6987683
Description
Flashcards by Valen Tina, updated more than 1 year ago
More
|
|
Created by Kathy H
over 8 years ago
|
|
|
|
Copied by Valen Tina
about 8 years ago
|
|
| Question | Answer |
| Regressionskoeffizienten b | =auch Regressionsgewichte genannt = wie groß ist der relative Einfluss eines Prädiktor bei der Vorhersage der abhängigen Variable (der Einfluss der anderen Prädiktoren wurde bereinigt) |
| Beta Gewicht β | standardisierter Regressionskoeffzient -->geben dann den Einfluss eines Prädikators auf Kriterium in Standardabweichungseinheiten |
| Aufklären von Variablen in der multiplen Regression | = Summe von Variablen wollen konkreten Wert (=Y) einer Person vorhersagen -X = genaue Ausprägung der Variablen -a=Regresionskonstante (für alle Personen gleich) |
| multiple Regression | = schätzt den Wert einer Person mithilfe der Ausprägungen mehrerer Prädiktorvariablen auf einer Kriteriumsvariable |
| Güte der Vorhersage bei multipler Regression | = wie gut ist das gesamte Modell (=Auflistung mehrerer Prädikatoren in d. Reggression) für die Vorhersage des Kriteriums geeignet -Zwei verschiedene Möglichkeiten um es heraus zu finden, durch...: - Standardschätzfehler - multiplen Determinationskoeffizient R² =beide geben das Ausmaß der Varianzaufklärung an |
| multiplen Determinationskoeffizient R² | -gibt den Anteil der Varianz des Kriteriums an, der durch alle Prädiktoren gemeinsam erklärt wird -max. Wert = 1 -->entspricht Varianzaufklärung von 100% |
| Standardschätzfehler bei der multiplen Regression | wie stark weichen im Durchschnitt die vorhergesagten Werte vom tatsächlichen Wert des Kriteriums ab -->kann direkt aus R² bestimmt werden, da R² in direkter Beziehung zu Se steht |
| Prüfung des einzelnen Regressionsgewicht auf Signifikanz | -Berechnung d. t-Wertes aus ß -t-Wert mit n -2 Freiheitsgraden auf Signifikanz prüfen -für jedes einzelnes Regressionsgewicht ß kann eigener Standardfehler Se, Konfidenzintervall & Signifikanztest berechnet werden |
| Signifikanztests bei multipler Regression | wird meist drauf verzichtet, da R² gute Info darstellt Signifikanztest für das komplette Modell: F-Test |
| t-Test | = prüft, ob sich Mittelwerte signifikant unterscheiden (Mittelwerte aus un- & abhänigigen Stichproben o. Mittelwert, der gegen einen theoretisch zu erwartetenden Mittelwert getestet wird) -umfasst eine Gruppe von Tests - Prinzip aller Signifikanztests: systematische Varianz (Mittelwertsunterschied) geteilt durch Fehlervarianz (SD) |
| t-Test bei zwei unabhängigen Stichproben | = prüft die Signifikanz eines Unterschiedes - Mittelwertsunterschied der Stichprobe wird verglichen mit Mittelwertsunterschied von H0 |
| kritischer t-Wert bei unabhängigen Stichproben | -ergibt sich aus der t-Verteilung eines bestimmten Signifikanzniveau (5 oder 1 Prozent) - wird mit empirischen t-Wert verglichen (empirischer Wert muss extremer/absolut größer sein, um signifikant zu sein, da in d. tabelle nur positive Werte abgetragen werden)--> Effekt kann verallgemeinert werden) |
| Freiheitsgrade bei unabhängigen Stichproben bei dem t-Test | |
| Berechnung des t-Werts bei abhängigen Messungen | •Um den t-Wert berechnen zu können, muss zunächst der Standardfehler des Mittelwertunterschiedes berechnet werden: ÔX diff= Ôdiff/ √n |
| t-Test bei einer Stichprobe / Einstichprobenfall | = Mittelwert einer Gruppe wird gegen zweite theoretische(bereits bekannte Mittelwerte,z.B. IQ) Gruppe verglichen -Vorher Berechnung Standardfehler d. Mittelwertes: Ô⨱= Ô_ √n |
| Effektgrößen bei unabhängigen Stichproben | Bestimmung von Effektgrößen bei Mittwelwertsunterschieden durch Becrechnung Abstandsmaße aus Rohdaten o. aus Signifinkanztests: - Abstandsmaß d - Abstandsmaß g - Korrelation r - Korrelationskoeffizienten |
| Abstandsmaße beim t-Test (unabhängige Stichprobe) | |
| Korrelation bei t-Tests (unabhängige Stichprobe) | ist identisch mit Korrelationskoeffizienten |
| Effektgrößen bei abhängigen Stichproben | - Abstandsmaße d und g identisch bei Einstichprobenfall |
| Voraussetzungen beim t-Test | - AV ist intervallskaliert - Normalverteilung - ca. gleich große Varianzen - bei unabhängigen Stichproben: Personen beeinflussen sich nicht systematisch gegenseitig |
