10400133
Description
Flashcards by ANGELLY ARAUJO, updated more than 1 year ago
|
|
Created by ANGELLY ARAUJO
about 7 years ago
|
|
| Question | Answer |
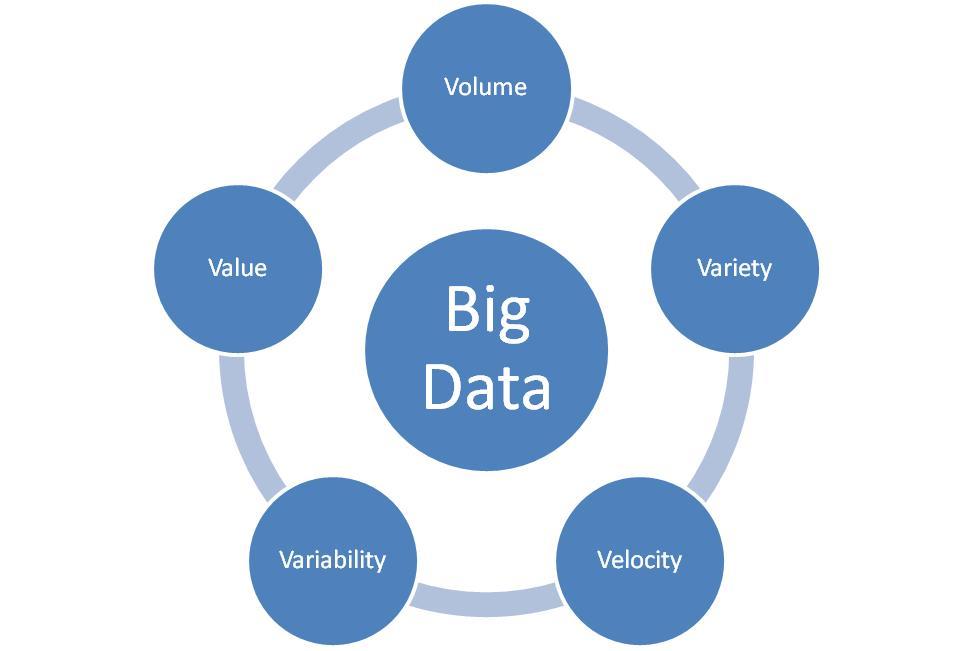
| BIG DATA | CARACTERÍSTICAS -Gran volumen -Velocidad -Variedad -Veracidad de los datos -Valor intrínseco |
| SMART DATA Su objetivo es filtrar el ruido, y mantener los datos valiosos, que pueden ser utilizado para toma de decisiones inteligentes. | CARACTERÍSTICAS -Veracidad de los datos -Valor de los datos |
| TRES ASPECTOS ESENCIALES EN EL USO DE LOS DATOS a). EXACTOS: Los datos deben ser lo que se dice, es importante la calidad. b).PROCESABLES: Los datos deben ser escalables para su procesamiento. c). ÁGILES: Los datos deben estar disponibles y preparados para adaptarse al entorno cambiante delos negocios. | Para la mayoría de problemas actuales con datos masivos es necesario el uso de una solución distribuida escalable por que las soluciones secuenciales no son capaces de abordar tales magnitudes. Varias plataformas han intentado afrontar la problemática del Big Data. |
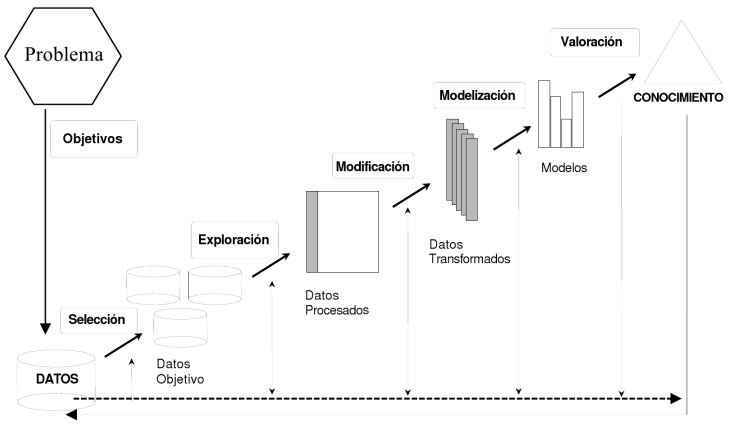
| PREPROCESAMIENTO DE DATOS Es una etapa esencial del proceso de descubrimiento de información.Esta etapa se encarga de la limpieza de datos, su integracion, transformación y reducción para la siguiente fase de minería de datos | |
| El uso de datos de baja calidad implica un proceso de minería de datos con pobres resultados , para esto es necesario aplicar las técnicas de preprocesamiento. | El preprocesamiento incluye un rango alto de técnicas que se pueden agrupar en dos áreas: -Preparación de datos. -Reducción de datos. |
| PREPARACIÓN DE DATOS Esta formada por una serie de técnicas que tiene como objetivo de inicializar correctamente los datos que servirán de entrada para los algoritmos de minería de datos | Este tipo de técnicas es de uso obligatorio por que sin ellas los algoritmos de extracción de conocimiento no se podrían ejecutar u ofrecería resultados erróneos. |
| REDUCCIÓN DE DATOS Se orienta a obtener una representación reducida de los datos originales, manteniendo en lo posible la integridad y la información existente de los datos . | La aplicación de técnicas de reducción no se considera obligatoria. Sin embargo si el tiempo de ejecución de un algoritmo o el tamaño de los datos son prohibitivos para los algoritmos de extracción, estas técnicas deben ser aplicadas. |
| las técnicas de reducción de datos mas relevantes son: -La selección de atributos -La selección de instancias -La discretizacion | BIG DATA El ritmo actual de datos esta sobrepasando las capacidades de procesamiento de los sistemas actuales en compañías y organismos públicos |
| La necesidad de procesar y extraer conocimiento valioso de esa inmensidad de datos es un desafió para cientificos de datos y expertos en la materia. | TECNOLOGÍAS PARA BIG DATA La tecnologia y algoritmos sofisticados y novedosos son necesarios para procesar eficientemente lo que se conoce como Big Data. |
