11341642
Beschreibung
Karteikarten von Lukas Berger, aktualisiert more than 1 year ago
|
|
Erstellt von Lukas Berger
vor mehr als 6 Jahre
|
|
| Frage | Antworten |
| Bei der Datenkodierung ist auch zu überlegen, wie mit fehlenden Werten umgegangen werden soll? >es gibt 2 Verfahren | Eliminierungsverfahren Imputationsverfahren |
| Was ist das Eliminierungsverfahren | Entfernung sämtlicher Antworten einer Person mit Missing Values Entfernung der jeweiligen Variable des Falls, die einen Missing Value aufweist |
| Imputationsverfahren | nicht-informative Vervollständigung, z. B. durch Variablenmittelwert oder Expertenratings Informative Vervollständigung, z. B. Nearest-Neighbor-Methode |
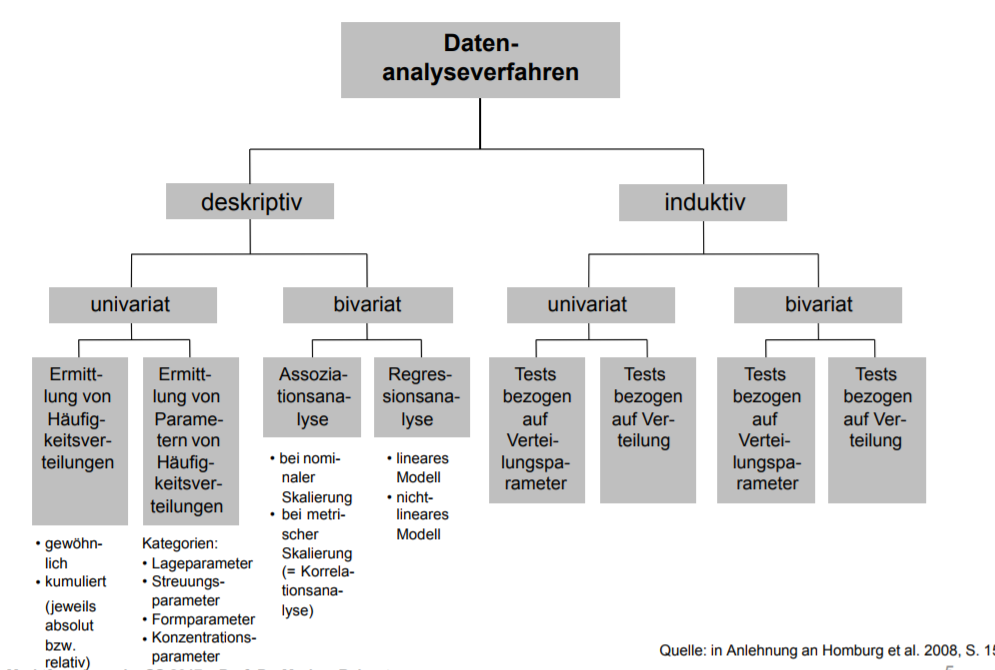
| Was ist ein Deskriptive Verfahren? | Deskriptive (beschreibende) Verfahren lassen lediglich Aussagen über die vorliegende Datenmenge zu. |
| Induktive Verfahren | Induktive Verfahren beruhen auf der Wahrscheinlichkeitstheorie und ziehen von der Stichprobenstruktur Rückschlüsse auf Strukturen in der Grundgesamtheit (Population). |
| Wichtige uni- und bivariate Verfahren der Datenanalyse im Überblick | |
| Deskriptive Statistik: Was sind Univariante Analyseverfahren ? | Betrachtung einer Stichprobe von n metrisch skalierten Elementen (Merkmalsträgern) Die Elemente haben k unterschiedliche Merkmalsausprägungen k = Anzahl der unterschiedlichen Merkmalsausprägungen |
| Median: | (Zentralwert) - Merkmalsausprägung desjenigen Elements, das in der, der Größe nach geordneter Beobachtungsreihe, in der Mitte steht. |
| Modus : | Häufigster Wert |
| Quartil0,25 | 0,5 | 0,75 | bezeichnet die Differenz zwischen dem oberen und dem unteren Quartil, und umfasst daher 50 % der Verteilung. Der Quartilsabstand wird als Streuungsmaß verwendet. |
| Varianz | arithmetisches Mittel der Abweichungsquadrate, beschreibt die erwartete quadratische Abweichung der Zufallsvariablen von ihrem Erwartungswert |
| Standartabweichung | Wurzel der Varianz - Begriff der Statistik und der Wahrscheinlichkeitsrechnung und ein Maß für die Streuung der Werte einer Zufallsvariablen um ihren Erwartungswert |
| Variationskoeffizient | Der Variationskoeffizient ist eine Normierung der Varianz: Ist die Standardabweichung größer als der Mittelwert bzw. der Erwartungswert, so ist der Variationskoeffizient größer 1. |
| Spannweite (Range) | Höchster – niedrigster Wert |