| Varianzanalyse (ANOVA) | = Verfahren zum Vergleich von Varianzen = Sonderform der multiplen Regression = Vergleich mehrer Mittelwerte möglich - UV darf nominalskaliert sein -t-Test ist eine Sonderform von ANOVA -Verhältnis zwischen erklärter & nicht erklärter Varianz wird untersucht -Varianz in diesem Verhältnis groß genug -->signifikantes Ergebnis |
| einfaktorielle ANOVA | = nur eine unabhängige Variable (Faktor) wird untersucht = einfachster Fall -z.B. Stress bei d. Nutzung verschiedener Verkehrsmittel |
| relevante Varianzen bei der einfaktoriellen ANOVA | - Gesamtvarianz - erklärte Varianz - nicht erklärte Varianz |
| Gesamtvarianz bei einfaktorieller ANOVA | = Varianz der AV = Summe aus erklärte + nicht erklärte Varianz |
| erklärte Varianz | = Varianz zwischen den Gruppen =Between Varianz =systematische Varianz - mehrere Mittelwertsdifferenzen (Varianz der Mittelwerte), da zwischen jeder Gruppe die Differenz berechnet wird |
| unerklärte Varianz | = unsystematische Varianz =Varianz innerhalb der Gruppe =Within-Varianz =Fehlervarianz - Menschen unterscheiden sich und liefern entsprechend unterschiedliche Werte - stellt Fehler dar, der die Aussagekraft unserer Mittelwerte einschränkt |
| Maß der Streuung bei der Varianzanalyse | = Quadratsummen (QS) - sind noch nicht an der Stichprobengröße relativiert |
| Berechnung der Gesamtvarianz bei einfaktorieller ANOVA | =X mit 2 Querstrichen ist der gemeinsame Mittelwert aller Daten -Differenz einzelner Messwerte X zum gemeinsamen Mittelwert gebildet, quadriert & aufsummiert |
| Berechnung der systematischen Varianz (einfaktorielle ANOVA) | = Streuung der Stichprobe - Streuung sollte möglichst groß sein, da wir ja wollen, dass sich unsere Mittelwerte unterscheiden -Gesamtmittelwert X Strich 2 von jedem Gruppenmittelwert _Xi abziehen,Quadrate mit jeweiligen Grußße ni multiplizieren |
| Fehlervarianz bei einfaktoriellen ANOVA | -Mittelwert der jeweiligen Gruppe wird verwendet, da wir wissen wollen wie stark die Werte innerhalb der Gruppe variieren -Mittelwert d. jeweiligen Gruppe wird von jedem Mittwelwert abgezogen |
| Freiheitsgrade bei einfaktorieller ANOVA | k = Anzahl von Gruppen N = Gesamtstichprobe |
| F-Test und t-Test | bei zwei Gruppen kommen sie zum gleichen Ergebnis (F = t²) o. (t=√F) - F kann nicht negativ sein --> kann Richtung des Unterschieds nicht definieren, testet immer einseitig -F-Werte & t-Werte sind ineinander überführbaar - bei mehr als 2 Gruppen kann nicht mehrmals ein t-Test durchgeführt werden, denn dadurch verdoppelt sich die Wahrscheinlichkeit des Alpha-Fehlers |
| Einzelvergleiche (Post-hoc-Tests) - Zusatz bei Berechnung der ANOVA | = Prüfen der einzelnen Mittelwerts-unterschiede auf Signifikanz im Nachhinein - funktionieren wie t-Tests, allerdings wird Kumulation der Alpha-Fehler berücksichtigt (Alpha-Korrektur) - so viele Einzelvergleiche wie mögliche Vergleiche (Ergebnis p-Wert für jeden Mittelwertsunterschied) -keine Anzeige d. Richtung d. Mittelwertsunterschiedes -->daher Betrachtung d. Diagramms o. Boxplots |
| Ablauf der mehrfaktoriellen Varianzanalyse | F-Wert berechnen für jede UV ( dabei wird die jeweilige andere UV außer Acht gelassen) |
| Haupteffekt | -bei mehrfaktoriellen Varianzanalyse = Effekt der UV = Prüfung: haben die einzelnen UV einen signifikanten Effekt auf die AV ? - pro UV gibt es einen Haupteffekt |
| Interaktion | = prüfen, ob eine gegenseitige Beeinflussung der beiden UV's vorliegt = bedingter Mittelwertsunterschied (Wenn-dann-Bedingung), z.B. Stressniveau bei Benutzung verschiedener Verkehrsmittel zwischen Männern & Frauen - nicht durch die Wirkung einzelner Haupteffekte erklärbar, sondern durch deren Kombination Wirkung auf AV - nicht parallele Linien im Diagramm weisen auf Interaktion hin |
| Berechnung der Interaktion | -Varianz AxB = Gesamtvarianz minus alle bekannten Varianzen -Varianz durch Fehlervarianz |
| Varianzanalyse mit Messwiederholungen | = Abhängige Messungen =systematische Varianz durch Fehlervarianz teilen |
| Freiheitsgrade bei abhängigen Messungen (F-Verteilung) | -k=Anzahl der Messwiederholungen -n=Anzahl der Personen |
| Mixed Models/ gemischte Designs | = mehrfaktorielle Varianzanalysen, bei denen abhängige und unabhängige Messungen gemischt sind -z.B. für Messwiederholungen zusätzlich untersuchen,ob die Effekte bei Männern & Frauen unterscheiden --> abhängige Messung (Verkehrsmittel) mit unabhängigen Messung (Geschlecht() vermischt |
