841175
Descrição
FlashCards por schmidt.nath, atualizado more than 1 year ago
|
|
Criado por schmidt.nath
quase 12 anos atrás
|
|
| Questão | Responda |
| Wissenschaftstheorie | Beschäftigt sich mit der Frage, was die Wirklichkeit eigentlich ist und wie wir sie erfassen können |
| Anspruch der Psychologie als Wissenschaft | Erklären, Vorhersagen und Verändern vom Erleben und Verhalten des Menschen --> Suchen nach Mechanismen und Gesetzmäßigkeiten |
| Abgrenzung Psychologie und Alltagspsychologie | Subjektive Überzeugungen und einzelne, sehr selektive Erfahrungen VERSUS dem Einsatz von Forschungsmethoden (wissenschaftliches Vorgehen) |
| Wissenschaftliches Vorgehen | 1) systematische Beobachtung unter kontrollierten Bedingungen 2) Organisation von Wissen in Hypothesen, Theorien, Gesetzen 3) Systematisierung und Formalisierung der Theorien zur Gewährleistung der Kommunikation und Überprüfbarkeit der Erkenntisse 4) Folgt dem Prozess der Erkenntnissgewinnung |
| Prozess der Erkenntnissgewinnung | Wundern, raten, fragen . Theorie . Forschungshypothese . Operationalisierung . Durchführung der Studie und Messung . Daten . Auswertung . Interpretation . Implikation für Theorie . Beantwortung der Fragen |
| Theorie | Sammlung von Ideen, Annahmen und Hypothesen über einen Sachverhalt Schlägt vorläufige Antwort auf gestellte Fragen dar Aufgrund des Umfangs (Komplexität) als Ganzes kaum prüfbar |
| Hypothesen | Vorläufige Antworten auf Forschungsfragen in Form konkreter Aussagen (Prüfbarkeit) Durch Operationalisierung messbar |
| Operationalisierung | Methodisches Definieren von Begriffen und psychologischen Größen |
| Deterministische Hypothesen | Aussagen, die universalen kausalen Zusammenhang beschreiben Gesetzcharakter Für Menschen kaum anwendbar |
| Prohabilistische Hypothesen | Aussagen, die mit einer gewissen Wahrscheinlichkeit zutreffen Modellcharakter |
| Messen | Zuordnung von Zahlen zu Objekten, Phänomenen, Ereignissen Beziehung zw. den Zahlen repräsentiert die analogen Beziehungen der Objekte etc. |
| Empirisches versus numerisches Relativ | "Wahre" Verhältnisse der Welt versus Zuordnung von Zahlenwerten (Repräsentativitätsproblem) |
| Ausprägungen von Variablen | Dichotom Kategorial Kontinuierlich |
| Unabhängige Variablen | werden fokussiert und systematisch variiert |
| Abhängige Variablen | Mit ihr wird Effekt gemessen, der auf die UV zurückzuführen ist |
| Nominalskala | dichotome und kategoriale Variablen Gleichheit versus Ungleichheit nur qualitative Aussagen |
| Ordinalskala | größer/kleiner Relation, relative Unterschiede quantitative Aussagen möglich |
| Intervallskala | Abstände zwischen Variablenausprägungen, absolute Unterschiede quantitative Aussagen möglich |
| Verhältnisskala | relative Lage der Variablenausprägung zum natürlichen Nullpunkt, Gleichkeit/Ungleichheit von Verhältnissen quantitative Aussagen |
| Grafische Ratingskala | :) - :/ - :( |
| Numerische Ratingskala | 1-2-3-4-5-6 |
| Verbale Ratingskala | sehr gut - gut - ging so - schlecht |
| Ratingskala als semantisches Differential | sehr gut ______ schlecht |
| Bipolare Ratingskala | -3,-2,-1,0,1,2,3 |
| Urteilsfehler bei Ratingskalen | Halo Effekt Zentrale Tendenz / Tendenz zur Mitte Ankereffekte |
| Halo Effekt | Urteilsfehler bei Ratingskalen Überstrahlen einzelner Fragen, Wörter etc. auf Wahrnehmung anderer Fragen etc. |
