13715787
Description
Quiz by Good Guy Beket, updated more than 1 year ago
|
|
Created by Good Guy Beket
almost 7 years ago
|
|
Question 1
Question
Consider the following code. Assume the compiler is performing no optimization. Which of the following strategies would improve the speed of this code the most in the case where it returns true?
{kind=link}
Answer
-
Unroll the loop
-
Pull the (x % i)==0 into a function isDivisibleBy
-
Declare int sx = (int)sqrt(x) and change i < sqrt(x) to i < s
-
Move the check for (x % 2) != 0 to before the loop
Question 2
Question
By default, OpenMp _____ assigns loop iterations to threads. When the parallel for block is entered, it assigns each thread the set of loop iterations it is to execute?
Answer
-
static
-
runtime
-
dynamic
-
auto
Question 3
Question
OpenMP assigns one iteration to each thread. When the thread finishes, it will be assigned the next iteration that hasn’t been executed yet.
Answer
-
runtime
-
dynamic
-
static
-
auto
Question 4
Question
This is an example of? (IMAGE)
/*set elements of array to 0*/
void clear_array (int *desc, int n){
int i;
for (i = 0; i<n; i++)
dest[i] = 0;
}
/*set elements of array to 0, Unrolled X4*/
...
...
{kind=link}
Answer
-
Loop Unrolling
-
Loop fission
-
none
-
Loop fusion
Question 5
Question
This is an example of? (IMAGE)
/*convert string to lowercase: slow*/
void lower1 (char *s)
{ int i;
for (i = 0; i < strlen(s); i++)
if (s{i} >= 'A' && s[i] <= 'Z')
s[i] -= ('A' - 'a');
}
/*Convert string to lowercase: faster*/
void lower2(char *s) {
...
...
}
{kind=link}
Answer
-
Loop fission
-
Code motion
-
Loop unrolling
-
Loop blocking
Question 6
Question
In given two C modules which rule will Unix linker use to resolve multiple symbol definition?
Image:
Pizdec (binary/octet-stream)
{kind=link}
Answer
-
Given a strong symbol and multiple weak symbols, choose the strong symbol.
-
Given multiple weak symbols, chose any of the weak symbols
-
Multiple strong symbols are not allowed.
-
None of these
Question 7
Question
In C, on a 34-bit x86 machine, the expression (1<<31) results in a negative integer
Answer
-
True
-
False
Question 8
Question
Which of the following move operations is the following instruction an example of: movl (%edx), %eax ?
Answer
-
memory to immediate
-
register to memory
-
memory to register
-
error, can't move memory to memory
Question 9
Question
What is the value of the following C expression? x = 0xBC and y = 0x35 (x & !y)
Answer
-
0x1200
-
0xFFFF
-
0x0001
-
0x0000
Question 10
Question
In general, which of the following is slowest?
Answer
-
moving from one register to another
-
comparing two numbers to decide where to jump
-
doing division
-
accessing memory
Question 11
Question
Good software design includes writing procedures for code you might otherwise repeat in-line. Pulling code into procedures can help some branch predictors; how else can it improve your program’s performance and/or your compiler’s ability to optimize your code?
Answer
-
more opportunities for loop unrolling
-
less chance of compiler having to worry about aliasing and side effects
-
more opportunities for pipeline-level parallelism
-
better instruction cache hit rate
Question 12
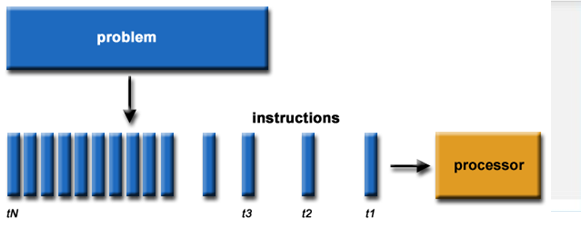{kind=link}
Answer
-
Parrallel processing
-
Serial processing
-
none of the above
-
Linear processing
Question 13
{kind=link}
Answer
-
Parallel processing
-
Serial processing
-
none of the above
-
Linear processing
Question 14
Question
The code ( a && b ) || (!a && !b) implements —
Answer
-
Equality
-
MUX
-
Adder
-
Set membership
Question 15
Question
Consider the following code fragment (IMAGE)
int a; int b;
int main(int argc, char * argv[]){
int x;
int y;
… /* some code*/
}
{kind=link}
Answer
-
The value of &y is closer to the value of &x than to the value &
-
The values of &a and &b are closer to each other then the values &x and &y
-
The values of *a and *b are closer to each other than the values of *x and *y
-
The value of *y is closer to the value of *x than to the value of *a
Question 16
Question
Compare the size of int and int*
Answer
-
each one of the above depends on the computer
-
int has fewer bits
-
int* has fewer bits
-
they have the same number of bits
Question 17
Question
In C, if x is an integer variable, the expression “x << 3” computes x * 8 but does not change the value of x.