| Was sind Bivariate Analyseverfahren ? | • Verfahren zur Bestimmung der Stärke linearer Zusammenhänge zwischen zwei metrisch skalierten Variablen • Grundlage vieler multivariater Verfahren – Korrelationskoeffizient r bei einer Stichprobe n mit Wertepaaren Wertebereich zwischen [-1;1] |
| • Beispiel: Hängen Preis und Abverkaufsmenge linear zusammen? | =starker gegensinniger (-) statistischer Zusammenhang |
| Wie funktioniert die Einfache (bivariate) Regressionsanalyse? | • Analyse einseitiger Abhängigkeiten zwischen zwei Variablen > unabhängige Variable (x) > abhängige Variable (y) • Ermittlung einer (linearen) Schätzfunktion: y = a + b·x • Ermittlung der Koeffizienten a und b zur möglichst guten Anpassung der Regressionsgeraden an die empirischen Daten • Schätzung mit der Methode der kleinsten Fehlerquadratsummen |
| •Was ist die Variation der abhängigen Variablen? | = erklärte Streuung + nicht erklärte Streuung – Erklärte Streuung: auf unabhängige Variable zurückzuführen – Nicht erklärte Streuung: Effekte anderer Einflussfaktoren |
| • Was bestimmt das Bestimmtheitsmaß r^2 ? | – Wertebereich zwischen [0;+1] – Beurteilung der Güte der Regressionsfunktion |
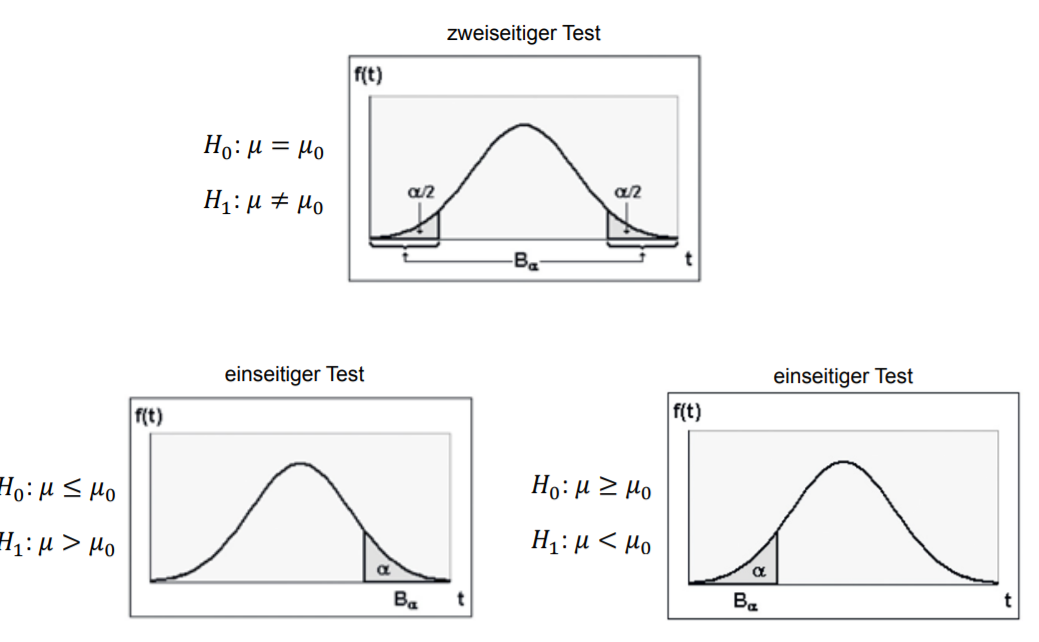
| Verfahren der induktiven Statistik Was ist die Allgemeine Vorgehensweise bei Signifikanztests? | 1.Formulierung von Nullhypothese und Gegenhypothese 2.Festlegung des Signifikanz Niveaus 3.Auswahl eines geeigneten statistischen Testverfahrens 4.Ermittlung des Ablehnungsbereichs 5.Berechnung des Wertes der Prüfgröße 6.Anwendung der Entscheidungsregel und Interpretation |
| Einseitiger vs. zweiseitiger Test | |
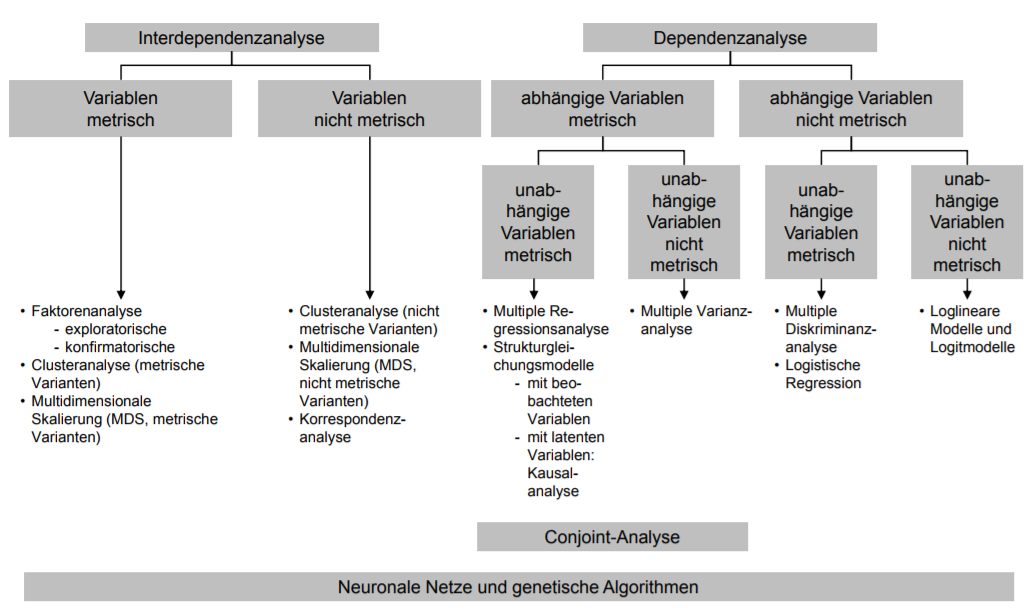
| Wichtige multivariate Datenanalyseverfahren im Überblick | |
| Bestimmung der Güte eines Regressionsmodells: | • Signifikanz einzelner Variablen über t- bzw. p-Wert • Signifikanz des gesamten Regressionsmodells über Varianzanalyse (ANOVA) • Bestimmtheitsmaß R 2: Anteil der durch das Regressionsmodell erklären Varianz der abhängigen Variable. |
| Prüfungskriterien der Anwendung einer linearen Regression • 4 Anwendungsvoraussetzungen: | – Linearer Zusammenhang zwischen den Variablen – Homoskedastizität – Autokorrelation bzw. Unkorreliertheit der Residuen – Normalverteilung der Residuen |
| • Wo wird es Problematisch: | – Multikollinearität, d. h. Korreliertheit der unabhängigen Variablen untereinander – Ausreißer, d. h. Extremwerte |