| Zentrale Tendenz | Tendenz, Extremwerte zu vermeiden je extremer die Pole, desto stärker Tendenz zur Mitte |
| Ankereffekte | Aussehen oder Beschriftung von Skalen wird als Anker wird Interpretation genutzt |
| Items | Einzelne Fragen oder Aufgaben eines Tests, die "gelöst" werden müssen |
| Gütekriterien von Tests | Objektivität Reliabilität Validität |
| Objektivität (Tests) | Durchführung, Auswertung und Interpretation von Person des Testleiters unabhängig |
| Sicherstellung von Objektivität in Testverfahren | Standardisierung (Handbuch, Anleitung zum Test) (Codierung von Verhalten) (Schulung von Testleitern und Beobachtern) |
| Reliabilität (Test) | Genauigkeit/Zuverlässigkeit einer Messung Gleiche Ergebnisse zu unterschiedlichen Zeitpunkten (Retest-Rel.), in verschiedenen Varianten (Split-Half-Rel.) und mit unterschiedl. Anwendern (Inter-Rater-Rel.) |
| Validität (Test) | Gültigkeit einer Messung: Messung des Merkmals, das gemessen werden soll Augenscheinvalidität Kriteriumsvalidität Konstruktvalidität |
| Augenscheinvailidität (Test) | Test hat augenscheinlich etwas damit zu tun, was er messen soll |
| Kriteriumsvalidität (Test) | Test steht mit praktisch oder theoretisch relevanten Kriterium im Verbindung Übereinstimmungsvalidität Vorhersagevalidität |
| Konstruktvalidität (Test) | Verbindung des Tests mit mehreren Kriterien, die wiederum untereinander in Beziehung stehen (theoretische Einbettung) |
| Testverfälschung trotz Erfüllung Gütekriterien | Mangelndes Wissen / Ratewahrscheinlichkeit Faking good/bad Selbstdarstellung/soziale Erwünschtheit Ja-sage-Tendenz |
| Kontrolle von Tendenzen der Testverfälschung | Einbau von Kontrollfragen Sensibilisierung der TN für Fragestellung / Zielsetzung Absolute Sicherheit gegen Verzerrungen nicht gegeben |
| A verursacht B kausal, wenn... | A zeitlich vor B auftritt A und B kovariieren (eine Veränderung von A mit einer Veränderung von B einhergeht) der Einfluss von Drittvariablen ausgeschlossen werden kann |
| Störvariablen | Merkmale einer Person oder Situation, die die AV ebenfalls beeinflussen (Experiment) Ihr Effekt soll ausgeschaltet werden, da er den Effekt der UV stören kann |
| Experimentelle Kontrolle von Störvariablen | Konstanthalten und Parallelisieren Randomisierung |
| Konstanthalten und Parallelisieren | Kontrolle von Störvariablen im Experiment Merkmale der Drittvariable gleichmäßig auf Versuchsgruppen verteilen Problem bei zu vielen Störvariablen (Aufwand und Bekanntheit) |
| Randomisieren | Kontrolle von Störvariablen im Experiment Versuchspersonen werden zufällig den Versuchsbedingungen zugeordnet --> alle Störvariablen werden so erfasst |
| Quasiexperimente | Gruppeneinteilung von "Natur" aus vorgegeben (Raucher-Nicht-Raucher, Geschlecht) Randomisierung nicht möglich Auf Konstanthalten/Parallelisieren angewiesen |
| Experimentelle Designs | Faktoren (Anzahl UV) Uni-/multivariat (Anzahl AV) Labor vs. Feld Echt vs. Quasi Messwiederholung vs. einmalig Within- vs. between-the-subjects |
| Between-the-subjects-design | Experimentdesign in den verschiedenen Ausprägungen der UV befinden sich unterschiedliche Personen |
| Within-the-subjects-design | Experimentdesign jede Person nimmt an allen Ausprägungen der UV teil |
