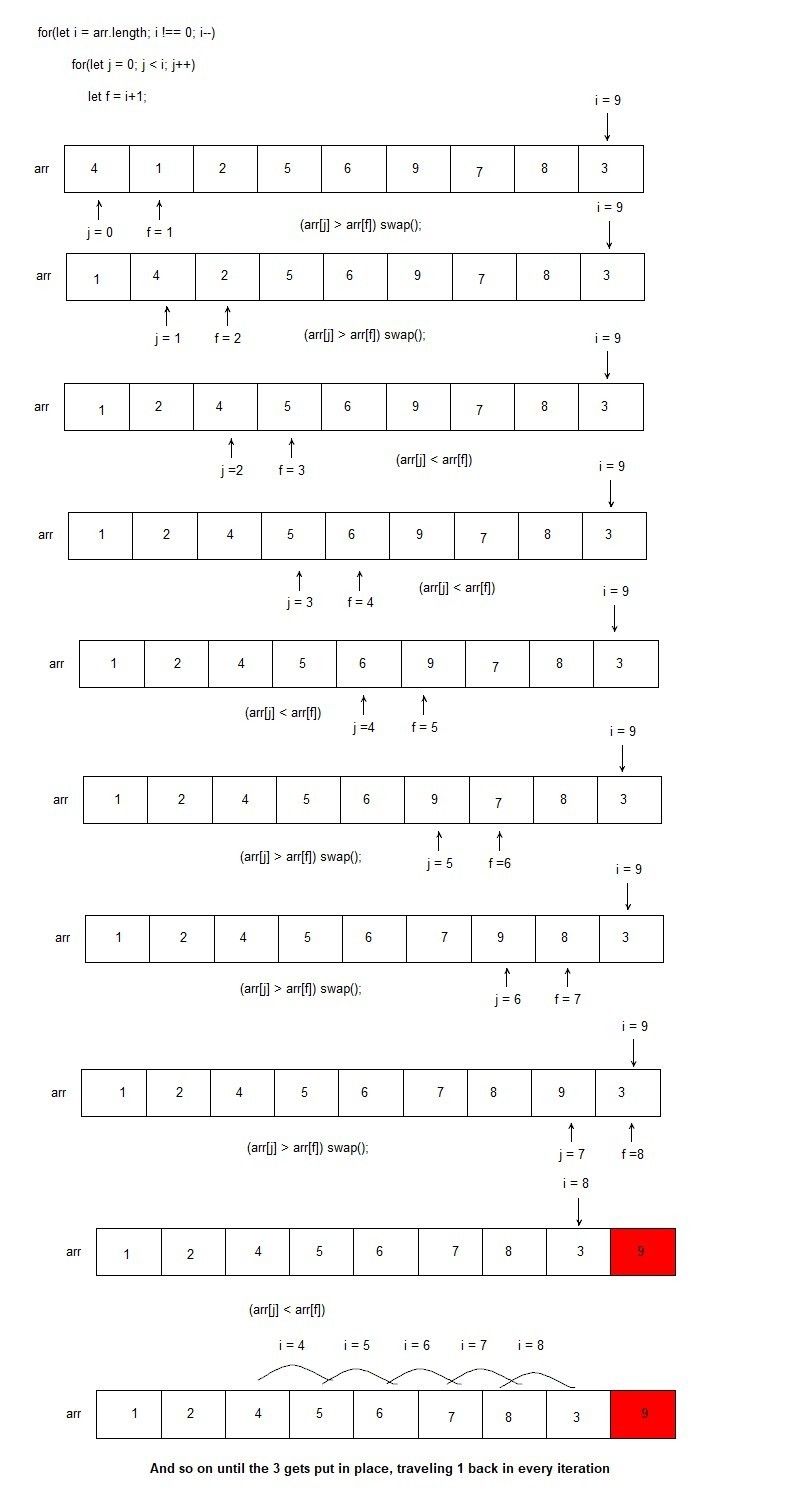
Looking at the Slection Sort we can define two nested loops:
1. First loop: iterating once over the whole array (8 elements)
2. Second loop: Iterating over the whole loop for each element out of the 8 of the first loop (decresing by 1 for each first loop progress).
example:
for( i = 0 ; i < arr.length ; i++){
//each time the i loop progresses by one, the j loop is shorter since it begins the loop one element higher.
(for j = i; j < arr.length; j++){
}
}
This means: If we want to sort n items, we have to loop n times, inside of which we loop n times, which gives us roughly a fun time of n*n or n^2 , which is considered very ineficient.