| Effektgrößen bei der Varianzanalyse | = Eta-Quadrat = wie groß ist der Anteil der UV-aufgeklärten Varianz an der Gesamtvarianz |
| Eta-Quadrat bei einfaktorieller ANOVA | Wie viel Prozent an Gesamtvarianz kann die UV aufklären |
| Eta-Quadrat für alle Arten von Effekte | - für Feffekt belieibiger F-Wert mit dazugehörigen Freiheitsgraden angegeben werden -für F-Werte von Haupteffekte, Interaktionen oder Messwiederholungen (dfFehler anstatt dfinn einsetzen) |
| partielles Eta-Quadrat ῃ² | = bezieht sich nur auf einen Part bei der mehrfaktoriellen Varianzanalyse |
| Interpretation von Eta-Quadrat ῃ² | |
| Voraussetzung für Varianzanalyse | - AV muss intervallskaliert sein -Messwerte Normalverteilung folgen (Werte in der Population sollen normalverteilt sein) - Varianz aller Messwerte in allen Gruppen gleich groß |
| F-Test als Signifikanztest bei Regressionsrechnung | = kann das Ergebnis der Regressions-rechnung auf Population übertragen werden (Güte der Vorhersage) -durch Prädikator aufgeklärte Varianz durch Fehlervarianz teilen - signifikantes Ergebnis = >0 |
| erklärte Varianz zur Berechnung des F-Wertes bei der Regressionsrechnung | -erklärte Varianz ergibt sich aus Vorhersage d. y-Werte & Vorhersage schätzt y-Werte (Yi), die entsprechend d. jeweiligen Ausprägung von x vom Mittelwert laler Daten (_Y) verschieden sind |
| Fehlervarianz zur Berechnung des F-Wertes bei der Regressionsrechnung | -Fehlervarianz=mitteleren Residuen, d.h. nicht erklärtem Varianzanteil =Differenz von vorhergesagten (Dach yi) & tatsächlichen Werten (yi) |
| Alternative zur Berechnung des F-Wertes bei Regressionsrechnung | -k=Anzahl d. Prädikatoren -n=Anzahl d. untersuchten Personen |
| Kolmogorov-Smirnov-Test | = Signifikanztest zur Prüfung, ob eine Normalverteilung vorliegt - sollte nicht signifikantes Ergebnis liefern, da sich die Verteilung nicht signifikant von einer Normalverteilung unterscheidet -->keine Berehnung mithilf t-Tests o. Varianzanalyse möglich |
| Parametrische Testverfahren | = setzen bestimmte Verteilung (i.d.R. Normalverteilung) von Populationsparameter voraus - daraus resultieren Berechnungen zum Mittelwert, Mittelwertsunterschied, F-Wert, t-Wert... |
| Nonparametrische / verteilungsfreihe Verfahren | = machen keine Annahme über die Verteilung der Parameter - bei nominal- oder ordinalskalierten Daten & nicht normalverteilten Daten |
| Vor- und Nachteile von nonparametrische Verfahren | + Verteilungsfreiheit + Untersuchung sehr kleiner Stichproben + alle Fragestellungen können untersucht werden - Signifikanz ist schwerer festzustellen (in d. Population vorhandene Effekte können schwerer entdeckt werden-->geringe Teststärke) |
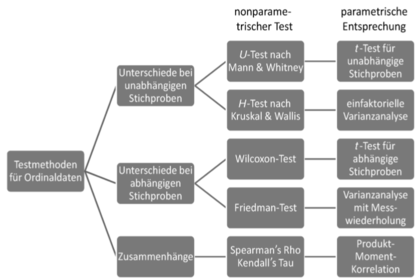
| Nonparametrische Testverfahren bei Ordinalskalen | - Durchführung für Zusammenhangs- und Unterschiedsfragestellungen (haben parametrische Entsprechung) - Messwerte werden als Ränge behandelt -umgeht Normalverteilungsanhnahme |
| Übersicht parametrische und nonparametrischer Verfahren bei Ordinalskalen | |
| Test für Unterschiede bei zwei unabhängigen Stichproben (nonparametrisches Verfahren) | - U-Test nach Mann und Whitney: Abstand zwischen den beiden mittleren Rängen (Daten d. Größe nach aufschreiben & Ränge zuordnen) -Maß = zentrale Tendenz = Median -Ziel: Vergleich der mittleren Ränge in einer Reihe von Rängen für beide Gruppen |
| U-Test nach Mann und Whitney (nonparametrisches Verfahren) | Erstellung einer gruppenunabhängigen Rangreihenfolge --> Erstellung der Rangsumme (T) je Gruppe --> Erstellung des durchschnittliches Ranges (T/n) (=deskriptives Ergebnis) U = Berechnung der Signifikanz des Unterschieds T1=Rangsumme Gruppe 1 |
| empirischer Wert des U-Tests (nonparametrisches Verfahren) | = kleinere Wert der beiden Gruppen --> muss gleich oder kleiner sein als der kritische Wert (aus Tabelle) um signifikant zu sein -Berechnung: U´=n1*n2-U, um weiteres U zu berechnen, indem man T2 abzieht |
| U-Test bei großen Stichproben (nonparametrisches Verfahren) -->Umrechnung U-Werte in z-Werte | |