| Vorteile Within-subjects-design | Anzahl erforderl. Versuchspersonen Automatische Gleichverteilung personenbezogener Störvariablen (perfekte Parallelisierung) manche Fragestellungen nur so untersuchbar (z.B. subjektive Urteile) |
| Nachteile Within-subjects-design | Positionseffekte (Übungs- und Lerneffekte, Ermüdungseffekt) Carry-Over-Effekte (Manipulation hat anhaltenden Effekt auf spätere Versuchsbedingung) |
| Einsatz von Kontrollgruppen | Experimente mit Treatment randomisierte KG schließen Störvariablen und Positionseffekte aus |
| Probleme beim Experimentieren | Störvariablen (Randomisieren, Parallelisieren) Störeffekte (exp. Design, Kontrollgruppen) Faktor "Mensch" (Versuchspersonenerwartungen - Blindversuche, Versuchsleitereffekte - Doppelblindversuche, Hawthorne-Effekt - Kontrollgruppe) |
| Gütekriterien bei Experimenten | Gütekriterien Test (Tests sind in Experimenten enthalten) + Interne Validität (Veränderung der AV geht eindeutig auf Veränderung der UV zurück --> Ausschluss von Störvariablen und Störeffekten) + externe Validität/ Repräsentativität (Ergebnisse aus einer Stichprobe lassen sich auf Population übertragen --> Stichprobe zufällig ziehen / jede Person der Population hat die gleiche Chance in Stichprobe zu gelangen) |
| Validität Feld- vs. Laborexperiment | Feld im Vergleich Labor: geringe Kontrollierbarkeit --> geringe interne Validität Situation realistischer und repräsentativer --> höhere externe Validität |
| Deskriptive Statistik | Beschreiben und Darstellen empirischer Daten durch Kennwerte, Grafiken, Tabellen |
| Explorative Statistik | Erkennen und Beschreiben von eventuellen Mustern in empirischen Daten |
| Inferenzstatistik | Prüfen empirischer Daten dahingehend, ob sie auf die Population generalisierbar sind |
| Zulässige Lagemaße für Skalenniveaus | nominal: Modalwert ordinal: Modalwert, Median (Mittelwert - Berechnung "mittlerer Ränge" vermeiden) metrisch: Modalwert, Median, Mittelwert |
| Zusammenhang Streuung und Lagemaße | Verteilungen immer durch Lage UND Streuungsmaß charakterisiert Ohne Streuung, kann man dem Mittelwert nicht "trauen" Je kleiner die Streuung, desto besser/repräsentativer der Mittelwert für die Verteilung |
| Bewertung Streuungsmaße | Spannweite/Range: kann nicht gut zwischen Verteilungen differenzieren, anfällig für Ausreißer Interquartilsabstand: Äußere Ränder der Verteilung unberücksichtigt, robuster gegenüber Ausreißern und bessere Differenzierung Varianz/Standardabweichung: exakte Streuung, da Bezug auf konkrete Mittelwerte und Einbeziehung aller Werte |
| Varianzaufklärung | Ziel der Statistik Frage, wie groß die Varianz ist, die auf UV zurückzuführen ist Gesamtvarianz - Fehlervarianz = systematische Varianz (Gesamtvarianz möglichst groß, Fehlervarianz möglichst klein) |
| Gesetz der großen Zahl | Je größer die Stichprobe, desto stärker nähert sich die Verteilung der empirischen erhaltenen Daten an die wahre Verteilung der Population an (ab 30 Personen zuverlässige Werte) |
| Schiefe / asymmetrische Verteilungen | Streuung der Werte in eine Richtung eingeschränkt Werte auf der linken Seite höher: rechts-schiefe bzw. links-steile Verteilung Werte auf der rechten Seite höher: links-schieße bzw. rechts-steile Verteilung |
