6850891
Description
Flashcards by Valen Tina, updated more than 1 year ago
More
|
|
Created by Kathy H
over 9 years ago
|
|
|
|
Copied by Valen Tina
about 9 years ago
|
|
| Question | Answer |
| Ziel der deskriptiven und explorativen Datenanalyse | wichtigste Aussagen der Rohdaten beschreiben und grafisch darstellen |
| Schritte der statistischen Auswertung | - deskriptive Statistik - explorative Statistik - Inferenzstatistik |
| deskriptive Statistik | = alle Methoden zur zusammenfassenden Darstellung und Beschreibung von empirischen Daten - dazu dienen Kennwerte, Grafiken und Tabellen |
| explorative Statistik | = Durchsuchen der Daten nach bestimmten Mustern oder Zusammenhängen - bietet sich für komplexe Daten an |
| statistische Kennwerte | = grundlegendste & häufigste Möglichkeit zur Beschreibung von Daten - Anteile - Häufigkeiten - Lagemaße - Streuungsmaße |
| demografischen Daten | wird in fast allen Studien erfragt, z.B. Alter, Geschlecht, Familienstand... |
| Anteile und Häufigkeiten | = Daten in Nominalskala werden in Kategorien dargestellt (z.B. männlich, weiblich) --> dadurch entsteht die Häufigkeit (z.B. 30 von 50 etc.) Häufigkeit = nominal; Anteil = prozentual |
| Ratings | = differenzierte Darstellung der Kategorien (Intervallskala) = Erstellen von Reihenfolge der Werte |
| mögliche Darstellung von Anteilen und Häufigkeiten | - Zahlenwerte - Tabellen - Abbildungen (Diagramme) ,z.B. Histogramm, Kreisdiagramm |
| N (kursiv) | Anzahl von Personen, die an der Studie teilgenommen haben / Stichprobengröße |
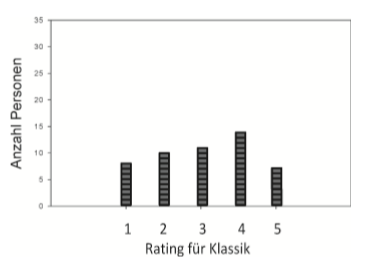
| Merkmalachse | X-Achse bei der Darstellung von Häufigkeitsverteilungen - dort steht das gemessene Merkmal = kategoriale Variable, gemessen auf Nominalskala |
| Häufigkeitsverteilungen | = Darstellung der Anzahl / Anteil von Personen, die bestimmten Messwert erzielt haben -bei der Häufigskeitsverteilung hanelt es sich um einzelne Personen |
| Charakterisierung der Häufigkeitsverteilung | -durch Lagemaß (Mittelwert alleine ist nicht aussagekräftig genug!) - zu jedem Lagemaß muss ein Streuungsmaß angegeben sein |
| Lage der Verteilung | = Wert, um den sich die Verteilung konzentriert |
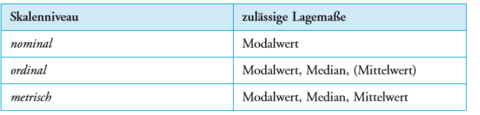
| Kennwerte für die Lage der Verteilung | = Lagemaße, stehen für Häufigkeitsverteilung - abhängig vom Skalenniveau: - Modalwert - Median -Mittelwert |
| Modalwert / Modus einer Verteilung | = häufigste Merkmalsausprägung, die am häufigsten vorkommt |
| Median | = welcher Wert liegt in der Mitte der Verteilung ->alle Werte der Größe nach aufschreiben, liegt Mitte zwischen zwei Werten, dann Mittelwerten bilden - robust gegenüber Ausreißern - erst ab Ordinalskala möglich - häufige Anwendung bei explorativer Datenanalyse |
| Modalwert ist nicht gleich Median | bei einer unsymmetrische Häufigkeits-verteilung |