| Tests für Unterschiede bei mehr als zwei unabhängigen Stichproben (nonparametrisches Verfahren) | Vorgehen identisch wie bei 2 Stichproben --> Test ist H-Test nach Kruskal und Wallis (Rangesumme d. Gruppen berechnet & Signifikanz geprüft) - bei großen Stichproben besteht eine Chi-Quadrat-Verteilung --> folgt bestimmter Verteilung |
| Tests für Unterschiede bei zwei abhängigen Stichproben (nonparametrisches Verfahren) | = Wilcoxon-Test / Vorzeichenrangtest (Differenzen von Messwerten innerhalb einer Person) - Differenz für jede Person zwischen Messung1 und Messung2 --> Rangreihenfolge nach steigender Differenz festlegen (Vorzeichenunabhängig, aber Kennzeichnung des Vorzeichen notwendig) --> Addition der jeweiligen Rangsummen zu T+ und T- |
| Interpretation des Wilcoxon-Tests | -T+ und T- stellen die Prüfgröße dar -wir verwenden den kleineren der beiden Werte für die Signifikanzprüfung --> kleiner/gleich als kritischer T-Wert laut Tabelle |
| Tests für Unterschiede bei mehr als zwei abhängigen Stichproben (nonparametrisches Verfahren) | = Friedman-Test bzw. Rangvarianzanalyse Ablauf: Messwertdifferenzen werden über die Messzeitpunkte hinweg nach Rang sortiert und Rangsummen d. positiven & negativen werden verglichen - Prüfgröße: Chi-Quadrat |
| Tests für Zusammenhänge (nonparametrisches Verfahren) | = Rangkorrelation --> korreliert die Ränge der jeweiligen Rohwerte Bedingung: monotone Variablen -->kein Richtungswechsel erlaubt wie auf dem Bild |
| Ablauf der Rangkorrelation (nonparametrisches Verfahren) | - Messwerte in Rangreihenfolge darstellen - Messwerte beider Variablen einzeln in Rangreihenfolge bringen! --> korreliert werden die Rangreihen beider Messgruppen |
| Möglichkeiten der Berechnung der Rangkorrelation (nonparametrisches Verfahren) | - Spearman's Rho (p) - Kendalls Tau (τ) |
| Anwendung von Spearman's Rho (p) | - intervallskalierten Daten, aber verletzte Voraussetzungen f. Person-Korrelation - Anwendung als wären Abstände zwischen Rängen gleich groß --> Voraussetzung: intervallskalierte Daten - Signifikanzprüfung mittels t-Test - Größenordnung wird nicht beachtet |
| Berechnung von Spearman's Rho (p) | d(i) = RZ(xi) - RZ (yi) (Differenz zwischen den Rangzahlen) RZ= Rangzahl n=Anzahl der Beobachtungswerte -lediglich Reihenolge d. Beobachtungswerte berücksichtigt, Größenordnung unberücksichtigt |
| Kendalls Tau (τ) | -setzt keine gleichen Rangintervalle voraus -Alternative zu Rho - Werte zwischen -1 und 1 - Signifikanzprüfung mittels z-Test |
| Effektgrößen bei Ordinaldaten | - sind nicht bestimmbar - Unterschiedsfragestellungen: auf Signifikanztest berufen - Zusammenhangsfragestellungen: Rangkorrelation, Interpretation wie Pearson-Korrelation - aber i.d.R. kleinere Werte |
| Anpassungstest (nominalskalierte Variable) | = Chi-Quadrat-Test (X²-Test) - prüft ob empirische Häufigkeitsverteilung mit theoretisch zu erwartenden Häufigkeitsverteilung übereinstimmt |
| Berechnung des Anpassungstests | f(b) = beobachteten Häufigkeiten, mit d. alle potenziellen Merkmalsausprägungen f(e) = erwarteten Häufigkeiten aus theoetischer Überlegung -wird für jede beobachtbare Häufigkeit berechnet und dann alle entsprechend addiert |
| Interpretation des Anpassungstests (nominalskalierte Variable) | -erwartete Häufigkeit = Nullhypothese -empirischer X²-Wert muss extremer als kritischer X²-Wert sein um signifikant zu sein -Berechnung Freiheitsgrade: df = k - 1 -k=Anzahl d. Merkmalsausprägungen |
| Goodness-of-fit-Test | -Anpassungstest zur Prüfung der Verteilung, vor allem bei komplexen Testverfahren - prüft, ob zwei Verteilungen deckungsgleich sind |
| Unabhängigkeitstest bei zwei nominalskalierten Variablen | = prüft, ob die Ausprägung einer Variable unabhängig von der Ausprägung einer anderen Variable ist -Form d. einen Häufigkeitsverteilung von d. Form d. anderen Häufigskeitsverteilung abhängt = X²-Test = k*l-X² |
| Kreuztabelle / Kontingenztabelle | -bilden verschiedene Kombinationsmöglichkeiten der Ausprägungen der nominalskalierten Variablen ab -k*l = Menge der Kombinationsmöglichkeiten (6*3=18 Kombinationen, da k=3 Spieler & l =6 Ausprägungen des Würfels) |
| Berechnung von X² Unabhängigkeitstest (nominalskalierte Variable) | -Formel für beide Variablen (deswegen zwei Summenzeichen) -1. Summenzeichen= Differenz von beobachteten & erwarteten Häufigtkeit für jede Auspräung d. ersten Variable -2. Summenzeichen=gleiche Prozedur für alle Ausprägungen d. zweiten Variable |
