28203198
Beschreibung
Mindmap von JOSE ANGEL, aktualisiert more than 1 year ago
|
|
Erstellt von JOSE ANGEL
vor fast 4 Jahre
|
|
METODO DE
BUSQUEDA
- METODOS DE BUSQUEDA INTERNO
- Se denomina búsqueda interna cuando todos los elementos se encuentran en la memoria principal. Por
ejemplo, almacenados en estructuras estáticas (arreglos) o en estructuras dinámicas (listas ligadas y
arboles).
- El propósito principal de un ordenamiento es el de facilitar las búsquedas de los miembros del conjunto
ordenado.
- Se denomina búsqueda interna cuando todos los elementos se encuentran en la memoria principal. Por
ejemplo, almacenados en estructuras estáticas (arreglos) o en estructuras dinámicas (listas ligadas y
arboles).
- METODO DE BUSQUEDA EXTERNOS
- Se denomina búsqueda externa cuando todos los elementos se encuentran en memoria secundaria
(archivos almacenados en dispositivos tales como cintas y discos magnéticos).
- La búsqueda externa es aquella en la que todos los elementos se encuentran almacenados en un archivo,
el cual se encuentra en un dispositivo de almacenamiento secundario como un disco duro, una cinta o
una memoria USB.
- Se denomina búsqueda externa cuando todos los elementos se encuentran en memoria secundaria
(archivos almacenados en dispositivos tales como cintas y discos magnéticos).
- PARA QUE SIRVEN LOS METODOS DE BUSQUEDA
- El propósito principal de un ordenamiento es el de facilitar las búsquedas de los miembros del conjunto
ordenado. Son aquellos en los que los valores a ordenar están en memoria secundaria (disco, cinta,
cilindro magnético, etc), por lo que se asume que el tiempo que se requiere para acceder a cualquier
elemento depende de la última posición accedida (posición 1, posición 500, etc).
- El propósito principal de un ordenamiento es el de facilitar las búsquedas de los miembros del conjunto
ordenado. Son aquellos en los que los valores a ordenar están en memoria secundaria (disco, cinta,
cilindro magnético, etc), por lo que se asume que el tiempo que se requiere para acceder a cualquier
elemento depende de la última posición accedida (posición 1, posición 500, etc).
- METOD DE BUSQUEDA SECUNECIAL
- Búsqueda secuencial consiste en revisar elemento por elemento hasta encontrar el dato buscado, o hasta
llegar al final de la lista de datos disponible. La búsqueda secuencial, también se le conoce como búsqueda
lineal.
- Este método consiste en recorrer el arreglo o vector elemento a elemento e ir comparando con el valor
buscado (clave). Se empieza con la primera casilla del vector y se observa una casilla tras otra hasta que se
encuentre el elemento buscado o se han visto todas las casillas. El resultado de la búsqueda es un solo
valor, y será la posición del elemento buscado o cero. Dado que el vector o arreglo no está en ningún
orden en particular, existe la misma probabilidad de que el valor se encuentra ya se en el primer elemento,
como en el ultimo. Por lo tanto, en promedio, el programa tendrá que comparar el valor buscado con la
mitad de los elementos del vector.
- El método de búsqueda lineal funciona bien con arreglos pequeños o para arreglos no ordenados.
- Este método consiste en recorrer el arreglo o vector elemento a elemento e ir comparando con el valor
buscado (clave). Se empieza con la primera casilla del vector y se observa una casilla tras otra hasta que se
encuentre el elemento buscado o se han visto todas las casillas. El resultado de la búsqueda es un solo
valor, y será la posición del elemento buscado o cero. Dado que el vector o arreglo no está en ningún
orden en particular, existe la misma probabilidad de que el valor se encuentra ya se en el primer elemento,
como en el ultimo. Por lo tanto, en promedio, el programa tendrá que comparar el valor buscado con la
mitad de los elementos del vector.
- CARACTERISTICAS
- La búsqueda se puede realizar en arreglos desordenados.
- El método es totalmente confiable.
- El número de comparaciones es significativa si el arreglo es muy grande.
- En arreglos desordenados de N componentes puede suceder que el elemento no se encuentre, por lo
tanto se harán N comparaciones al recorrer todo el arreglo
- Cantidad mínima de comparaciones es 1.
- Cantidad media de comparaciones es (1+N)/2.
- Cantidad máxima de comparaciones es N.
- La búsqueda se puede realizar en arreglos desordenados.