This relationship of input size to the number of steps the al7
Description
No tags specified
{kind=link}
Description
No tags specified
{kind=link}
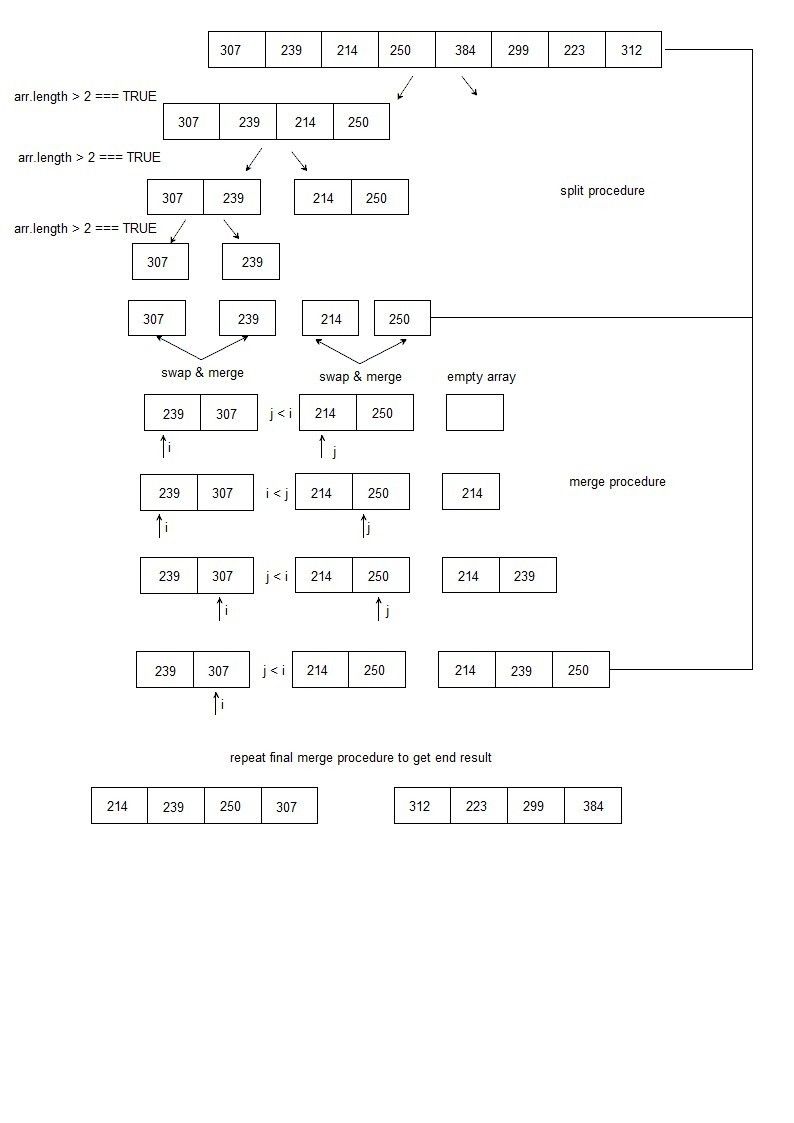{kind=link}
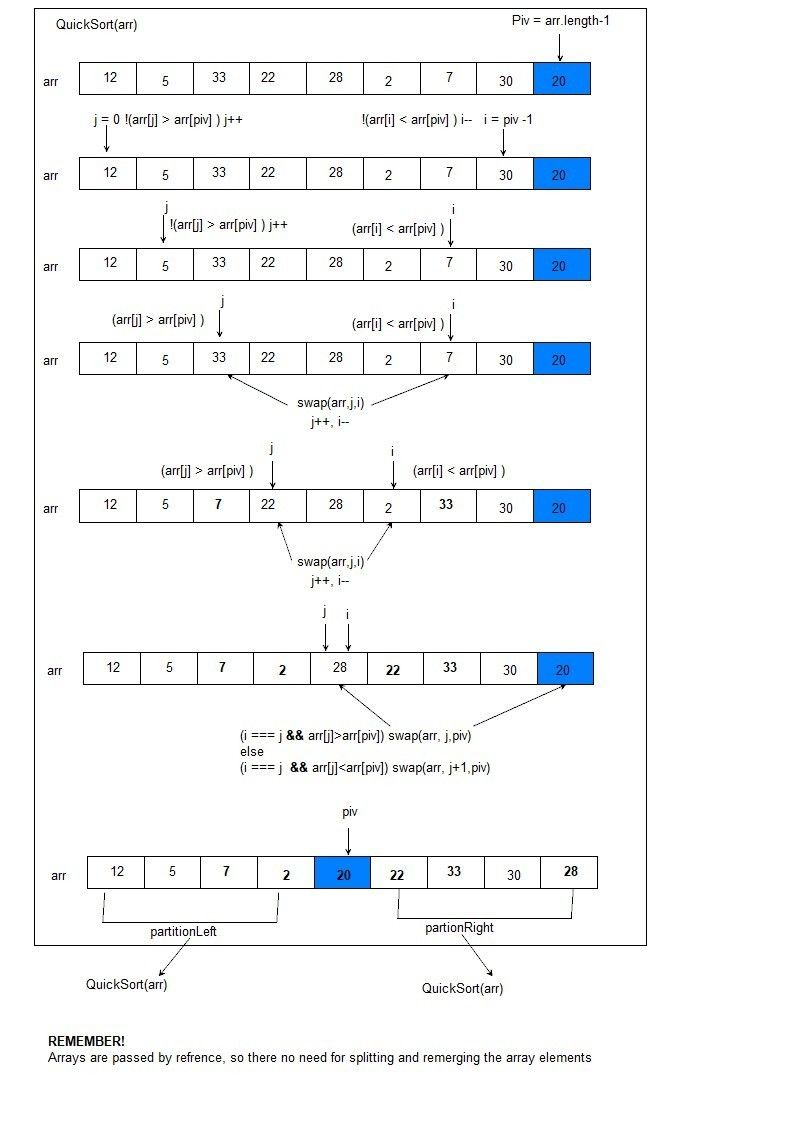{kind=link}
Description
No tags specified
Show more
Show less
Big O notation - Is a way to describe how slow, or fast a function is going to run with different input sizes.
consider the following code snippet:
def item_in_list(to_check, the_list):
for item in the_list:
if to_check == item:
return True
return False
The complication for this function is O(n).
what does O(n) means?
First we need to know what does Big-O mean.
O(n)
The O stands for "Order Of Magnitude" which is a mathematical term for dealing with different classes of numbers, for example the difference between 10 and 1,000.
The O() in turn is called the "Order Function".
When dealing with Orders of Magnitude we are dealing with approximations.
and O(n) is the approximation of the worst case scenario, which is the running the O-function (O()) n times (input size) to get wanted result (a return statement in our case). Its an approximation because we don't know the size of n, or the times it will have to execute to get the result, but we do know that worst case scenario is running n times.
You can represent O(n) in a graph plot, where the n would be swapped with x, representing the x axis (the different sizes of n), and y representing the time of execution for O(n).
Plotting our graph in that way will give us a straight diagonal line the will basically multiply for each x/n unit.