| Freiheitsgrade bei X² Unabhängigkeitstest (nominalskalierte Variable) | df = (k-1)(l-1) |
| Interpretation von X² Unabhängigkeitstest (nominalskalierte Variable) | Test ist signifikant, dann ist die Häufigkeitsverteilung der einen Variable nicht unabhängig von der Ausprägung der anderen Variable ist (genauen Unterschiede entnimmt man der Kreuztabelle) |
| Bestimmung der Häufigkeit, wenn keine Gleichverteilung vorliegt (X² Unabhängigkeitstest (nominalskalierte Variable) | Z = Zeilensumme in Kreuztabelle S = Spaltensummen in Kreuztabelle |
| Unabhängigkeitstests bei Messwiederholungen (=Mc-Nemar-X²-Test) | X² = (b-c)²) / (b+c) --> signifikantes Ergebnis = Verhältnis ist deutlich anders |
| Effektgröße bei Nominaldaten | = Omega (Effektgröße) für alle X²-Test -->wie Pearson- Korrelation interpretierbar -keine Mittelwerte & Abstandsmaße berechenbar |
| Teststärke (Power) | = Wahrscheinlichkeit, mit der ein vorhandener Effekt mithilfe eines Testverfahrens identifiziert werden kann = Fläche der Alternativhypothese abzüglich Beta-Fehler --> Power = 1 - β |
| Abhängigkeit der Teststärke | -->vom Beta-Fehler abhängig & dieser hängt von ab... - Alpha-Fehler - Stichprobengröße - Populationseffekt -Teststärke wird größer,wenn man größeren Alpha-Fehler & größere Stichprobe wählt & in d. Population ein größerer Effekt vorhanden ist |
| Festlegung der Teststärke vor der Studie | -zur Berechnung der erforderlichen Stichprobengröße in Abhängigkeit vom Populationseffekt und Alpha-Fehler (letzteren werden konstant gehalten & sind festgelegt, nur Stichprobengröße variiert) -angestrebte Teststärke >0,6 bzw. 60 % |
| Bestimmung der Teststärke nach einer Studie | , ist sinnvoll, um herauszufinden wie wahrscheinlich es war, überhaupt einen Effekt zu finden, der in der Population tatsächlich vorhanden ist (vor allemm wenn kein Effekt gefunden wurde) -Teststärke parametrischer Testverfahen ist stärker |
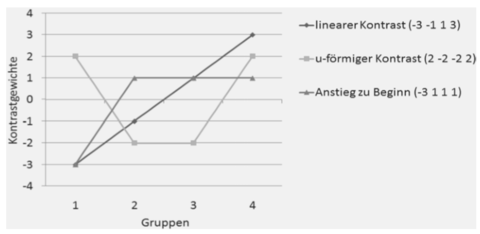
| Kontranstanalyse | = hypothetisches Muster der Mittelwertsunterschiede von Gruppen (z.B. linear, u-förmig...) wird vor der Untersuchung festgelegt & anschließend miz erhobenen Daten verglichen |
| Kontrastgewichte / Lambdagewichte λ | = genau Hypothese wird über das Muster von Mittelwerten durch Kontrastgewichte festgelegt - Muster wird vor der Untersuchung festgelegt - Prüfung nach der Erhebung, ob eine Übereinstimmung vorhanden ist bzw. wie groß die Abweichung ist |
| Vorgehen bei der Kontrastanalyse | -Hypothese definieren - Hypothese mit Kontrastgewichten ausdrücken, Relation (Größe der Gewichte) ist entscheidend--> Summe muss 0 sein -dabei wird für jede Gruppe eine Zahl vergeben, die d. relative Lage zu den anderen Grupen angibt - Datenerhebung - Zuweisung & Überprüfung der Kovaration von Lambdagewichten zum Mittelwert - Übereinstimmung von Mittelwerten & Lamdagewichten = signifikantes Ergebnis |
| Mögliche Darstellung von Kontrasten und Kontrastgewichte | |
| Kontrastanalyse bei unabhängigen Stichproben | - Varianz durch Kontrast ist max., wenn beide Muster (von Lamdagewichten & Gruppenmittelwerten) identisch sind |
| F-Wert und Freiheitsgrade bei Kontrastanalyse bei unabhängigen Stichproben | - F-Wert wird ebenso interpretiert wie herkömmlicher F-Wert - kann mittels der F-Tabelle auf Signifikanz geprüft werden - Freiheitsgrade = 1 (da nur ein Kontrast getestet wird) |
| Vorteile der Kontrastanalyse | - größere Teststärke (weil Muster von Mittelwertsunterschieden geprüft werden) - bei Zutreffen der Hypothese liefert Kontrastanalyse größeren F-Wert als Varianzanalyse --> Hypothesen müssen präzise formuliert werden -Lamdagewichte können präziser verhersagen, wie groß ein Mittelwert sein soll - sehr gut interpretierbare Effektgrößen |
| Effektgröße bei Kontrastanalyse für unabhängige Stichproben | = Korrelation r (effect size) - Interpretation wie Pearson-Korrelation - F (ANOVA) = normale F-Wert Berechnung |
| einfachere Rechnung von r (effect size) | - jeder Person das entsprechende Lambdagewicht zuordnen - Lambdagewicht mit Rohdaten korrelieren |
| Kontrastanalyse für abhängige Stichproben | - Muster für Varianz der Werte der einzelnen Personen über Messzeitpunkte - Vorgehen identisch mit unabhängige Prüfung, bis: Prüfen ob entsprechender Verlauf von Lambda bei jeder Person vorliegt --> liegt im Durchschnitt aller Personen der Trend vor |