| z-Transformation | macht Messwerte von verschiedenen Skalen bzw. aus verschiedenen Stichproben vergleichbar, indem sie jedem Messwert einen standardisierten z-Wert aus der Standardnormalverteilung zuordnet, der eindeutig interpretierbar ist |
| Grafische Datenanalyse | Boxplot Stamm-und-Blatt-Diagramm Streudiagramm Sonnenblumendiagramm Bubble-Plot Streudiagrammmatrix |
| Boxplot | grafische Darstellung, die Median und Interquartilsabstand abträgt udn Rohdaten unverzerrt abbildet Grauer Kasten: Interquartilsabstand Strich: Median Stern, inkl. Fallnummer: Ausreißer Whiskers: 1,5-fache des Interquartilsabstandes in Richtung der Box |
| Korrelation | Ausmaß des linearern Zusammenhangs zweier Variablen Korrelationskoeffizient r durch Stadardisierung der Kovarianz Anstieg der geraden für Größe der Korrelation nicht entscheidend, hängt von Skalierung ab |
| Messfehler bei Korrelationen | Fehleranfällige Instrumente Faktor "Mensch" AV korreliert noch mit weiteren Variablen |
| Interpretation des Korrelationskoeffizienten r | ab .1 oder -.1: "kleiner" Effekt ab .3 oder -.3: "mittlerer" Effekt ab .5 oder -.5: "starker" Effekt |
| Voraussetzung für die Berechnung von Korrelationen | Beide Variablen müssen mind. intervallskaliert sein (Ausnahme: 1ne Variable ist nominalskaliert und hat genau zwei Ausprägungen -ein Intervall- z.B. Geschlecht; angewendet in Experimenten EG vs. KG) Es besteht ein linearer Zusammenhang (vorher im Streudiagramm zu testen) |
| Korrelation und Kausalität | Korrelationen lassen keine Schlüsse über Kausalzusammenhänge zu (unterschiedliche kausale Erklärungen möglich) r gibt nur Stärke des Zusammenhangs an Ob Kausalität vorliegt, muss theoretisch entschieden werden --> Einsatz von Experimenten |
| Regression | Vorhersageanalyse macht sich Korrelation von Variablen zunutze, um Werte von y aus x zu schätzen vorhersagende Variable x: Prädikator vorhergesagte Variable y: Kriterium |
| Prädikator | Vorhersagende Variable x in der Regression |
| Kriterium | Vorhergesagte Variable y in der Regression |
| Regressionsgerade | Gerade, um die sich die Punkte der Punktewolke konzentrieren Gerade muss Punktewolke bestmöglich repräsentieren Alle Punkte weichen im Schnitt möglichst wenig von der Geraden ab |
| Vorhersagefehler in der Regression | Differenz "echter" Punkt und vorhergesagter Punkt y auf der Regressionsgeraden Abweichung durch Regression von y auf x nicht erklärbar --> Residualwert / Residuum |
| Anwendungsfelder der Regression | Vorhersage / Schätzung von Werten für eine Population auf Basis einer Stichprobe (praktische Anwendung) Ermittlung des Maßes für die Varianzaufklärung / Frage, wie gut die Vorhersage gelingen kann --> Determinationskoeffizient r2 |
| Determinationskoeffizient r2 | Anwendung der Regression Ausmaß/Anteil der Varianzaufklärung einer Variable y (Kriterium) durch eine Variable x (Prädikator) Kann maximal 1 betragen (100% Varianzaufklärung), dann Schätzfehler = 0 |
| Regressionsgewicht b | bei bivariaten Korrelationen = r (Stärke des Zusammenhangs) |
| Beta-Gewicht | standardisiertes Regressionsgewicht bei bivariaten Korrelationen = b = r |
| Güte der Vorhersage von y aus x | Varianzaufklärung r2 (Determinationskoeffizient) |
| Wann ist Verallgemeinerung/Generalisierung auf Population möglich? | Wenn die Stichprobe repräsentativ für die Population ist --> Zufallsstichprobe --> Gesetz der großen Zahl |
