2035402
Beschreibung
Mindmap von nithi131993, aktualisiert more than 1 year ago
|
|
Erstellt von nithi131993
vor fast 10 Jahre
|
|
Data Preprocessing
- Why Preprocess the data?
- Consistency
Anmerkungen:
- Reduce representation of data set.
- Dimension Reduction Numerosity Reduction
- Data Transformation
Anmerkungen:
- Normalization,data discretization and concept hierarchy generation are forms of Data Transformation.
- Completeness
Anmerkungen:
- Integrating multiple databases,data cubes or files.
- Accuracy
Anmerkungen:
- There are many possible reasons for inaccurate data. For example,the age of a person must be enter within 100.
- Believability
Anmerkungen:
- Believability reflects how much the data are trusted by users.
- Interpretability
Anmerkungen:
- Interpretability reflects how easy the data are understood to users.
- Consistency
- Major Tasks in Data Preprocessing
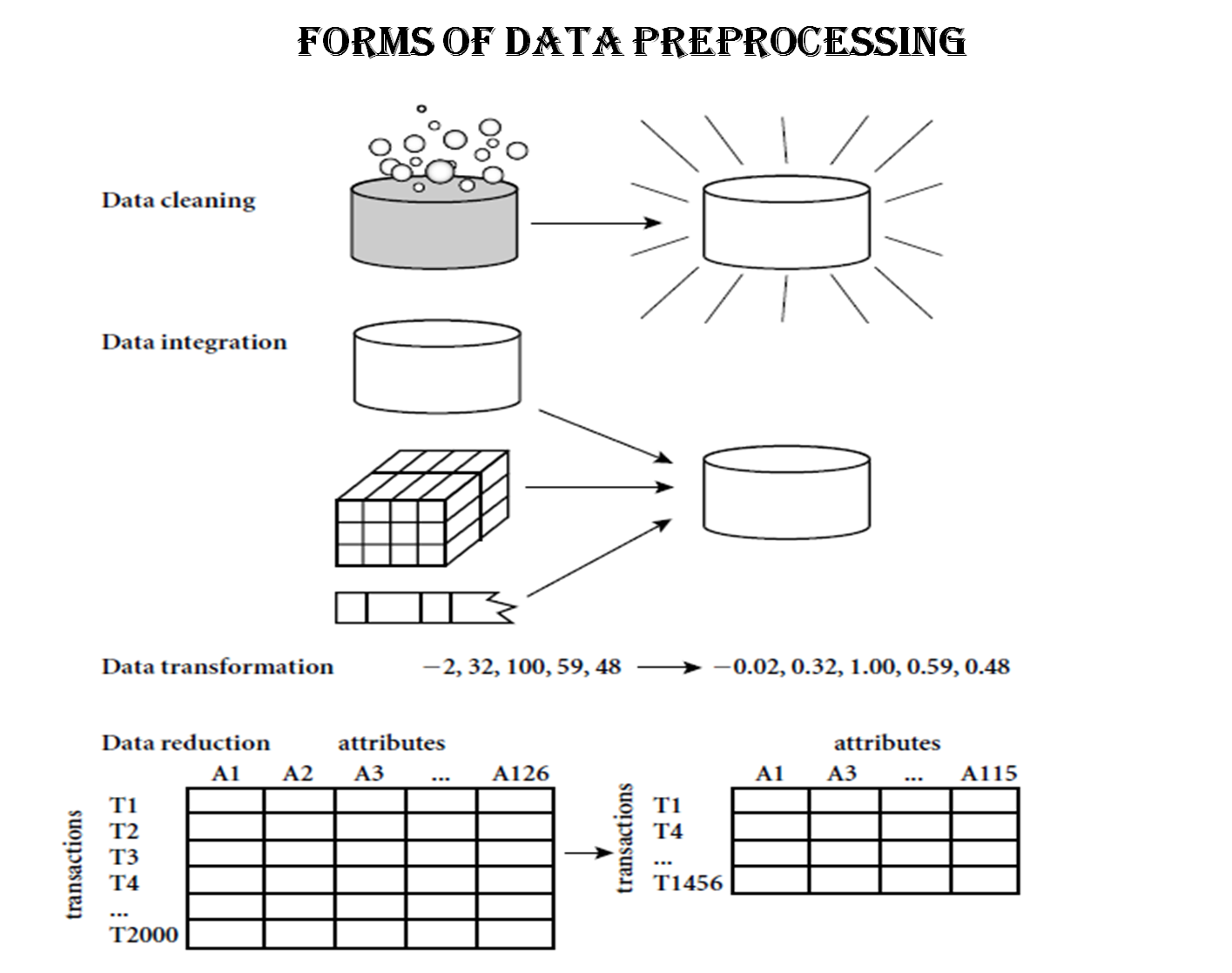
- Data Cleaning
Anmerkungen:
- To Clean the data by filling in missing values,smoothing noisy data,identifying or removing outliers, and resolving inconsistencies.
