10404699
Description
Mind Map by Aleksandar Kovacevic, updated more than 1 year ago
More
|
|
Created by Aleksandar Kovacevic
over 8 years ago
|
|
|
|
Copied by Aleksandar Kovacevic
over 8 years ago
|
|
Neural Networks -
Data Analysis
- Tuning
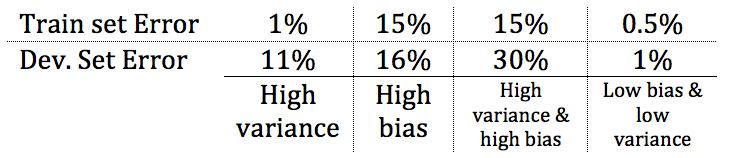
- High Bias
- Data is too roughly modelled (underfitting)
- Bigger Network
- Train Longer
- NN architecture search
- Data is too roughly modelled (underfitting)
- High Variance
- Data is too good modelled (overfitting)
- More Data
- Regularization
- Weight Decay
- L2 regularization : add (lamba/2*m)* ||W||F to cost
- L1 regularization: add (lamba/2*m)* ||W||F to cost
- Regularization required also to partial differential: W= W-alpha*dW
- Intuition for param Lambda: Lambda goes High -> weights goes low -> makes NN more linear
- L2 regularization : add (lamba/2*m)* ||W||F to cost
- Dropout
- Randomly take out certain neurons from network
- Randomly take out certain neurons from network
- Data Augmentation
- Adding more training data of distorting existing data
- Adding more training data of distorting existing data
- Early Stopping
- Stop earlier, where train error and dev error are at min
- Stop earlier, where train error and dev error are at min
- Weight Decay
- Data is too good modelled (overfitting)
- Optimization
Problem
- Data not
normalized ->
slower training
process
- Normalize data to have mean=0, and
std=1
- Vanishing/ exploding
gradients
- Deep network have issue of
becomming to high or two low
throughout network
- Deep network have issue of
becomming to high or two low
throughout network
- Gradient Checking
- Compare cost function, when
increased and decreased by small
value epsilon
- Compare cost function, when
increased and decreased by small
value epsilon
- Optimization
Algorithms
- Mini-Batch
gradient
descent
- Split the input and output (X,Y) data into small slices /
batches, and calculate costs of only these batches
- Choosing Batch Size
- small set (m<=2000) ->
batch gradient descent
- larger set -> batch size:
64,128,256 or 512
- Make sure batch fits CPU/GPU
mem
- small set (m<=2000) ->
batch gradient descent
- Split the input and output (X,Y) data into small slices /
batches, and calculate costs of only these batches
- Exponentially
weighted
averages
- Weights are recalculated
based on formula
- Bias Correction
- Corrects the starting values of exp.
weighted averages using the formula:
v(t)=v(t)/(1-beta^t)
- Corrects the starting values of exp.
weighted averages using the formula:
v(t)=v(t)/(1-beta^t)
- Weights are recalculated
based on formula
- Gradient
Descent with
Momentum
- Aim: accelerator horizontal component of
gradient descent to converge faster towards
solution. Based similarly on formula for
exp.weighted averages, just with gradient
instead of theta
- Aim: accelerator horizontal component of
gradient descent to converge faster towards
solution. Based similarly on formula for
exp.weighted averages, just with gradient
instead of theta
- RMSprop
- Aim to slower the vertical component of
gradient descent and speed up the
horizontal component.
- Aim to slower the vertical component of
gradient descent and speed up the
horizontal component.
- Adam
- Combination of
RMSprop and
Gradient Descent
with momentum
- Hyperparameter choice: alpha :
needs to be tuned, beta1 = 0.9,
beta2 = 0.999, epsilon = 1e-8
- Combination of
RMSprop and
Gradient Descent
with momentum
- Learning
Decay
- A method to lowe the learning rate
closer it gets to minimum.
- Many formulas exist,the most famous
is: alpha =
1/(1+decay_rate*epoch_num)
- A method to lowe the learning rate
closer it gets to minimum.
- Tuning algorithm's
hyperparameters
- priorities:
darkest - most
important,
lightest - least.
white is fixed.
- try random values: dont't use grid
- Coarse to fine choice
- randomness scale choice, e.g.
for alpha - logarithmic scale
- priorities:
darkest - most
important,
lightest - least.
white is fixed.
- Batch Normalization
- Idea of
normalizing
each layer
input (Z, not A)
of Neural
Network
- Idea of
normalizing
each layer
input (Z, not A)
of Neural
Network
- Mini-Batch
gradient
descent
- Data not
normalized ->
slower training
process
- High Bias
- Weights/parameters
initialization
- Zeros? NO!
Annotations:
- Zeros will make all neurons of neural network act the same, and behave linear, which loose the sense of having neural network.
- Bad - Fails to
break
Symmetry ->
gradient not
decreasing
- Random Init
Annotations:
- - Initializing weights to very large random values does not work well. - intializing with small random values does better.
- Good - Breaks Symmetry
- Bad - large weight ->
exploding gradients
- He Init - the best!
Annotations:
- sqrt(2./layers_dims[l-1])
- Good - Ensures faster learning speed
- works well with ReLU activations
- Zeros? NO!
- Dataset Split
- Data > 1M
98% Train,
1% Dev, 1%
Test
- Small Data, 60%
Train, 20% Dev,
20% Test
- Train set from
different
distribution than
Dev/test sets
- Data > 1M
98% Train,
1% Dev, 1%
Test
Media attachments
{kind=link}
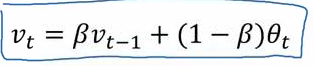{kind=link}
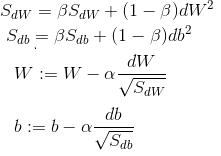{kind=link}
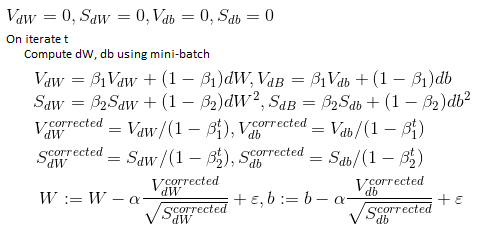{kind=link}
{kind=link}
Want to create your own Mind Maps for free with GoConqr? Learn more.