| Prinzip des zentralen Grenzwertsatzes | die Verteilung einer großen Anzahl von Stichprobenergebnissen folgt immer einer Normalverteilung |
| Indikatoren für die Güte der Verallgemeinerung | Standardfehler Konfidenzintervall Signifikanztest |
| Standardfehler des Mittelwertes | gibt den durchschnittlichen Unterschied zwischen den aus einer einzelnen Stichprobe geschätzten Mittelwert und dem tatsächlichen Mittwert an entspricht der Standardabweichung der entsprechenden Stichprobenverteilung Standardfehler ist immer kleiner als die Standardabweichung einer Stichprobe Maß zur Güte der Schätzung von Stichprobenergebissen auf die Population |
| Konfidenzintervall | Wahrscheinlichkeit für die Güte einer Schätzung (Korrektheit des Intervalls, nicht Lage gezogener Werte) Wertebereich, bei dem wir darauf vertrauen können, dass er den wahren Wert der Population mit einer gewissen Wahrscheinlichkeit überdeckt |
| Zusammenhang t-Verteilung und Standardnormalverteilung | bei großen Stichproben geht t-Verteilung in Standardnormalverteilung über |
| Höhe der Konfidenz / Vertrauenswahrscheinlichkeit | Festlegung immer Kompromiss zwischen Wahrscheinlichkeit und Informationsgehalt Je größer die Wahrscheinlichkeit, desto breiter wird das Intervall, desto uninformativer wird die Aussage Kompromiss über Stichprobengröße abmilderbar: je größer sie Stichprobe, desto schmaler wird das Intervall (Grenzen ändern sich), wobei sich die Wahrscheinlichkeit gleich bleibt |
| Unabhängige Messung | Versuchsteilnehmer sind den verschiedenen Messungen bzw. Stichproben rein zufällig zugeordnet (between-subjects-design) |
| Abhängige Messungen | Messwiederholungen (within-subjects-design) Gepaarte Stichproben (matching) --> bei Zusammenhangshypothesen immer abhängige Messungen: es werden zwei Merkmale an denselben Personen untersucht |
| Einsatz Standardfehler, Konfidenzintervall, Signifikanztest | Bei Mittelwerten: Standardfehler Bei Hypothesen (Unterschiede und Zusammenhänge): Konfidenzintervall und Signifikanztest --> es geht darum, Entscheidungen zu treffen - Standardfehler dazu nicht praktisch interpretierbar |
| Schema Signifikanztest | Entscheidungshilfe bei Hypothesen Ausgehend von der Nullhypothese, die keinen Effekt für die Population unterstellt, haben wir einen empirisch gefunden Wert dahingehend untersucht, ob er unter Annahme von H0 so unwahrscheinlich war, dass wir diese verwerfen können Ergebnis ist signifikant, wenn p < Alpha |
| p-Wert | Signifikanztest Wert, ab dem man nicht mehr bereit ist, die Nullhypothese zu akzeptieren |
| Einsatz z-Verteilung | Prüfverteilung, um innerhalb einer Stichprobe für einen einzigen Wert zu bestimmen, ob sich dieser signifikant vom Durchschnitt unterscheidet 1) z-Standardisierung eines Punktes 2) Fläche, die abgeschnitten wird, in Verteilung suchen 3) p: 100% minus gefundene Fläche 4) wenn p < Alpha, H0 ablehnen --> signifikanter Unterschied |
| Einsatz t-Verteilung | Mittelwertsunterschiede, Korrelationskoeffizienten, Regressionsgewichte |
| Einsatz F-Verteilung | Varianzen |
| Einsatz Chi-Quadrat-Verteilung | Häufigkeiten |
| Einseitige Tests | Gehen davon aus, dass Effekt auf der rechten Seite von H0 zu finden ist (gerichtete Hypothese) F-Test und Chi-Quadrat-Test immer einseitig (können nicht negativ sein) |