| Mittelwert (Summe Einzelwerte/ Gesamtwerte) | - wird auf eine Nachkommastelle gerundet - häufigstes Lagemaß - Ausreißer beeinflussen M - notwendig für weitere statistische Berechnungen - steht stellvertretend für Verteilung |
| Vorteile Mittelwert | -Mittelwert beschreibt die Daten am exaktesten -mathematische Mitte der Verteilung -bei nicht symmetrischer Verteilung Median verwenden -Mittwelwert nahe an Median & Modalwert-->symmetrische Verteilung |
| x (kursiv) | einzelner Messwert |
| i (kursiv) | Index (Person1, Person 2,usw.) |
| Unterschied der grafischen Darstellung des Mittelwerts vs. Häufigkeitsverteilung | Bei grafischer Darstellung des Mittelwertes: - Merkmal auf Y-Achse - Keine Häufigkeitsverteilung , da keine Personen --> Mittelwerte entstehen aus Häufigkeitsverteilungen |
| Mittelwerte auf Ordinalskala | sollte vermieden werden. Differenz zwischen Stufen der Ordinalskala ist nicht ersichtlich, deswegen ist Mittelwert nicht dafür geeignet |
| Lagemaße bei unterschiedlichen Skalenniveaus | |
| Streuungsmaße | - Spannweite (Range) - Interquartilsabstand - Varianz - Standardabweichung |
| Spannweite | = Differenz zwischen größten und kleinsten gewählten Wert der Daten - schlechte Differenzierung zwischen unterschiedlichen Verteilungen - anfällig gegenüber Ausreißern - seltene Anwendung |
| Interquartilsabstand | -Werte der Größe nach aufschreiben, 4 Quartile bilden, Differenz zwischen oberen & unteren Quartil bilden - besser zwischen verschiedenen Verteilungungen differenzieren -robust ggü. Ausreißern, für explorative Datenanalyse, aber keine exakte Streuungsangabe möglich |
| Varianz (s²) | = durchschnittliche quadrierte Abweichung aller Werte vom gemeinsamen Mittelwert |
| Standardabweichung (s oder SD) | = Wurzel aus Varianz -Varianz liefert Durchschnitt quadrierter Werte-->schwer interpretierbar, daher Wurzelziehung |
| bestes Streuungsmaß um die durchschnittliche Abweichung vom Mittelwert zu bestimmen | Varianz und Standardabweichung (sehr genaue Differenzierung zwischen den unterschiedlichen Verteilungen) |
| Kennwerte | = Angaben über Stichproben (z.B. Mittelwerte, SD) - lateinische Buchstaben |
| Parameter | = Angaben über Populationen - Schätzwerte - griechische Buchstaben |
| Varianzaufklärung | = wichtigstes Ziel der Statistik = welchen Anteil der Varianz der AV kann die UV aufklären |
| Fehlervarianz | = Teil der Varianz, der aufgrund der natürlichen Streuung entsteht |
| durch UV hervorgerufene Varianz | = Effekt der UV = Anteil an der Gemsatzvarianz, welcher durch die UV aufgeklärt wird, sollte möglichst gorß sein -Anteil der Fehlervarianz an der Gesamtvarianz möglichst klein |
| Gesetz der großen Zahlen (Jakob Bernoulli) | = Je größer die Stichprobe desto eher entspricht die Häufigkeitsverteilung der Populationsverteilung --> wir vertrauen großen Stichproben mehr als kleinen (ab 30 Personen zuverlässige Werte) |
| unsichtbare Populationsverteilung | die Populationsverteilung ist unbekannt, deswegen: große Stichprobe --> Schätzung der entsprechenden Werte in der Population |