- VENTAJAS Y DESVENTAJAS
- VENTAJAS
- Es un método sumamente simple que resulta útil cuando se tiene un conjunto de datos pequeños (Hasta
aproximadamente 500 elementos)
- Es fácil adaptar la búsqueda secuencial para que utilice una lista enlazada ordenada, lo que hace la
búsqueda más eficaz.
- Si los datos buscados no están en orden es el único método que puede emplearse para hacer dichas
búsquedas.
- Es un método sumamente simple que resulta útil cuando se tiene un conjunto de datos pequeños (Hasta
aproximadamente 500 elementos)
- DESVETAJAS
- Este método tiende hacer muy lento.
- Si los valores de la clave no son únicos, para encontrar todos los elementos con una clave particular, se
requiere buscar en todo el arreglo, lo que hace el proceso muy largo.
- Este método tiende hacer muy lento.
- VENTAJAS
- Búsqueda secuencial consiste en revisar elemento por elemento hasta encontrar el dato buscado, o hasta
llegar al final de la lista de datos disponible. La búsqueda secuencial, también se le conoce como búsqueda
lineal.
- METODO DE BUSQUEDA BINARIA
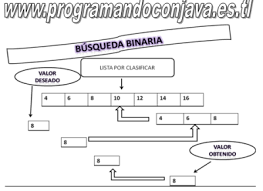
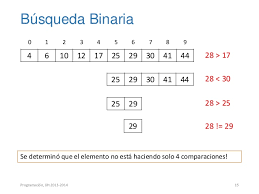
- La búsqueda binaria utiliza un método de `divide y vencerás' para localizar el valor deseado. Con este
método se examina primero el elemento central de la lista; si éste es el elemento buscado, entonces la
búsqueda ha terminado.
- En caso contrario, se determinar si el elemento buscado será en la primera o la segunda mitad de la lista y
a continuación se repite este proceso, utilizando el elemento central de esa sub-lista.
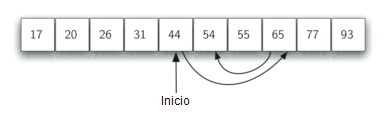
- La búsqueda binaria es el método, donde si el arreglo o vector está bien ordenado, se reduce
sucesivamente la operación eliminando repetidas veces la mitad de la lista restante.
- La búsqueda binaria es el método, donde si el arreglo o vector está bien ordenado, se reduce
sucesivamente la operación eliminando repetidas veces la mitad de la lista restante.
- En caso contrario, se determinar si el elemento buscado será en la primera o la segunda mitad de la lista y
a continuación se repite este proceso, utilizando el elemento central de esa sub-lista.
- CARACTERISTAS
- Sirve únicamente para arreglos ordenados.
- Es más eficiente que el método de búsqueda secuencial, debido a que el número de comparaciones se
reduce a la mitad por cada iteración del método.
- Cantidad mínima de comparaciones es 1.
- Cantidad media de comparaciones es (1+log2(N))/2.
- Cantidad máxima de comparaciones es log2(N).
- Sirve únicamente para arreglos ordenados.
- VENTAJAS Y DESVENTAJAS
- VENTAJAS
- Se puede aplicar tanto a datos en listas lineales como en árboles binarios de búsqueda.
- Es el método más eficiente para encontrar elementos en un arreglo ordenado.
- Se puede aplicar tanto a datos en listas lineales como en árboles binarios de búsqueda.
- DESVENTAJAS
- Este método funciona solamente con arreglos ordenados, por lo cual si nos encontramos con arreglos
que no están en orden, este método, no nos ayudaría en nada.
- Este método funciona solamente con arreglos ordenados, por lo cual si nos encontramos con arreglos
que no están en orden, este método, no nos ayudaría en nada.
- VENTAJAS
- La búsqueda binaria utiliza un método de `divide y vencerás' para localizar el valor deseado. Con este
método se examina primero el elemento central de la lista; si éste es el elemento buscado, entonces la
búsqueda ha terminado.
- METODO DE BUSQUE HASH
- VENTAJAS Y DESVENTAJAS
- VENTAJAS
- Una tabla hash tiene como principal ventaja que el acceso a los datos suele ser muy rápido si se cumplen
las siguientes condiciones:
- Una razón de ocupación no muy elevada (a partir del 75% de ocupación se producen demasiadas
colisiones y la tabla se vuelve ineficiente).
- Una función resumen que distribuya uniformemente las claves. Si la función está mal diseñada, se
producirán muchas colisiones.