| Zweiseitige Tests | Unklarheit, ob es einen Effekt gibt und/oder in welche Richtung er geht Alpha-Fehler wird auf beide Seiten aufgeteilt Effekt hat es schwerer, signifikant zu werden (muss weiter von 0 entfernt sein) |
| Fehler erster Art | H0 wird fälschlicherweise verworfen Sollte minimiert werden, wenn große Effekte relevant sind |
| Fehler zweiter Art | Beta-Fehler: H1 wird fälschlicherweise verworfen zu minimieren, wenn schon ein kleiner Effekt interessant ist (Krebsmedikament) |
| Abwägung Alpha- und Beta-Fehler | Sollten vorher abgewägt werden, um begründete Entscheidung für oder gegen eine Hypothese treffen zu können Orientierung an inhaltl. Gesichtpunkten (Interesse an großem oder kleinen Effekt?) Vor allem relevant, wenn sich die H1 und H0 stark überschneiden, also der erhoffte Effekt in der Population --> kleiner Effekt führt zu großem Überschneidungsbereich, Fehler werden größer -->kleine Stichproben führen zu großen Streuungen und breiten Verteilungen (großen Überlappungen), Fehler werden größer |
| Signifikanz und Wahrscheinlichkeit | Signifkanztest lässt keine Aussagen über Wahrscheinlichkeit von Hypothesen zu Sondern: Warscheinlichkeit des gefundenen Effektes, gegeben der Tatsache, dass eine Hypothese zutrifft |
| Einflussgrößen auf Ergebnis des Signifikanztests | Größe des Populationseffektes (je größer der Effekt, desto kleinere p-Werte --> eher signifkant) Stichprobengröße (je größer die Stichprobe, desto schmaler Verteilung --> eher signifkantes Ergebnis) Alpha-Niveau (Abwägung, je höher, desto eher signifikant) |
| Kritische Betrachtung Signifikanztest | Umgang mit Bedeutung/Interpretation (Signifikanz nicht gleich großer oder interessanter Effekt) Ritualisierter Umgang (Auch Einsatz von Konfidenzintervallen und ergänzende Angabe von Effektgrößen) H0 als Forschungshypothese (Missbrauch des Tests - z.B. Tabakindustrie) --> Abhängigkeit Teststärke |
| Effektgrößen | Standardisierte Effekte Über Stichproben, Themenbereiche und Studien hinweg vergleichbar |
| Vergleich Abstandsmaße g und d | Effektgrößen g stets etwas kleiner als d, liefert aber exaktere Schätzung d trotzdessen weitaus gebräuchlichere Variante |
| Korrelation als Effektgröße | Korrelation als Effektgröße für Zusammenhänge, da Kovarianz bereits durch gemeinsame Streuung standardisiert |
| Interpretation von Effektgrößen (d und g) | Der Größe nach prinzipiell nach oben offen, man findet aber i.d.R. keine Werte, die über +/- 1 hinausgehen ab 0,2 bzw. -0,2: kleiner Effekt ab 0,5 bzw. -0,5: mittlerer Effekt ab 0,8 bzw. -0,8: starker Effekt |
| Multiple Regression | Kriteriumsvariable wird mithilfe mehrerer Prädikatoren vorhergesagt / erklärt Ziel liegt in der größtmöglichen Varianzaufklärung Je mehr Prädikatoren, desto besser die Vorhersage (Achtung: Handhabbarkeit) Regressionskoeffizient b als relativer (bereinigter) Einfluss eines Prädikators bei der Vorhersage |
| Güte der Vorhersage bei multipler Regression / Güte des Regressionsmodells | Mutipler Determinationskoeffizient R2 --> wie gut können alle Prädikatoren zusammen das Kriterium vorhersagen R2=1 entspricht 100% Varianzaufklärung (Beta-Gewichte bzw. r nicht mehr nutzbar, da keine lineare Regression --> hier nur als relativer Einfluss interpretierbar) |