| Formen der Verteilung | - symmetrische Verteilung - schiefe Verteilung -unimodale Verteilung - bimodale Verteilung |
| schiefe Verteilung | = Verteilung ist in eine Richtung eingeschränkt (systematisch) -Zufällige Abweichung durch untypische Werte oder Ausreißer -> z.B. Deckeneffekt (weiter nach oben ist nicht möglich) --> Mittelwert ist ebenfalls verzerrt |
| unimodale Verteilung | = ein "Gipfel"/Hochwert in der Verteilung |
| bimodale Verteilung | = Variable hat zwei Merkmalsausprägungen (Gipfel/Höchstwerte) --> Mittelwert wenig informativ, weil es keine Mitte gibt |
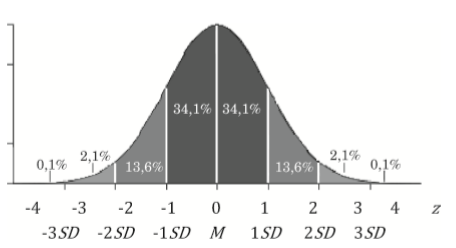
| Normalverteilung | = symmetrische und unimodale Verteilung in einer Glockenform (Gauss'sche Glockenform) |
| Vorteil der Normalverteilung | + Wissen: Merkmale sind normalverteilt --> Form der Verteilung klar --> nur noch Mittelwert und Streuung notwendig ABER: immer Normalverteilung prüfen! |
| z-Transformation / z-Standardisierung | = unterschiedliche Skalen auf eine Skala transformieren und so umrechnen und vergleichbar machen |
| Besondere an z-Transformation | = standardisierte Skala Mittelwert = 0 SD = 1 -->muss für jeden Wert einzeln berechnet werden -jedem Messwert wird standarsierter z-Wert zugeordnet |
| z-Verteilung / Standardnormalverteilung | = stellt dar wie viel Prozent über / unter dem Mittelwert sind; gibt auch Fläche der Verteilung an |
| grafische Datenanalyse bei der explorativen Datenanalyse | - Boxplot - Stamm- & Blatt-Diagramm - Streudiagramm (Scatterplot) - Sonnenblumendiagramm - Bubble Plot - Streudiagrammmatrix (Scatterplotmatrix) |
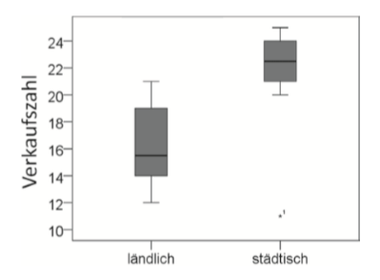
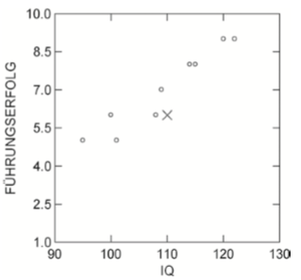
| Boxplot | = grafische Darstellung des Median (Strich im Kasten) und Interquartilsabstand (graue Box) |
| Informationen, die man aus der Boxplot zieht | - Median -> deutet auch die Verteilung an - Interquartilsabstand - Ausreißer vorhanden? (mit Stern und Nummer versehen) -->Enzelne Werte weit entfernt von der Box - Whiskers |
| Whiskers (Barthaare) | = kleinen Querstriche oben und unten des Boxplot -Interquartilsabstand * 1,5 (oben und unten der Boxplot) -Nur die Werte die außerhalb den Whiskers sind, sind Ausreißer |
| Vorteile von Boxplot | + unverzerrte Darstellung der Rohdaten + Ausreißer identifizieren --> werden meist aus Daten entfernt um Verzerrung vom MIttelwert & Streuung zu vemeiden & weitergehende Analysen zu ermöglichen +bildet Verteilung einzelner Variablen ab +Teil explorativer Datenanalyse |
| Stamm- und Blatt-Diagramm (Stem & Leaf Plot) | - jede Zahl bei Leaf = 1 Person * zwischen 0-4 und . 5-9 -> liegt aber im eigenen Ermessen |
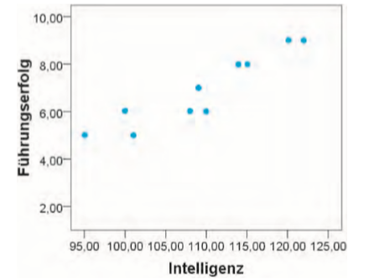
| Streudiagramm (Scatterplot) | Darstellung von zwei Variablen in einem Diagramm; 1 Person = 1 Punkt |
| Sonnenblummendiagramm | übereinstimmende Daten werden als Sonnenblumen dargestellt; ansonsten wären identische Werte nicht ersichtlich |