- 1. Missing Values. 2. Noisy Data. 3. Data Cleaning as a Process.
- Missing Values
Anmerkungen:
- 1. Ignore the tuple.
- 2. Fill in the missing value manually.
- 3. Use a global constant to fill in the missing value.
- 5. Use the attribute mean or median for all samples belonging to the same class as the given tuple.
- 6. Use the most probable value to fill in the missing value.
- Noisy Data
Anmerkungen:
- 1. Binning -> Smoothing by bin means.-> Smoothing by bin medians.-> Smoothing by bin boundaries.
- 2. Regression -> Linear Regression
- Data Cleaning as a Process
Anmerkungen:
- Rules Used: -> Unique Rule. -> Consecutive Rule. -> Null Rule.
- Tools Used: -> Data Subscribing Tools. -> Data Auditing Tools. -> Data Migration Tools.
- Data Integration
Anmerkungen:
- To integrate multiple databases,data cubes, or files.
- Redundancy and Correlation Analysis
Anmerkungen:
- Redundancy can be detected by Correlation Analysis.
- 1. Correlation Test for Nominal Data. 2. Correlation Coefficient for Numeric Data. 3. Covariance of Numeric Data.
- Entity Identification Problem
- Tuple Duplication
Anmerkungen:
- Duplication should also be detected at tuple level.
- Data Value Conflict Detection and Resolution
Anmerkungen:
- Data Integration also involves the detection and resolution of Data Value Conflicts.
- Data Transformation and Data Discretization
Anmerkungen:
- Normalization, data discretization, and concept hierarchy generation are forms of Data Transformation.
- Data Transformation Strategies
Anmerkungen:
- 1. Smoothing. 2. Attribute Construction. 3. Aggregation. 4. Normalization. 5. Discretization. 6. Concept Hierarchy Generation for nominal data.
- Data Transformation by Normalization
Anmerkungen:
- -> Min-Max Normalization. -> Z- Score Normalization. -> Decimal Scaling.
- Discretization by Binning
Anmerkungen:
- Binning is a top-down splitting technique based on a specified number of bins.
- Discretization by Histograms
Anmerkungen:
- Histogram analysis is an unsupervised discretization technique because it does not use class information.
- Discretization by Cluster,Decision
Tree and Correlation Analyses
- Concept Hierarchy
Generation for Nominal Data
Anmerkungen:
- 1. Specification of a partial ordering of attributes explicitly at the schema level by users or experts.
- 2. Specification of a portion of a hierarchy by explicit data grouping.
- 3. Specification of set of attributes,but not of their partial ordering.
- 4. Specification of only a partial set of attributes.
- Data Reduction
Anmerkungen:
- To obtain the reduced representation of the data set.
- Data Reduction Strategies
Anmerkungen:
- Dimensionality Reduction. Numerosity Reduction.
- Data Compression. -> Lossless. -> Lossy.
- Wavelet Transforms
Anmerkungen:
- Discrete Wavelet Transform.
- Principal Components Analysis
Anmerkungen:
- Also called Karhunen - Loeve method.
- Attribute Subset Selection
Anmerkungen:
- Reduces the data set size by removing irrelevant or redundant attributes.
- -> Step Forward Selection. -> Step Backward Elimination. -> Combination of both. -> Decision Tree Induction.
- Regression and Log - Linear Models
Anmerkungen:
- Linear Regression. Multiple Linear Regression. Log-Linear models.
- Histograms
Anmerkungen:
- Use binning to approximate data distributions and are a popular form of data reduction.
- -> Equal Width. -> Equal Frequency.
- Clustering
Anmerkungen:
- Clustering consider data tuples as objects. Centroid distance is an alternative measure of cluster quality.
- Sampling
Anmerkungen:
- Sampling can be used as a data reduction technique because it allows a large data set to be represented by a much smaller random data sample.
- Data Cleaning
Medienanhänge
{kind=link}
Möchten Sie kostenlos Ihre eigenen Mindmaps mit GoConqr erstellen? Mehr erfahren.