| Voraussetzungen beim t-Test | Für unabhängige Stichproben: Stichproben sind tatsächlich unabhängig, Personen in den Gruppen können sich nicht gegenseitig beeinflussen) AV immer intervallskaliert AV in der Population normalverteilt Varianzen beider Verteilungen möglichst gleich ((t-Test aber robustes Verfahren, unempfindlich gegen leichte Verletzung der Voraussetzungen)) |
| t-Test | Unterschiede zwischen zwei Gruppen (parametrisch) |
| Varianzanalyse | Unterschiede zwischen mehr als zwei Gruppen (parametrisch) UV darf nominalskaliert sein: perfekt geeignet für Experimente (Gruppenzugehörigkeit) Versucht herauszufinden, welches die wichtigste Quelle für das Zustandekommen von Varianz ist |
| F-Test versus t-Test | Untersuchen gleiche Fragestellung: Unterscheiden sich Gruppenmittelwerte signifikant voneinander? Unterschiede hinsichtlich Anzahl zu vergleichender Gruppen (t-Test = 2 Gruppen) Liefern gleiche Egebnisse, t-Test ist aber einfacher zu rechnen F-Test kann im Gegensatz zum t-Test nicht negativ werden (testet einseitig) und somit Richtung des Unterschieds indetifizieren |
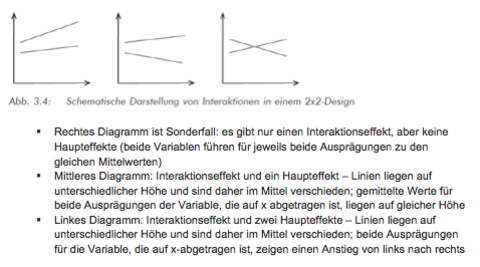
| Mehrfaktorielle Varianzanalyse | Untersuchung mehrere UVs Berechnung Haupteffekten (Prüfung, ob die einzelnen UVs einen signifikanten Unterschied auf AV ausüben) Berechnung Interaktionseffekte (Prüfung, ob sich UVs gegenseitig in ihrer Wirkung beeinflussen) --> Vorteil der mehrfaktoriellen ANOVA |
| Identifikation Haupt- und Interaktionseffekte | |
| Voraussetzungen Varianzanalyse | Entsprechen Voraussetzungen für t-Test |
| Einsatz nonparametrische Verfahren | AV ist nominal- oder ordinalskaliert intervallskalierte Messwerte sind schief verteilt |
| Vor- und Nachteile nonparametrischer Verfahren | + keine Annahmen über Verteilung der Parameter sehr kleine Stichproben untersuchbar - Verfahren werden schwerer signifikant (geringere Teststärke) |
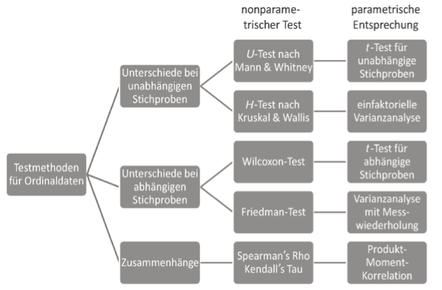
| Testverfahren zur Analyse ordinalskalierter Daten | |
| Rangkorrelation | nonparametrisches Verfahren bei ordinalskalierten Daten und Analyse von Zusammenhängen Bedingung: Beziehung beider Variablen steigt monoton Spearman's Rho: Ränge werden so behandelt, als wären Abstände gleich groß Kendall's Tau: Rangabstände spielen keine Rolle |
| Effektgrößen für Ordinaldaten | Für Unterschiedsfragestellungen nicht bestimmbar (da Mittelwert nicht sinnvoll bestimmbar) Für Zusammenhänge: Rangkorrelation, interpretiert wie r |
| Nullhypothese bei Chi-Quadrat-Test | Erwartete Häufigkeiten stellen Nullhypothese dar (bei Anpassungstest H0=Gleichverteilung) |
| Effektgrößen für Nominaldaten | Für Unterschiedsfragestellungen nicht bestimmbar (Mittelwert nicht sinnvoll) Für Zusammenhänge: Omega, interpretiert wie r |
| Ursachen für nicht-signifikantes Ergebnis | a) es gibt keinen Effekt in der Population b) es gibt einen Effekt, aber wir haben ihn mit dem Test nicht gefunden (Abhängigkeit Beta-Fehler --> Teststärke) |
| Teststärke (Power) | Wahrscheinlichkeit, mit der ein in der Population tatsächlich vorhandener Effekt mithilfe eines Testverfahrens identifiziert werden kann Teststärke = 1 - Beta |
| Wovon ist die Teststärke abhängig? | Vom Beta-Fehler (muss möglichst klein sein) 1) wird mit größerem Alpha-Fehler kleiner 2) wird mit großen Stichproben kleiner (schmalere Verteilung) 3) wird bei großen Effekten kleiner (weit auseinanderliegende Verteilung) |