Answer
-
true
-
false
Question 18
Question
Using a base address [Eb]%edx=0x1000, and index register [ei]%ecx=0x02, compute the effective address for (IMAGE) :
movl 8(%edx,%ecx, 4), %eax)
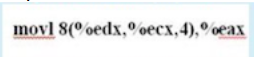{kind=link}
Answer
-
0x1032
-
0x1016
-
0x1064
-
0x1010
Question 19
Question
Using a base address [Eb]%edx=0x1000, and index register [ei]%ecx=0x03, compute the effective address for (IMAGE):
movl 8(%edx, %ecx, 4), %eax
Answer
-
0x1032
-
0x1016
-
0x1064
-
0x1014
Question 20
Question
What value ends up in EAX after the following code is executed?
Image:
Syntax (binary/octet-stream)
{kind=link}
Answer
-
48 (decimal) or 00110000 (binary) or 0x30 (hex)
-
50 (decimal) or 00110010 (binary) or 0x32 (hex)
-
46 (decimal) or 00101110 (binary) or 0x2E (hex)
-
52 (decimal) or 00110100 (binary) or 0x34 (hex)
Question 21
Question
Two computers A and B with a cache in the CPU chip differ only in that A has an L2 cache and B does not. Which of the following are possible?
{kind=link}
Answer
-
1 and 2 only
-
1 only
-
2 only
-
2 and 3 only
Question 22
Question
Which of the following code snippets is fastest ? Assume n is very large(more than ten thousand)
Answer
-
for(k=0; k<n; k+=16) for(l=0; l<n; l+=16) for(j=0;j<16;j+=1) for(i=0;i<16;i+=1) a[i+l][j+k] = b[j+k][i+l];
-
two or more of the above are equivalently the fastest
-
for(j=0;j<n;j+=1) for(i=0;i<n;i+=1) a[i][j] = b[j][i];
-
for(i=0;i<n;i+=1) for(j=0;j<n;j+=1) a[i][j] = b[j][i];
Question 23
Question
Which of the following code snippets is fastest? Assume n is very large (more than ten thousand).
Answer
-
for(i=0;i<n;i+=1) for(j=0;j<n;j+=1) a[i][j] = b[j][i];
-
for(j=0;j<n;j+=1) for(i=0;i<n;i+=1) a[i][j] = b[j][i
-
for(k=0; k<n; k+=16) for(l=0; l<n; l+=16) for(j=0;j<16;j+=1) for(i=0;i<16;i+=1) a[i+l][j+k] = b[i+l][j+k];
-
two or more of the above are equivalently the fastest
Question 24
Question
Good software design includes writing procedures for code you might otherwise repeat in-line. Pulling code into procedures involves call/return overhead; how else can it HURT your program's performance and/or your compiler's ability to optimize your code?
Answer
-
more chance of compiler having to worry about aliasing and side effects
-
fewer opportunities for pipeline-level parallelism
-
worse instruction cache hit rate
-
fewer opportunities for loop unrolling
Question 25
Question
Good software design includes writing procedures for code you might otherwise repeat in-line. Pulling code into procedures can help some branch predictors; how else can it IMPROVE your program’s performance and/or your compiler’s ability to optimize your code?
Answer
-
more opportunities for loop unrollin
-
less chance of compiler having to worry about aliasing and side effects
-
more opportunities for pipeline-level parallelism
-
better instruction cache hit rate
Question 26
Question
Consider a direct-mapped cache with 256 sets and 16 byte blocks. In this cache the address 0x12345 maps to the same set as which of the following addresses?
Answer
-
0x02345
-
0x22244
-
0x12354
-
0x12040
Question 27
Question
Parallel processing mechanisms to achieve parallelism in uniprocessor system are:
Answer
-
All of the above
-
Multiple function units
-
Parallelism and pipelining within CPU
-
Multiprogramming and time sharing
Question 28
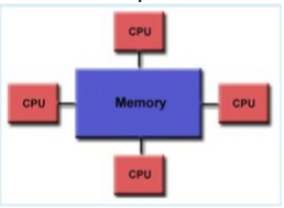{kind=link}
Answer
-
Hybrid system
-
shared memory UMA
-
Distributed memory architecture
-
Shared memory NUMA
Question 29
{kind=link}
Answer
-
None
-
Loop unrolling
-
Loop fusion
-
Loop fission
Question 30
{kind=link}
Answer
-
Loop fission
-
Loop fusion
-
None
-
Loop unrolling
Question 31
Question
Program take as input a collection of relocatable object files and command-line arguments and generate as output a fully linked executable object file that can be loaded and run:
Answer
-
Static linker
-
Dynamic linker
-
Both
-
None
Question 32
Question
... involve identifying a computation that is performed multiple times (e.g., within a loop), but such that the result of the computation will not change.
Answer
-
Side effect
-
Code motion
-
Loop unrollin
-
Memory aliasing
Question 33
Question
... construct encloses code, forming a parallel region.
Answer
-
Parallel
-
Serial
Question 34
Question
... is the default schedule type. Upon entering the loop, each thread independently decides which chunk of the loop they will process.
Answer
-
static
-
dynamic
-
runtime
-
guided
Question 35
Question
By default, OpenMP _____ assigns loop iterations to threads. When the parallel for block is entered, it assigns each thread the set of loop iterations it is to execute?
Answer
-
static
-
dynamic
-
runtime
-
auto
Question 36
Question
The _______ directive causes threads encountering the barrier to wait until all the other threads in the same team have encountered the barrier.
Answer
-
single
-
barrier
-
nowait
-
private
Want to create your own Quizzes for free with GoConqr? Learn more.