33534376
Beschreibung
Mindmap von VAQUIRO PERDOMO FREDY LEONEL, aktualisiert more than 1 year ago
|
|
Erstellt von VAQUIRO PERDOMO FREDY LEONEL
vor etwa 3 Jahre
|
|
Análisis estadístico inferencial
- Se calcula de una muestra de la población
- Prueba Hipótesis y Generalizar la muestra
- Datos == Estadigrafos
(Media aritmética o
desviación estándar de la
distribución)
- Pueden ser inferidos
- Procedimientos inferenciales
- Probar Hipótesis poblacionales
- Estimar parámetros
- Probar Hipótesis poblacionales
- Pueden ser inferidos
- Las Estadísticas de la población == Parámetros
(No son calculados, no es igual a toda la
población)
- Depende de elegir una muestra con un tamaño que
asegure un nivel de significancia
- Depende de elegir una muestra con un tamaño que
asegure un nivel de significancia
- Datos == Estadigrafos
(Media aritmética o
desviación estándar de la
distribución)
- Prueba Hipótesis y Generalizar la muestra
- ¿EN QUÉ CONSISTE LA PRUEBA DE HIPÓTESIS?
- Es una proposición a uno o varios parámetros
- Determinar si una Hipótesis es congruentes con
los datos obtenidos en la muestra
- Es una proposición a uno o varios parámetros
- ¿QUÉ ES LA DISTRIBUCIÓN MUESTRAL?
- Conjunto de valores sobre una estadística calculada de
todas las muestras posibles de determinado tamaño de una
población
- La muestra podría elegirse al azar y las veces que fuese necesarias
- En cada una de la muestras se obtendría una media
- Con estas elaborariamos una distribución de medias
- El calculo de la media de todas las medias de las muestras está la media de
la población
- Si la media calculada se encuentra cerca de la distribución muestral, podemos
tener una estimación precisa de la media poblacional ( se le llama: teorema
central del límite)
- Si la población tiene una media (m), y una desviación
estándar (s) la distribución de la medias del
muestreo aleatorea realizado en esta población
tiende al aumentar (n); a una distribución normal de
media (m) y distribución estándar (s/sqrt(n)), donde
(n) es el tamaño de la muestra
- Varianza == Varianza de la población entre el tamaño de la muestra
- Con base se creó un modelo de probabilidad llamada
curva normal o distribución normal
- Con base se creó un modelo de probabilidad llamada
curva normal o distribución normal
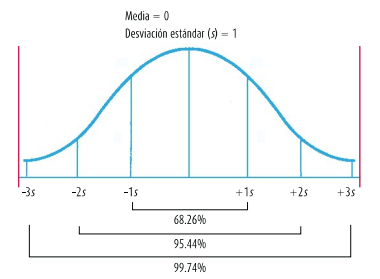
- CARACTERÍSTICAS
- Unimodal == una sola moda
- Asimetría == Cero, la mitad de la curva es igual a la otra.
- Función particular entre desviación
respecto a la media de la una distribución
y las probabilidades de que estas ocurran
- La base está dada en unidades de desviación
estándar ( puntuaciones z), destacando la s
puntuaciones, las distancias entre puntuaciones z
que representan áreas bajo la curva.
- La mesocúrtica (custosis de cero)
- La media, mediana y moda coinciden en el mismo punto (centro)
- Unimodal == una sola moda
- Conjunto de valores sobre una estadística calculada de
todas las muestras posibles de determinado tamaño de una
población
- ¿QUÉ ES EL NIVEL DE SIGNIFICACIA?
- Probabilidad de que un evento
ocurra está entre "cero y uno",
Cero == NO y Uno == SI
- Para probar la Hipótesis inferencial respecto a la Media,
el investigador evalua si es alta o baja la probabilidad de
que la Media de la muestra esté cerca de la media de la
distribución muestral.
- BAJA == DUDA (No generaliza la
población)
- ALTA == EXITOSA (Puede hacer
generalizaciones de la población)
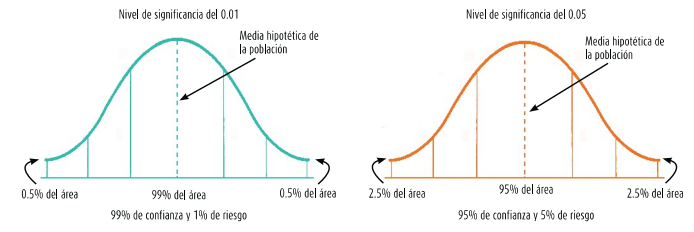
- PORCENTAJE DE CONFIANZA PARA GENERALIZAR (CERCANIA U ERROR)
- El nivel de significancia es de 0.05, el
invetigador cuenta con 95% de seguridad
(Ciencias sociales)
- El nivel de significancia es de 0.01, El
investigador cuenta 99% de seguridad
- El nivel de significancia es de 0.05, el
invetigador cuenta con 95% de seguridad
(Ciencias sociales)
- BAJA == DUDA (No generaliza la
población)
- Probabilidad de que un evento
ocurra está entre "cero y uno",
Cero == NO y Uno == SI
- DISTRIBUCIÓN MUESTRAL Y NIVEL DE SIGNIFICACIA (RELACIÓN)
- Se expresan en términos de probabilidad
- Para medir la confianza acudimos a la distribución muestral
- De dicho nivel lo tomamos como una área baja la distribución
muestral, dependiente si distribuimos el nivel del 0.05 y 0.01
- Se expresan en términos de probabilidad
- ¿SE PUEDE COMETER ERRORES AL PROBAR UNA HIPÓTESIS Y REALIZAR ESDISTICA INFERENCIAL?