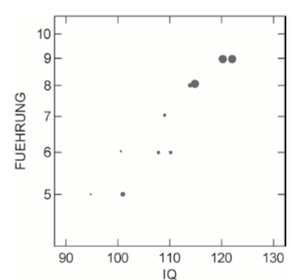
| Bubble-Plot | 3 Variablen, dritte wird in der Größe des Punktes dargestellt |
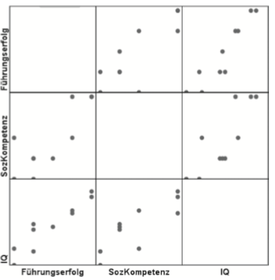
| Streudiagramm-Matrix (Scatterplot-Matrix) | Darstellung mehrerer Variablen durch jeweilige Streudiagramme von 2 Variablen |
| (bivariaten) Korrelation (Francis Galton) | = Ausmaß des linearen Zusammenhangs zweier Variablen -man erhält die Korrelation durch die Standerisierung der Kovarianz -Größe des Zusammenhangs in standarisierter Form ausgedrückt -bi-variant=zwei Variablen |
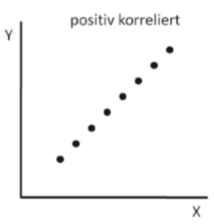
| positiv korrelierte Daten | Datenpunkte folgen einer Linie & bilden linearen Zusammenhang, steigende Werte auf X-Achse &steigende Werte auf Y-Achsse |
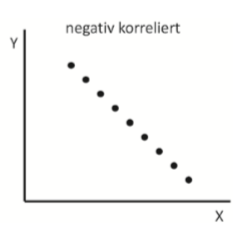
| negativ korrelierte Daten - steigende Werte auf X-Achse & sinkende Werte auf Y-Achse | linearer Zusammenhang, aber perfekte Datenzusammenhänge kommen in der Forschung eher nicht vor |
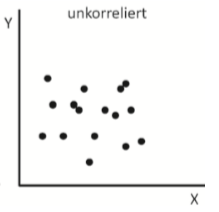
| unkorrelierende Daten | Es besteht kein Zusammenhang |
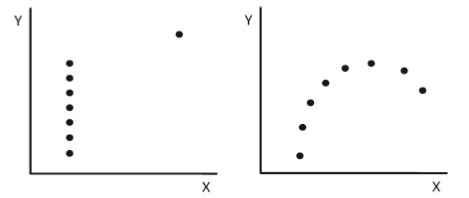
| nicht lineare Zusammenhänge | - werden nicht weiter berechnet - kurvilinearen Zusammenhänge sind nicht selten |
| Kovarianz | = zwei Variablen sind in der Ausprägung abhängig voneinander - gleiche Skala notwendig --> unterschiedliche Skala: Korrelation |
| Korrelationskoeffizient (Karl Person) | Kovarianz unabhängig der Skala zu machen Anwendung der Streuung --> Kovarianz / Streuung beider Variablen = Korrelation (r) (Werte zwischen -1 und 1) s=Standardabweichung |
| Regression | = Vorhersageanalyse - nutzt Korrelation, um Werte der Variable 1 (Kriterium) aus den Werten der Variable 2 (Prädiktor) hervorzusagen |
| Korrelationskoeffizient | = Varianzaufklärung Alle Werte auf einer Geraden -> beide Variablen voneinander abhängig |
| Gründe für keine vollständige Gesamtvarianz | - Messfehler -fehlerhafte Messinstrumneter (Fragebögen, Tests) - Varianz korreliert nicht nur mit einer Variable sondern mit mehreren |
| Interpretation von Korrelation nach Cohen (Faustregel) | |
| Voraussetzungen für Korrelationsberechnung | - intervallskalierte Daten oder dichotome Variablen - linearer Zusammenhang (mithilfe eines Streudiagramms prüfen) |
| Korrelation vs. Kausalität | Korrelation lässt keine Rückschlüsse auf inhaltliche Kausalität zu |
| mögliche Zusammenhänge zwischen Variablen (kein inhaltlicher Zusammenhang) | - X ruft Y hervor - Y ruft X hervor - Zusammenhang zwischen X und Y wird durch Z bedingt (=Scheinkorrelation) -Viele Storche (X) = viele Babys (Y) --> Drittvariable Z (Anzahl d. Regentage) steckt dahinter |
| Wichtigkeit von Experimenten für die Forschung | = aus experimentell gewonnene Daten berechnete Korrelation lassen Kausalschlüsse zu |
| dichotome Variablen | = Variable hat zwei Ausprägungen |