| •Wie sieht die Interdependenzanalyse aus? | • Variablen metrisch • Variablen nicht metrisch |
| •Wie schaut die Dependenzanalyse aus? | • abhängige Variablen metrisch • abhängige Variablen nicht metrisch |
| Präferenzmessung / Conjointanalyse • was ist Präferenz ? | = Nutzen bzw. Ausmaß der Vorziehenswürdigkeit girlt als Erklärung von (Kauf-)Entscheidungen |
| •Was ist das Ziel der quantitativen Präferenzanalyse? | Messung des Nutzen für einzelne Produkteigenschaftsausprägungen |
| • Was sind die 2 Formen der Messung? | – Direkte Befragung, z. B. Self-Explicated-Methode – Indirekte Befragung, z. B. Conjoint-Analyse |
| Erklärung Conjoint Analyse (Präferenzmessung) | Conjoint-Analyse („ganzheitlich betrachtet“), ist eine multivariate Methode, bei der es neben der Messung und Bewertung eines Gutes auch um die Ermittlung des Anteils einer einzelnen Komponente (Variable) am Gesamtnutzen geht. Dazu werden bestimmte Eigenschaften des Gutes (Stimuli) mit bestimmten Bedeutungsgewichten versehen, um daraus ein möglichst allgemein gültiges Gesamt-Präferenzurteil der Verbraucher über das Gut ableiten zu können. |
| Eigenschaften der Conjoint Analyse (Präferenzmessung) | • Bewertung verschiedener Produkte (Stimuli) • Stimuli sind als Bündel von Eigenschaften beschrieben • Somit Trade-off zwischen Eigenschaften notwendig • Bewertung über – Auswahl aus Alternativensets (Choice-based Conjoint-Analyse) – Rating oder Ranking (klassische Conjoint-Analyse) • Realitätsnäher als direkte Präferenzabfrage |
| 3 Formen der Interpretation der Conjoint Analyse: | • die relative Bedeutung der Teilmerkmale, • Simulationsrechnungen (Präferenzen bei verschiedenen Merkmalskonstellationen) • Attraktionsmodelle |
| Attraktionsmodelle Annahme: Es besteht ein Zusammenhang zwischen dem gemessenen Nutzen und dem Kaufverhalten | • Die durchschnittliche Kaufwahrscheinlichkeit aller Probanden wird als Marktanteil interpretiert. • Jede Marke / jedes Produkt erhält den Marktanteil gemäß ihrer relativen Attraktionskraft. |
{kind=link}
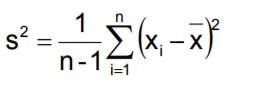{kind=link}
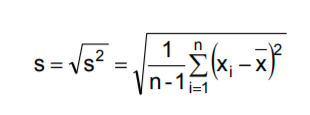{kind=link}
{kind=link}
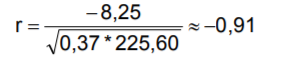{kind=link}
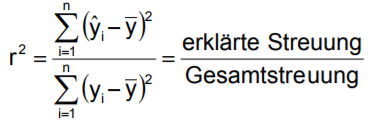{kind=link}
{kind=link}
{kind=link}
{kind=link}
Möchten Sie mit GoConqr kostenlos Ihre eigenen Karteikarten erstellen? Mehr erfahren.