Description
|
|
Created by Thomas Welford
almost 12 years ago
|
|
Page 1
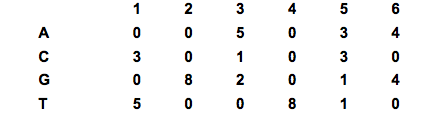
1) Start with data that was used to create consensus (here sequences thought to contain similar motifs)
2) Related sites are discovered using a search engine
3) Align sequences and then score each of the six positions
4) New sequences can gain score for who close they match = product of each score
PROBLEMS:1) Anything times by 0 = 02) Does not take into account G and C content
SOLUTION1) Pseudocounts2) Background frequency of particular nucleotide in genome
5) Final formula: Score (position, nucleotide) = (q+p)/(N +B)
Key:q = observed counts for the nucleotide at the given p = weighted pseudocounts = B * (overall frequency of nucleotide) = 0.1*(0.32) N = total number of sequences (= maximum number of observed counts) = 8 B = total number of allocated pseudocounts = 0.1
6) Total score = Product of score at each position
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
PSSM - What is it?
Question
Answer
Want to create your own Notes for free with GoConqr? Learn more.