| Anwendung der Teststärke | Vor der Studie: dient der Bestimmung der erforderlichen Stichprobengröße bei bestimmten Alpha-Fehler Nach einer Studie: Beurteilung, wie wahrscheinlich es war, einen Effekt zu finden - Hypothesen bei geringen Teststärken müssen ggf. nicht gleich verworfen werden (WDH mit größerer Stichprobe) --> wichtig, wenn Forschungshypothse = H0 |
| Kontrastanalyse | Komplexes Analyseverfahren für spezifische Hypothesen (spezielle Form der Varianzanalyse) Hypothetische Muster der Mittelwertsunterschiede in Gruppen durch Kontrastgewichte (Lambdagewichte) festgelegt und mit erhobenen Daten verglichen Summe der Kontrastgewichte muss 0 ergeben Signifikantes Ergebnis, wenn Muster übereinstimmen |
| Vorteile Kontrastanalyse gegenüber normaler Varianzanalyse | höhere Teststärke gute Interpretierbarkeit |
| Multivariate Analyseverfahren | Untersuchen mehr als eine AV, mehrere UVs möglich Faktoranalyse Clusteranalyse Multivariate Varianzanalyse (MANOVA) Mutidimensionale Skalierung Conjoint-Analyse Strukturgleichungsmodelle |
| Faktorenanalyse | Multivariates Analyseverfahren Reduziert eine Vielzahl von Variablen aufgrund ihrer Korrelation zu wenigen Faktoren, die dann stellvertretend für Ausgangsvariablen stehen (messen denselben Sachverhalt) |
| Clusteranalyse | Multivariates Analyseverfahren Reduktion von Fällen (Personen, Objekten) durch Zusammenfassung in Gruppen anhand deren Merkmalsausprägungen der gemessenen Variablen |
| Multivariate Varianzanalyse (MANOVA) | Multivariates Analyseverfahren Effekt einer oder mehrerer UVs auf mehrere AVs |
| Multidimensionale Skalierung (MDS) | Multivariates Analyseverfahren nutzt Ähnlichkeitsbeurteilung, die Personen für Objekte vornehmen, um abzuleiten, wieviele und welche Bewertungsdimensionen der Beurteilung zugrunde leigen |
| Conjoint-Analyse (Verbundanalyse) | Multivariates Analyseverfahren Prüft den relativen Einfluss verschiedener Merkmale und Merkmalsausprägungen auf die Bewertung von Objekten durch eine oder mehrere Personen |
| Strukturgleichungsmodelle | Multivariates Analyseverfahren Kombination aus Faktorenanalyse und Regressionsrechnung Annahme, dass sich eine latente Variable durch eine Reihe messbarer Variablen stellvertretend darstellen lässt Ergebniss ist Strukturmodell, in dem interessierente latente Variablen und die Stärke ihrer (kausalen) Beziehungen abgetragen sind |
| Anwendungsfelder qualitativer Forschungsmethoden | Gegenstandsbereiche, die sich quantatitativen Methoden entziehen (subjektives Erleben und phänomenale Eindrücke) Vorbereitung quantitativer Forschung, wenn Themengebiet noch nicht erschlossen --> relevante Fragen müssen erst gefunden werden bevor sie weiter untersucht werden können |
| Qualitative Methoden | Qualitative Inhaltsanalyse Grounded Theory Diskursanalyse |
| Vor- und Nachteile qualitativer Methoden | + Unvoreingenommenheit Keine wichtigen Aspekte übersehen Einbeziehung des Kontextes Gewinnen zusätzlich relevanter Informationen - Ungenauerer Umgang mit Daten Einfluss der Subjektivität auf Interpretation Fehlende konkrete Handlungsanweisungen großer Aufwand Grütekriterien schwer sicherzustellen Kompromiss: z.B. teilstrukturiertes Interview |
{kind=link}
{kind=link}
Quer criar seus próprios Flashcards gratuitos com GoConqr? Saiba mais.