| Regressionsgerade | Bestimmung der Gerade: - Gerade beliebig in Punktewolke legen - Abweichungsquadrat bestimmen (Abstand der Punkte zur Geraden vertikal messen & quadrieren) - Quadratsumme bilden (Abweichungsquadrat aller Punkte) - Gerade anpassen bis die Quadratsumme so gering wie möglich ist |
| Vorhersagefehler / Residuum / Residualwert | = Differenz zwischen Schätzung und wahrem Y-Wert; = Abweichungen auf Y von der Regressionsgerade --> ist nicht erklärbar --> Y-Wert ist nur eine Schätzung! |
| Anwendungsfelder der Regression | - konkrete Werte einer Variable vorherzusagen - Enge des Zusammenhangs & Güte der Vorhersage (durch Korrelationskoeffizienten r beschrieben) |
| Determinationskoeffizient r² | = Ausmaß der Varianzerklärung von Variable Y zu Variable X = Korrelationskoeffizient ² -kann max. 1 betragen-->entspricht Varianzaufklärung von 100% -direkte Beziehung zum Schätzfehler |
| einfache lineare Regression | = schätzt den Wert einer Person mithilfe der Ausprägung einer Prädiktorvariable auf einer Kriteriumsvariable - beruhen auf bivariater Korrelation |
| Werte der Regression | - β (Beta-Gewicht) = r (bei bivariater Korrelation) - r² (Determinations-Koeffizient) -b=Regressionsgewicht-->Anstieg der Gerade |
| Allgemeines zu Varianz und Standardabweichung | -Spannweite & Interquartilsabstand--> nur einzelene Werte einbezogen -exaktes Streuungsmaß ermöglichen Varianz & Standardabweichung-->wie gut repräsentiert der Mittelwert die Verteilung -beziehen sich konkret auf Mittelwert -->wie weit weichen alle Werte in der Verteilung im Durchschnitt von ihm ab |
| Berechnung der Varianz im Detail | -Von jede Wert xi wird der Mittelwert aller Daten X abgezogen -all diese Differenzen werden quadriert & aufsummiert -die Summe wird durch die Stichprobengröße N geteilt |
| Allgemeines zur Standardabweichung | -werden zwei Stellen nach dem Komme gerundet -im Sinne der Maßeiheit lassen sich die Rohdaten interpretieren |
| Der Sinn der Streuungsmaße -1- | -da man nicht weiss, wie die Verteilung aussieht, werden stellvertretend Kennwerte angegeben -Kennwerte erhalten wir durch Lage- & Streuungsmaße |
| Mittelwert und Streuungsmaß | -Zu jedem Mittelwert sollte ein Streuungmaß angegeben werden, da der Mittelwert sonst nutzlos ist -Je kleiner die Streuung, desto besser |
| Zusmmenhang Mittelwert, Varianz und SD | -zu jedem Mittelwert sollte die Varianz & Standardabweichung angegeben werden--> Hinweis, wie gut der Mittelwert die Daten der Vertelung repräsentiert -Stichprobe= Ausschnitt aus der Population |
| Stichprobengröße | -nach oben durch ökonomische Gesichtspunkte begrenzt: --> mehr Personen=mehr Kosten & mehr Mitarbeiter & mehr Zeit -deshalb sind Stichprobengrößen von 30-100 Personen ausreichend |
| Boxplot- Ablesen der Daten | -untere Ende der Box=untere Quartil -obere Ende der Box=obere Quartil -Höhe der Box=Auskunft über Streuung |