- "No estariamos completamente seguros pero se puede caer en errores con riesgos mínimos"
- Aceptando una hipótesis verdadera
- Rechazar una Hipótesis falsa
- Aceptar una Hipótesis falsa "Error Beta"
- Rechazar una Hipótesis verdadera "Error Alpha"
- Aceptando una hipótesis verdadera
- Los dos tipos de error son indeseables. Sin embargo pueden reducirse sustancialmente la posibilidad
- Muestras probabilísticas representativas
- Inspeccíon cuidadosa de los datos
- Selección de las pruebas estadísticas apropiadas
- Mayor conocimiento de la población
- Muestras probabilísticas representativas
- "No estariamos completamente seguros pero se puede caer en errores con riesgos mínimos"
- PRUEBA DE HIPÓTESIS
- Existen dos tipos
- Análisis paramétricos
- SE PUEDEN USAR LAS DOS SEGÚN LA NECESIDAD
- Planteamiento
- Tipo de Hipótesis
- Nivel de medición
de las variables que
la conforman
- Planteamiento
- Distribución poblacional de la variable
dependiente es normal (El universo
tiene una distribución normal)
- El nivel de medición de la
variables es por Intervalos
o Razón
- Cuando dos o más poblaciones son estudiadas, tienen una
varianza homogénea ( poseen una dispersión similar en
sus distribuciones)
- MÉTODOS MÁS USADOS
- Coeficiente de correlación de Pearson y Regresión lineal
- Prueba estadística para analizar la relación
entre dos variables, medidas en un nivel por
intervalos o razón. (Coeficiente
producto-momento)
- Intervalos
- El signo indica la dirección de la
correlación (positiva o negativa). El valor
numérico la magnitud de la correlación
- METODOLOGÏA
- Simboliza: r
- Hipótesis a probar: Correlación del tipo de "a
moyor X, mayor Y", " amayor X, menor Y", "altos
valores en X,están asociados en altos valore en
Y", "altos valores en X e asocian con bajos
valores en Y"
- La Hipótesis señala que la correlación es significativa
- Variable: Dos, No evaluan
causalidad; se establece
teoricamente, pero la prueba
no asume dicha causalidad
- Se calcula de las puntuaciones de una muestra
de dos variables
- Se relaciona la puntuaciones
recolectadas de una variable con
puntuaciones obtenida de la otra
- Se calcula de las puntuaciones de una muestra
de dos variables
- Nivel de medición de las variables: Intervalos o razón
- Interpretación: Coeficiente r de
Pearson puede variar de -1 a +1, donde
-1 == correlación negativa perfecta
(Mayor X, Menor Y de manera
proporcional)
- Consideraciones: Cuando el coeficiente r de Pearson va al cuadrado es igua al "Coeficiente de
determinación". Su resultado indica la varianza de "factores comunes" que es el porcentaje de
variación de una variable debido a la variación de la otra variable y viceversa.
- El Coeficiente de determinación ofrece una buena predicción de
una variable respecto a la otra, y por encima de la variable con
mayor valor implica que ambas variables miden casí el mismo
concepto subyacente, "son cercanamente un constructo
semejante"
- Este coeficiente de correlación de Pearson es útil para
las relaciones lineales en la regresión lineal, pero no en
las curvilineales
- El Coeficiente de determinación ofrece una buena predicción de
una variable respecto a la otra, y por encima de la variable con
mayor valor implica que ambas variables miden casí el mismo
concepto subyacente, "son cercanamente un constructo
semejante"
- Simboliza: r
- Intervalos
- Qué es Regresión Lineal
- Modelo estadístico para estimar el efecto de una variable sobre otra.
- Asociado al Coeficiente r de Pearson
- Brinda la oportunidad de predecir las puntuaciones de una
variable a partir de las puntuaciones de otra variable
- Los diagramas de dispersión son una
manera de visualizar gráficamente una
correlación
- Si cada punto representa un caso y un
resultado de la intersección de las
puntuaciones de ambas variables. El
diagrama de dispersión puede ser
resumido a una linea si hay tendencia;
conociendo la línea y la tendencia
podemos predecir los valores de una
variable conociendo los valores de la
otra
- Se miden mediante la
evaluación de la pendiente
que es igual a ecuación de
relación lineal.