| Los nuevos esquemas de procesamiento debe ser diseñados para procesar conjunto de datos grandes, datos masivos, dentro de un rango de precisión adecuado. | Gloogle diseño MapReduce en 2003, es considerada la plataforma pionera para el procesamiento de datos masivos, ya que es capaz de procesar grandes conjuntos de datos. |
| En el paradigma MapReduce existen dos faces: -Map -Reduce | MAP El sistema procesa parejas clave-valor leídas directamente del sistema de fichero, y transforma estos pares en otros intermedios |
| REDUCE En esta fase los pares con claves coincidentes son enviadas al mismo nodo y finalmente fusionados usando una función definida por el usuario. | A pesar de su popularidad a mostrado limitaciones con ciertos escenarios, principalmente en la reutilización de datos, como los procesos de grafos . |
| APACHE SPARK Nace como una alternativa para solucionar las limitaciones de MapReduce. Se a convertido en una de las herramientas mas populares en el ecosistema del Big Data | Es perfecto para procesos iterativos donde un mismo dato es reutilizado varias veces para el procesamiento de algoritmos sobre grafos. |
| APACHE FLINK Esta plataforma intenta llenar el hueco entre el procesamiento en tiempo real y el secuencial dejado por Spark. Es una plataforma distribuida para flujos de datos que también pude trabajar con datos secuenciales. | Flink muestra un buen rendimiento en el procesamiento de datos en sistemas de baja latencia. |
| HERRAMIENTAS PARA LA ANALÍTICA DE DATOS MASIVOS Han surgido varias herramientas de analítica de datos escalables con el objetivo de dar soporte al proceso de análisis de datos | HERRAMIENTAS DE ANALÍTICA -MAHOUT: Ofrece implementaciones basadas en Hadoop MapReduce para varias tareas de analítica de datos como el agrupamiento, la clasificación o el filtrado colaborativo. |
| -MLlib: Es una biblioteca de aprendizaje automático que contiene varias utilidades estadísticas y algoritmos de aprendizaje . | -FlinkML: Incluye algoritmos escalables para tareas como la clasificación, el agrupamiento, el preprocesamiento de datos y la recomendación. Aunque esta lejos de ofrecer la variedad de otras bibliotecas como MLlib. |
| -H2O: Es una plataforma de código abierto para análisis de Big Data. H2O destaca por sus implementaciones iterativas, ademas de que puede ejecutarse en sistemas tradicionales (windows, linux), así como en plataformas Big Data (Spark). | PREPROCESAMIENTO DE BIG DATA 1. Herramientas para analítica de datos 2. Uso de algoritmos de selección de atributos escalable sobre un problema de alta dimensionalidad. |
| ALGORITMOS DE PREPROCESAMIENTO DE DATOS MASIVOS Algoritmos de preprocesamiento disponible en las herramientas de analítica de datos. | MLlib destaca como la herramienta que ofrece una mayor variedad de métodos de preprocesamiento: |
| *DISCRETIZACIÓN Y NORMALIZACIÓN: Discretización: Transforma atributos continuos usando intervalos discretos. Normalización: Realiza un ajuste a la distribución. | ALGORITMOS -Binarización -Discretización manual -Normalizadores basados en min-max o media-varianza. |