This means that it might run fast for n=1 but will be unbearably slow for n=1,000,000
This is the worst case scenario.
O(1)
Given the following function:
def is_none(item):
return item is None
I doesn't matter the size of the item you pass it, it will always execute in the same time.
Pass it million items or one items, it will just return something right away.
This means that the complication here is O(1), which is also called "static Time".
Its called static time because if we plot this one in a graph, like we did with O(n), we'll get a straight line, which is a constant time.
the Y axis always stays the same, no matter the size of X or n if you will.
Constant time or n(1) is considered the best case scenario for a function.
O(n^2)
consider the following function:
def all_combinations(the_list):
results = []
for item in the_list:
for inner_item in the_list:
results.append((item, inner_item))
return results
The above function will loop once over each list item (n), then with in that loop it will loop again over each item array to match it with the current item array.
So if you pass in [1,2,3] you will get: [[1,1],[1,2],[1,3],[2,1],[2,2]... [3,3]]
This means that you ran n times, and for every item in n you ran n times which means you ran n*n or n^2 times.
If you plot O(n^2) into a graph you'll get a curved line, which performance is even worse than O(n).
Sort algorithms worst case complexity:
Selection sort: О(n^2)
Bubble sort: О(n^2)
Merge sort: O(n log n)
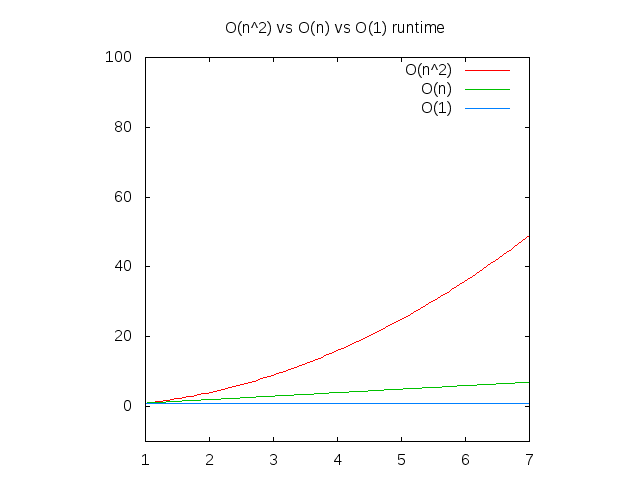{kind=link}