| L-Wert | = sagt aus, ob das gemessene Muster mit dem unterstellten Muster (Kontrast) bei jeder Person übereinstimmt - L-Wert ist groß, wenn Übereinstimmung vorhanden--> wenn nicht, dann ist der L-Wert klein o. sogar negatv - wird für jede Person berechnet |
| L-Wert auf Signifikanz prüfen | - Unterscheidet sich der durchschnittliche L-Wert signifikant von 0 --> Prüfung durch t-Test -Mittelwert alller L-Werte L_ wird an d. Streuung d- L-Werte relativiert -T-Werte=signifikant: Effekt d. Messwiederholung steht mit fokusierter Hypothese im Einklang |
| Effektgröße bei der Kontrastanalyse für abhängige Stichproben | -Hedge berechnet, ob der Durchschnitt der L-Werte sich von 0 unterscheidet -g kann aus Ergebnis d. t-Tests berechnet werden |
| Berechnung bei der Metaanalyse (Unterschiedsfragestellung) | Unterschiedliche Werte der Studien auf eine gemeinsame Effektgröße bringen (Effekte versch. Studien vergleichbar machen) -für alle Effektgrößen (di) bestimmen & deren Mittelwert d- -n= Anzahl Studien |
| vertrauenserhöhende Dinge bei der Metaanalyse sind | - sehr viele Studien sind in die Analyse miteingeflossen - die einzelnen Studien hatten große Stichproben - Streuung der einzelnen Stichproben ist klein |
| Arten von multivariaten Verfahren | - Faktorenanalyse - Clusteranalyse - Multivariate Varianzanalyse - Multidimensionale Skalierung - Conjoint-Analyse - Strukturgleichungsmodelle |
| Faktorenanalysen | - reduzieren eine Vielzahl von Variablen aufgrund ihrer Korrelation zu wenigen Faktoren (o. Komponente - diese stehen stellvertretend für alle Variablen - es gibt keine UV , da lediglich Korrelaton zwischen Variablen mit gleichem Sachverhhalt gemessen werden - Ablauf: hohe Korrelation zwischen Variablen --> Variablen werden durch Faktor ersetzt (beschreibt alle eingeflossenen Variablen) |
| Clusteranalyse | = Reduktion von Fällen (Objekten, Personen) durch Zusammenfassung in Gruppen - Fälle sind innerhalb einer Gruppe möglichst ähnlich, zwischen den Gruppen möglichst unähnlich - keine UV -Anzahl von Clustern kann beliebig sein |
| Multivariate Varianzanalyse (MANOVA) | = prüft den Effekt einer oder mehrer UV auf mehr als eine AV - Ablauf: Overall-Analyse --> keine Signifikanz = keine weiteren Berechnungen --> Signifikanz = mehrere normale ANOVA für jede AV |
| Multidimensionale Skalierung (MDS) | = Ähnlichkeitsbeurteilung, von Personen für Objekte --> Ableitung: Anzahl und Art der Bewertungsdimensionen - Auffinden der relevanten AV Ablauf: Anzahl der Dimensionen festlegen (2-3) --> wo liegen Objekte in den Dimensionen --> Dimensionen interpretieren |
| Conjoint-Analyse / Verbundanalyse | = prüft den relativen Einfluss eines Merkmals / Merkmalsausprägung zur Bewertung von Objekten durch eine Person - meist durch Präferenzanalyse (z.B. Ratingskala zur Beurtelung von Produkten) |
| Strukturgleichungsmodelle | = Kombination aus Faktorenanalyse und Regressionsanalysen - bilden komplexe Zusammenhänge zwischen (meist latenten) Variablen - dienen der Überprüfung sozialwissenschaftlicher Modelle & Theorien |
| quantitative / konventionelle Methoden | -Phänomene des Erleben und Verhalten in Zahlen ausgedrückt -herkömmliche & am weitesten verbreitet |
| Positivismus | -Phänomene des Erlebens und Verhaltens, die wir beobachten und erforschen -Erleben von Emotion, das Entstehen vn Gedanken & das Steuern von andlungen sollen mithilfe materieller Prozess & Gesetzmäßigkeiten beschreibbar sein -Naturalismus: Mensch ist Teil d. biologischen & physikalischen Natur |
| Qualitative Methoden | Phänomene des Erleben und Verhalten qualitativ bewerten -->stellen subjektive Äußerungen von Menschen in d. Mittelpunkt der Betrachtung - Datengrundlage: Text, analysiert nach übergeordneten Bedeutungen und Sinnstrukturen - im Gegensatz zur quantitativen Methode: keine Zahlen, Skalen und Kennwerte |
| qualitative Forschungsprozess | - mit oder ohne gezielter Fragestellung ; bei gezielter Fragestellung: - Daten sammeln (meist Texte, Bilder) - nach jeweiligen qualitativen Methode auswerten - Daten verwenden oder ggf. erneute Datensammlung |