| Stamm- und Blatt-Diagramm Allgemeines | -Verteilung einzelner Variablen mit allen Rohwerten -jeder Person taucht in der Abbildung mit konkreten Werten auf-->kein Informationsverlust -dient Erkennen von schiefen & untypischen Verteilungen -Teil explorativer Datenanalyse |
| Stamm- und Blatt-Diagramm | -Diagramm beginnt mit d. Stamm (Stem)--> gibt Einheit an - Zahlen, die vor Komma stehen, werden an den Stamm geschrieben (z.B. 0,5-5,6) -dahinter ist jede Person als Blatt (Leaf) vertreten-->mit Wert hinter dem Komma |
| Streudiagramm im Detail | -Darstellung von Zusammenhänge zwischen zwei Variablen -jede Person= 1 Punkt,wo sich ihre Werte auf beiden Variablen kreuzen -alle Punkte zusammen, bilden die Punktewolke -Teil der explorativen Datenanalyse |
| Sonnenblumendiagramm im Detail | -Darstellung von Zusammenhängen von zwei Variablen-->Verteilung erstreckt sich in die Breit, nicht in die Höhe -Angabe d. Personenanzahl, die sich hinter einem Punkt verbirgt -->für jede Person wird eine Blüte dargestellt |
| Bubble-Plot im Detail | =Zusammenhang der Variable z.B. soziale Kompetenz mit den beiden anderen Variablen -Je größer ein Kreis,desto stärker d. Ausprägung, z.B. soziale Kompetenz |
| Streudiagramm-Matrix (Scatterplot-Matrix) im Detail | -überblickmäßige Darstellung einzelner Streudiagramme -Betrachtung von zwei Veriablen--> 3 Zusammenhänge: Variable 1&2, 1 &3 ,2& 3 -Erhalt von 3 Diagrammen, die in einer Matrix dargestellt werden -Matrix= symmetrisch (Betrachtung obeneren rechten Teils ausreichend) |
| Kovarianz | = Ausmaß des linearen Zusammenhangs zweier Variablen in nicht standarisierter Form -Ausmaß, in welchem zwei Variablen gemeinsam variieren (bzw. abhängig von einander sind oder zusammen schwanken) |
| Sinn der Regressionsrechnung | -Sinn der Regressionsrechung= Schätzungen für alle möglichen X-Werte zu machen -Gerade ist die beste Schätzung für die Vorhersage von Y-Werten-->Gerade repäsentiert alle Punkte im Durchschnitt bestmöglich |
| Regressionsgleichung berechnen | -durch zwei Größen bestimmt: Schnittpunkt mit Y-Achse (a), Steigung (b) -(e)= Schätzfehler -durchschnittlicher Schätzfehler= Quadratsummer geteilt durch N |
| Determinationskoffoeffizient r² im Detail | -r²= 64 -->Varianzaufklärung von 64%; 64% von Führungserfolg durch Intelligenz aufgeklärt -36% auf Messfehler & andere Einflussvariablen zurückzuführen -r²=1 --> Schätzfehler= 0, kein Risiduen |
{kind=link}
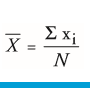{kind=link}
{kind=link}
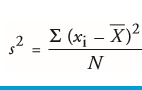{kind=link}
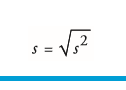{kind=link}
{kind=link}
{kind=link}
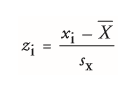{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
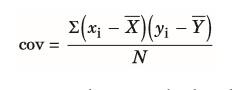{kind=link}
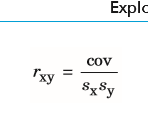{kind=link}
{kind=link}
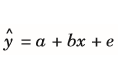{kind=link}
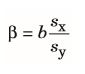{kind=link}
Want to create your own Flashcards for free with GoConqr? Learn more.