| EXTRACCIÓN DE ATRIBUTOS Combina el conjunto original de atributos para obtener un nuevo conjunto de atributos menos redundantes, usando proyecciones. | ALGORITMOS -Principal Component Analysis (PCA) -Single Value Decomposition (SVD) |
| SELECCIÓN DE ATRIBUTOS Selecciona subconjuntos de atributos minimizando la pérdida de información | ALGORITMOS -Chi-cuadrado -RFormula |
| CONVERSORES PARA ATRIBUTOS Utilizando técnicas de indexación o codificación transforma atributos de un tipo a otro. | ALGORITMOS -OneHotEncoder |
| TÉCNICAS PARA EL PREPROCESAMIENTO DE TEXTO Su objetivo es estructurar la entrada de texto,produciendo patrones de información estructurados. | ALGORITMOS -Term Frequency-Inverse Document Frequency . |
| En la biblioteca FlinkML encontramos tres métodos de procesamiento actualmente: -Un algoritmo que transforma un conjunto de atributos aun espacio polinominal. -Dos algoritmos para normalización | H2O ofrece algunos algoritmos de extracción de atributos como PCA, así como algunos métodos para normalización. |
| Mahout solo ofrece algoritmos para reducción de dimensionalidad como, SVD, QR Decomposition. | Es necesario un mayor esfuerzo en el desarrollo de algoritmos de preprocesamiento en nuevas plataformas naturalmente iterativas, como Spark o Flink dado el bajo numero de propuestas existentes. |
| CASO DE USO: SELECCIÓN DE ATRIBUTOS ESCALABLES, ALGORITMO Fast-mRMR Esta propuesta incluye varias optimizaciones a la eficiencia del algoritmo original mRMR una de las más populares en su ambito | Fast-mRMR es capaz de trabajar con conjuntos de datos masivos en ambas dimensiones # de atributos y # de instancias |
| OPTIMIZACIONES MAS RELEVANTES INTRODUCIDAS POR FAST-mRMR | 1.REDUNDANCIA ACUMULADA Desarrolla una aproximación voraz al problema de cálculo de importancia de atributos. El algoritmo almacena la redundancia calculada en cada iteración para evitar cálculos innecesarios. |
| 2. RE-UTILIZACIÓN DE CÁLCULOS PREVIOS Almacena algunos datos importantes para su reutilización cuando son calculados por primera vez | 3. PROCESAMIENTO POR COLUMNAS Los datos iniciales son transformados en una lista de columnas para que de esta manera los cálculos entre atributos se tornan mas sencillos de realizar |
| CONCLUSIÓN Se estudia la importancia del preprocesamiento de los datos en Big Data, herramientas de analítica de datos y técnicas y algoritmos disponibles para el preprocesamiento de datos masivos. | El numero de propuestas es muy bajo en comparación con el numero de algoritmos en minería de datos |
| Para el Big Data es necesario diseñar nuevos algoritmos que se centren en problemas como selección de instancias o el tratamiento de datos imperfectos. | El Smart Data es una gran mina a explotar, datos almacenados que poseen un gran valor, pero que necesitan ser tratados ,refinados y preprocesados mediante las herramientas de analítica de datos |
{kind=link}
{kind=link}
Want to create your own Flashcards for free with GoConqr? Learn more.