| explorativer Charakter eines Forschungsprozess | neues inhaltliches Gebiet wird erforscht |
| Besonderheit des qualitativen Forschungsprozess | - der Mensch übernimmt die Auswertung (der Foscher selbst wertet Analyse aus) --> aber: Subjektivität?! |
| Entkräftigung der Subjektivität bei qualitativer Forschung | - läuft nicht beliebig ab, sondern auch nach bestimmten Regeln und mit mehreren Personen (--> stärt Objektivität) -verschiedene Personen kommen bei d Auswertung zum gleichen/ ähnlichen Ergebnis -Unstimmigkeiten zwischen -Auswertungen-->offene Diskussion bis zur Lösung & Protokollierung auch quanti-tative Forschung ist nicht frei von Subjektivität |
| Anwendungsfelder der qualitativen Forschung | - immer abhängig von der Fragestellung - als Ergänzung / Bereichung der quantitativen Methoden bei bestimmten Fragestellungen |
| Methoden der qualitativen Forschung | - qualitative Inhaltsanalyse - Grounded Theory - Diskursanalyse |
| Qualitative Inhaltsanalyse | - folg am ehesten dem herkömmlichen Forschungsprozess; gut kombinierbar mit quantitativen Methoden - relativ konkrete Fragestellung - Datenmaterial: Alle Formen von Texten - Ziel: zusammenfassende Beschreibung des Textmaterials & Auffinden von Strukturen aus dem Text |
| Prozess der qualitativen Inhaltsanalyse | - Erstellen der Texte - Zusammenfassen in Kurztexte - Erstellen von Kategorien, die für die Fragestellung relevant sind (--> theoriegeleitete Inhaltsanalyse=Prüfung von Hypothesen/Theorien) |
| Anwendung von qualitativer Inhaltsanalyse | - bei subjektivem Erleben - Sinnzusammenhänge - Eindrücke - Meinungen welche nicht quantitativ erfasst werden können |
| Grounded Theory | - strukturierte & differenzierter qualitativer Ansatz - keine Fragestellung gegeben --> neue Theorien / Hypothesen finden - Datengrundlage: Alle Formen von Texten - alles wird immer protokolliert, um nachvollziehen zu können, warum der Forscher diese Schlüsse gezogen hat |
| Codieren bei der Grounded Theory | - zeilenweises Codieren (--> größtmögliche Objektivität) - fokussiertes Codieren (kleine Bedeutungseinheiten aus dem zeilenweisen Codieren werden zu Kategorien zusammengefasst) |
| theoretical sampling (Grounded Theory) = theoriegeleitetes Ziehen von weiteren Probanden oder Stichproben | - wenn nach allen analysierten Interviews noch Infos fehlen / Unklarheiten bestehen --> weitere Interviews werden geführt mit Personen bei denen man glaubt, dass diese die Antworten liefern könnten. - wird so lange gemacht, bis alle offenen Fragen beseitigt wurden |
| Anwendung der Grounded Theory | - Sachverhalte des subjektiven Erlebens, welche neu erforscht werden |
| Diskursanalyse | - Analyse des Konstruktivismus - Datenmaterial: alle Arten von aufgezeichneter Sprache - Ziel: Beantwortung bestimmter Fragestellungen (praktisches Problem oder theoretische Frage) |
| Prozess der Diskursanalyse | - Text lesen --> Codierung auf Relevanz für Ausgangsfrage --> Zentrale Aussagen suchen (auch zwischen den Zeilen lesen, z.B. Grammatik, Metapher...) Ziel: Auffinden übergeordneter Muster oder Vorstellungen, die in der Denkweise des Verfassers verankert sind |
| Vor- und Nachteile der qualitativen Methoden | + größere Flexibilität --> unvoreingenommen für Thema & keine Themen übersehen möchte + einbeziehen des Kontext & zusätzlicher Infos (nonverbale Gesten & sprachliche Äußerungen) - ungenau und objektiv nicht mehr nachvollziehbarer Umgang mit Daten, Einfluss der Subjektivität zu hoch |
| Schwierigkeiten der qualitativen Forschung | - kaum konkrete Handlungsanweisungen - sehr großer Aufwand für ein / mehrere Forscher --> Kombination aus qualitativer und quantitativer Forschung sinnvoll |
| Erläuterung Gesamtvarianz & Varianz der Mittelwerte | -Gesamtvarianz (Varianz d. AV)= Unterscheidung d. Messwerte aller Personen -1. Erklärung:Manipulation -->verschiedene Verkehrsmittel =UV -3 Differezen zwischen den Mittelwerten(Gruppe 1 & 2, 2 & 3, 1 &3), deshalb Varianz d. Mittelwerte genannte |
| Varianz zwischen den Gruppen oder Beetween-Varianz genannt, da | die Varianz durch die unterschiedliche Manipulation zwischen den Gruppen hervorgerunfen |
| Erläuterung Gesamtvarianz & Varianz innerhalb der Gruppe | -zweite Erklärung für Gesamtvarianz: Messwerte variiren nnerhalb einer jeden Gruppe-->Grund: Varianz innerhalb der Gruppen /Within- Varianz (repräsentiert Teil d. Varianz, auch systematische Varianz genannt) |
