2458365
| Questão | Responda |
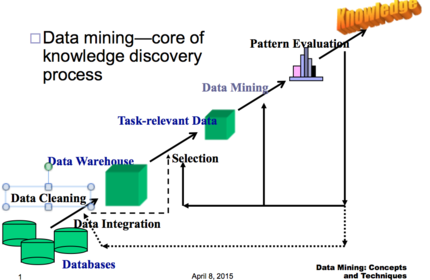
| Data Mining is.. | Data mining—core of knowledge discovery process |
| Data Mining Process | |
| Typical Data Mining System | |
| What is OLTP? What does it do? | On-line Transaction Processing Operational DBMS Major task of traditional relational DBMS Day-to-day operations: purchasing, inventory, banking, manufacturing, payroll, registration, accounting, etc |
| What is OLAP and what does it do? | On-Line Analytical Processing Data Warehouse Major task of data warehouse system Data analysis and decision making |
| Distinct Features of OLTP vs. OLAP User and System Orientation | Customer vs. Market |
| Distinct Features of OLTP vs. OLAP Data Contents | Current, detailed vs. historical, consolidated |
| Distinct Features of OLTP vs. OLAP Database design | ER + application vs. star + subject |
| Distinct Features of OLTP vs. OLAP View | Current, local vs. evolutionary, integrated |
| Distinct Features of OLTP vs. OLAP Access Patterns | Updated vs. read-only but complex queries |
| OLTP breakdown | USER: clerk, IT professional FUNCTION: day to day operations DB DESIGN: application-oriented DATA: current, up-to-date, detailed, flat relational isolated USAGE: reptitive ACCESS: read/write index/hash on prim key UNIT OF WORK: short, simple transaction # RECORDS ACCESS: tens # USERS: thousands DB SIZE: 100MB-GB METRIC: transaction throughput |
| OLAP breakdown | USERS: knowledge worker FUNCTION: decision support DB DESIGN: subject-oriented DATA: historical, summarized, multidemensional, integrated, consolidated USAGE: ad-hoc ACCESS; lots of scans UNIT OF WORK: Complex queries # RECORDS ACCESSED: millions # USERS: hundreds DB SIZE: 10GB-TB METRIC: query throughput, réponse |
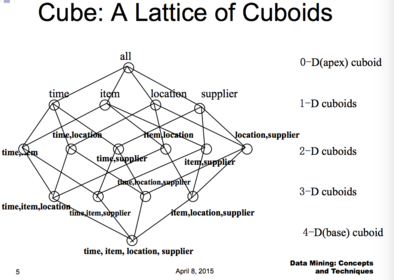
| CUBE: A Lattice of Cuboids | |
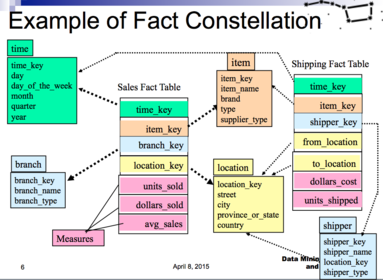
| Example of Fact Constellation | |
| Generating Association Rules for Frequent Itemsets | Once the frequent itemsets have been found, generation strong association rules from them is straight forward An association rule A -> B is STRONG if it satisfies both min support and min confidence |
| Generating Association Rules from Frequent Itemsets METHODS | 1. For each frequent items I, generation all non-empty subsets of I 2. For every non-empty subset s of I, output rules s-> (i-s) if con(s->(i-s)) >/= min_conf |
| LIFT is | Measuring of dependent/correlated events |
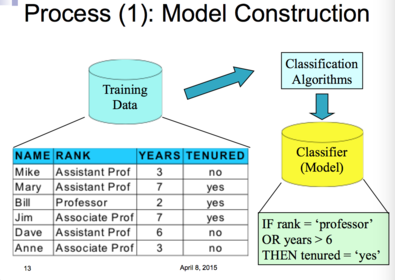
| Process 1: Model Construction | |
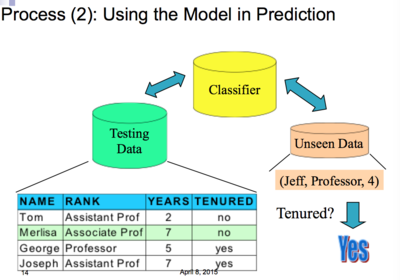
| Process (2) Using the Model in Prediction | |
| Attribute Selection Measure: Information Gain (ID3) | |
| Attribute Selection: Info Gain |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
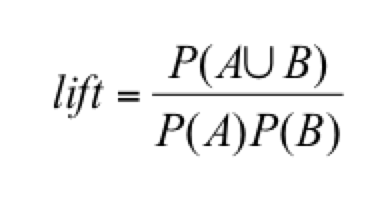{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Quer criar seus próprios Flashcards gratuitos com GoConqr? Saiba mais.