- Una tabla hash tiene como principal ventaja que el acceso a los datos suele ser muy rápido si se cumplen
las siguientes condiciones:
- DESVENTAJAS
- Necesidad de ampliar el espacio de la tabla si el volumen de datos almacenados crece. Se trata de una
operación costosa.
- Desaprovechamiento de la memoria. Si se reserva espacio para todos los posibles elementos, se consume
más memoria de la necesaria; se suele resolver reservando espacio únicamente para punteros a los
elementos.
- Dificultad para recorrer todos los elementos. Se suelen emplear listas para procesar la totalidad de los
elementos.
- Necesidad de ampliar el espacio de la tabla si el volumen de datos almacenados crece. Se trata de una
operación costosa.
- VENTAJAS
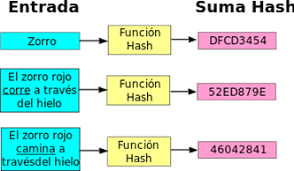
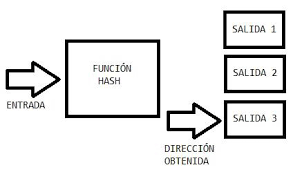
- Es un método de búsqueda que aumenta la velocidad de búsqueda, pero que no requiere que los
elementos estén ordenados. Consiste en asignar a cada elemento un índice mediante una transformación
del elemento.
- Esta correspondencia se realiza mediante una función de conversión, llamada función hash. La
correspondencia más sencilla es la identidad, esto es, al número 0 se le Unidad 6. Métodos de búsqueda
Pagina 9 asigna el índice 0, al elemento 1 el índice 1, y así sucesivamente. Pero si los números a
almacenar son demasiado grandes esta función es inservible.
- Esta correspondencia se realiza mediante una función de conversión, llamada función hash. La
correspondencia más sencilla es la identidad, esto es, al número 0 se le Unidad 6. Métodos de búsqueda
Pagina 9 asigna el índice 0, al elemento 1 el índice 1, y así sucesivamente. Pero si los números a
almacenar son demasiado grandes esta función es inservible.
- La función de hash ideal debería ser biyectiva, esto es, que a cada elemento le corresponda un índice, y
que a cada índice le corresponda un elemento, pero no siempre es fácil encontrar esa función, e incluso a
veces es inútil, ya que puedes no saber el número de elementos a almacenar. La función de hash
depende de cada problema y de cada finalidad, y se pueden utilizar con números o cadenas, pero las más
utilizadas son:
- Restas sucesivas:
- esta función se emplea con claves numéricas entre las que existen huecos de tamaño conocido,
obteniéndose direcciones consecutivas.
- esta función se emplea con claves numéricas entre las que existen huecos de tamaño conocido,
obteniéndose direcciones consecutivas.
- Aritmética modular:
- el índice de un número es resto de la división de ese número entre un número N prefijado,
preferentemente primo. Los números se guardarán en las direcciones de memoria de 0 a N-1. Este
método tiene el problema de que cuando hay N+1 elementos, al menos un índice es señalado por dos
elementos (teorema del palomar). A este fenómeno se le llama colisión, y es tratado más adelante.
- el índice de un número es resto de la división de ese número entre un número N prefijado,
preferentemente primo. Los números se guardarán en las direcciones de memoria de 0 a N-1. Este
método tiene el problema de que cuando hay N+1 elementos, al menos un índice es señalado por dos
elementos (teorema del palomar). A este fenómeno se le llama colisión, y es tratado más adelante.
- Mitad del cuadrado:
- consiste en elevar al cuadrado la clave y coger las cifras centrales.
- consiste en elevar al cuadrado la clave y coger las cifras centrales.
- Truncamiento:
- consiste en ignorar parte del número y utilizar los elementos restantes como índice. También se produce
colisión.
- consiste en ignorar parte del número y utilizar los elementos restantes como índice. También se produce
colisión.
- Plegamiento:
- consiste en dividir el número en diferentes partes, y operar con ellas (normalmente con suma o
multiplicación). También se produce colisión.
- consiste en dividir el número en diferentes partes, y operar con ellas (normalmente con suma o
multiplicación). También se produce colisión.
- Restas sucesivas:
- VENTAJAS Y DESVENTAJAS
Medienanhänge
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Möchten Sie kostenlos Ihre eigenen Mindmaps mit GoConqr erstellen? Mehr erfahren.