| Varianz innerhalb der Gruppen oder Within-Varianz genannt, da | - Menschen unterscheiden sich in d. Ausprägung von Merkmalen & nicht selben Messwert liefern -außerdem gibt es Messfehler bei Within-Varianz-->zufälliger Teil d. Varianz nicht erklärbar -dieser stellt fehler da & schärnkt Aussagekraft d. Mittelwerte ein -->Fehlervarianz /unsystematische Varianz genannt |
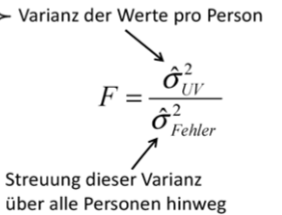
| Verhältnis der Prüfgröße F F= Ô²zw / Ô²inn -->Quadratsummen durch die entsprechenden Freiheitsgrade teilen | -Prüfgröße F =repräsentiert Vaarianz von Mittelwerten Je kleiner Fehlervarianz (inn=Varianz innerhalb d. Gruppe) bzw. je größer d. Varanz d. Mittelwerte (zw=Varianz zwischen d. Gruppen), desto größer wird . Wert F. |
| Effektgröße bei Kontrastanalyse für unabhängige Stichproben im Detail | -werden aus d. Ergebnis d. F-Tests bestimmt --> neben F Kontrast wird d. normale F-Wert benötigt (durch ANOVA bestimmt) -als Effektgröße= Korrelation r verwendet ->prüft, wie gut das Muster d. Lamdagewichte mit Muster emprisischer Mittelwerte übereinstimmt - bei d. Kontrastanalyse wird Korrelation als r effect size bezeichnet -->Interpretation erfolgt wie bei Pearson Korrelation |
| Metaanalyse Definiton | -Effekte einer Vielzahl von empirischen Studien zum selben Thema werden zusammengefasst -der daraus resultierende mittlere Effekt ist eine wensentlih bessere Schätzung für d. wahren Effekt in d. Population als ein einzelner Wert aus einer Studie |
| Multivariate Analyseverfahren | -untersuchen mehr als eine abhänige Variable die Anzahl der abhängigen Variablen kann dabei unterschiedlich groß sein |
| Memos bei der Grounded Theory | =Aufzeichnungen, Notizen, Einfälle, Gedanken aller Art, die Forscher während der Analyse sammelt -zentral Rolle bei Textanalyse & Zusammenfassung d. Ergebnisse -enthalten erste Ideen & Hypothesen über grundlegende Zusammenhänge & Strukturen -beziehen sich auf einzelne Textstellen, ganze o. mehrere Interviews |
| Beispiele für Anwendung der Grounded Theory | -Erforschung neuer inhaltlicher Gebiete, wozu wenig Infos vorhanden sind & umfasst Sachverhalte des subjektiven Erlebens -Verarbeiten bestimmter Krankheiten -Umgang mit neuen Phänomenen (Computer bei älteren Menschen) -Erleben & Verareiten von Stress am Arbeitsplatz |
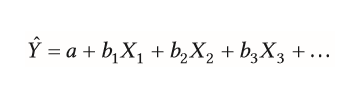{kind=link}
{kind=link}
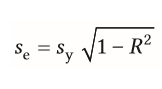{kind=link}
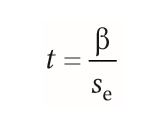{kind=link}
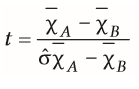{kind=link}
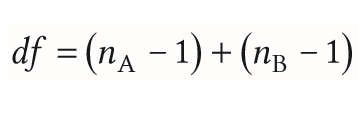{kind=link}
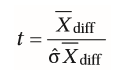{kind=link}
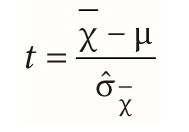{kind=link}
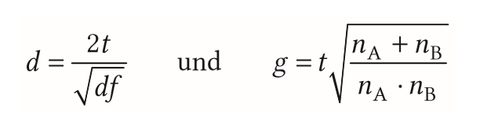{kind=link}
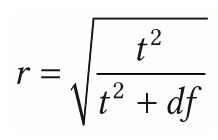{kind=link}
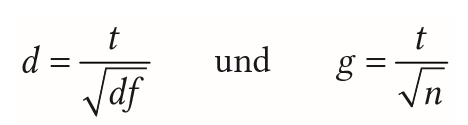{kind=link}
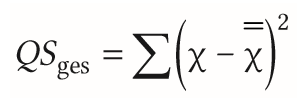{kind=link}
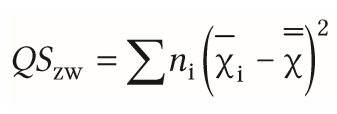{kind=link}
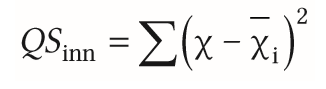{kind=link}
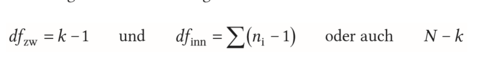{kind=link}
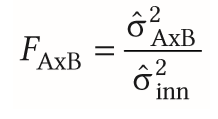{kind=link}
{kind=link}
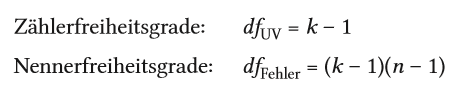{kind=link}
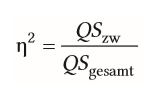{kind=link}
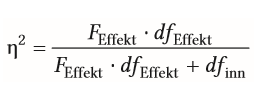{kind=link}
{kind=link}
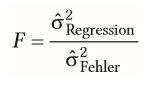{kind=link}
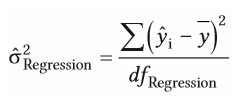{kind=link}
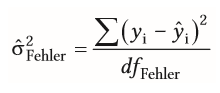{kind=link}
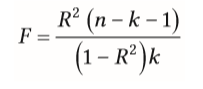{kind=link}
{kind=link}
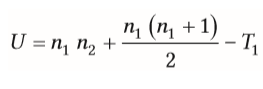{kind=link}
{kind=link}
{kind=link}
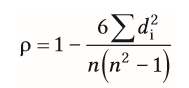{kind=link}
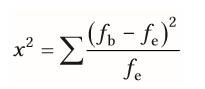{kind=link}
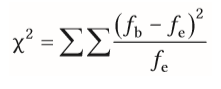{kind=link}
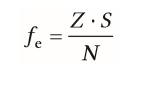{kind=link}
{kind=link}
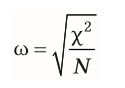{kind=link}
{kind=link}
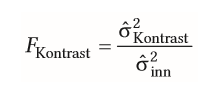{kind=link}
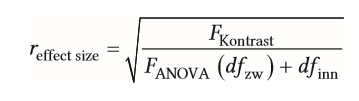{kind=link}
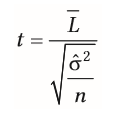{kind=link}
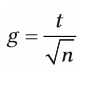{kind=link}
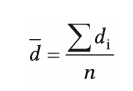{kind=link}
Want to create your own Flashcards for free with GoConqr? Learn more.