- y = variable dependiente a predecir
- a = la ordenada en el origen
- b = la pendiente o inclinación
- x = valor que fijados en la variable independiente
- y = variable dependiente a predecir
- Los diagramas de dispersión son una
manera de visualizar gráficamente una
correlación
- Entre mayor sea la correlacioón entre la variables (covariación), mayor
capacidad de predicción
- METODOLOGÏA
- Hipótesis: Correlaciones y causales
- Variables: dos, una dependiente y otra independiente, hay que
tenerse un buen sustento teoríco
- Nivel de medición de las variable: intervalos o Razón
- Procedimientos e interpretación: La regresión lineal se determina
con base en el diagrama de dispersión. Es una gráfica en el que
se relacionan las puntuaciones de una muestra en dos variables
- Consideraciones: La regresión lineal es útil con regresiones lineales
- Existen relaciones de causa-efecto que no son lineales
- Existen relaciones de causa-efecto que no son lineales
- Hipótesis: Correlaciones y causales
- Modelo estadístico para estimar el efecto de una variable sobre otra.
- Prueba estadística para analizar la relación
entre dos variables, medidas en un nivel por
intervalos o razón. (Coeficiente
producto-momento)
- Prueba t
- Es una prueba estadística para evaluar si dos grupos difieren entre sí de
manera significativa, respecto a sus medias en una variable
- Se basa en una distribución muestral o poblacional de
diferencia de media conocida como la distirbución t de
Student, que se identifica por los grados de libertad
(puede variar libremente)
- Cuanto mayor número de "grados de libertad" se
tenga, la distribución t de Student se acercará más
una distribución normal, se calcula con la formula
en la que n1 y n2 son el tamaño de los grupos que
se acompañan.
- La Ecuación sirve para hacer
contrastes de Género
- La Ecuación sirve para hacer
contrastes de Género
- Se basa en una distribución muestral o poblacional de
diferencia de media conocida como la distirbución t de
Student, que se identifica por los grados de libertad
(puede variar libremente)
- METODOLOGÍA
- Simboliza: t
- Hipótesis: Diferencia de dos
grupos, la Hipótesis nula plantea
que los grupos no difieren
- Variables: La comparación se realiza sobre una
variable, si hay diferentes variables se efectua varia
pruebas t. Una por cada variable y la razón que
motiva la creación de los grupos puede ser una
variable independiente
- Nivel de medición de la variable de comparación:
intervalos o razón
- Cálculo e interpretación: El valor t es cálculado por un
programa estadístico, de todos los resultados los más
necesarios para la interpretación, son el valor t y su
significancia
- Consideraciones: La prueba t se utiliza para
comparar los resultados de una preprueba con
los resultados de una posprueba en un cotexto
experimental
- Se comparan las medias y las varianzas del
grupo en dos momentos diferentes o bien
para comparar los prepruebas o pospruebas
de los grupos que participan en el
experimento. El nivel de confianza debe ser
menor de 0.05 o 0.01
- Se comparan las medias y las varianzas del
grupo en dos momentos diferentes o bien
para comparar los prepruebas o pospruebas
de los grupos que participan en el
experimento. El nivel de confianza debe ser
menor de 0.05 o 0.01
- Simboliza: t
- ¿QUÉ ES ELTAMAÑO DEL EFECTO?
- Se determina al comparar los grupo de
la prueba t
- Es una medida de la "fuerza" de las
medias y otros valores considerados
- Resulta ser una medida en unidades de
desviación estándar
- "La desviación estándar
sopesada es la estimación
reunida de la desviación
estándar de ambos grupos"
- Ne y Nc: Tamaño de los grupos (Grado de libertad)
- SDe y SDc: Son desviaciones estándar
- Ne y Nc: Tamaño de los grupos (Grado de libertad)
- "La desviación estándar
sopesada es la estimación
reunida de la desviación
estándar de ambos grupos"
- Se determina al comparar los grupo de
la prueba t
- Es una prueba estadística para evaluar si dos grupos difieren entre sí de
manera significativa, respecto a sus medias en una variable
- Prueba de contraste de las diferencias de proporciones
- Análisis de varianza Unidireccional ( ANOVA en un sentido)
- Análisis de varianza Factorial(ANOVA)
- Análisis de Covarianza (ANCOVA)
- Coeficiente de correlación de Pearson y Regresión lineal
- SE PUEDEN USAR LAS DOS SEGÚN LA NECESIDAD
- Anpalisis no Paramétricos
- Análisis paramétricos
- Existen dos tipos
Medienanhänge
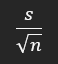{kind=link}
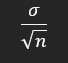{kind=link}
{kind=link}
{kind=link}
{kind=link}
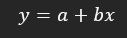{kind=link}
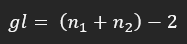{kind=link}
{kind=link}
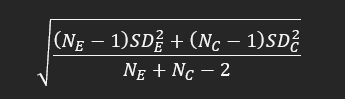{kind=link}
Möchten Sie kostenlos Ihre eigenen Mindmaps mit GoConqr erstellen? Mehr erfahren.