6003643
| Pregunta | Respuesta |
| Ziel der Inferenzstatistik | Schlüsse von einer Stichprobe auf Population zu ziehen sowie Aussagen über die Güte der Schlüsse |
| wie kann man sicherstellen, dass Ergebnis einer Stichprobe auf Population verallgemeinert werden kann | - Metaanalysen - Berücksichtigung der Wahrscheinlichkeit, dass die Bestimmung des Ergebnis aus der Stichprobe falsch ist |
| Stichprobenverteilung | = Streuung der Mittelwerte aus einzelnen Stichprobe = zeigt, mit welcher Wahrscheinlichkeit ein Ergebnis erwartet werden kann |
| Unterschiede der Stichprobenverteilung zur Häufigkeitsverteilung | - Werte der Verteilung müssen nicht der Skala entsprechend (da sie Mittelwerte sind) - Y-Achse: Anzahl der Stichproben / Wahrscheinlichkeit - Werte in der Mitte kommen häufigst vor (da Mittelwerte der Studien), Randwerte eher selten |
| theoretische Stichprobenverteilung | = Verteilung aufgrund Ergebnisse einer Stichprobe --> durch deren Kennwerte wird die Stichprobenverteilung am PC simuliert |
| zentraler Grenzwert | = Verteilung einer großen Anzahl von Stichproben folgt immer der Normalverteilung |
| Vorteil von steigender Stichprobengröße | Streuung der Stichprobenverteilung sinkt |
| Kennwerte von Stichprobenergebnisse der Inferenzstatistik | - Kennwerte der Lage und Streuung (Mittelwert) - Kennwerte bzgl. Unterschied zwischen Gruppen (Mittelwertsunterschiede) - Kennwerte, die Zusammenhang zwischen Variablen beschreiben (Korrelation) |
| Standardfehler s(e) | = Standardfehler des Mittelwertes = Standard-abweichung der Stichprobenverteilung = durchschnittlicher Unterschied zwischen den geschätzten Mittelwert einzelner Stichproben und dem tatsächlichen Mittelwert |
| Populationsstreuung | = Formel für SD in der Population = exaktere Schätzung als mit der Formel für den Standardfehler |
| Konfidenzintervalle / Vertrauensintervalle | = Wertebereich, bei dem wir darauf vertrauen, dass sich der wahre Wert in der Population mit der Vertrauenswahrscheinlichkeit deckt |
| Vertrauenswahrscheinlichkeit | = gewünschte Güte des Intervalls |
| Konstruktion des Konfidenzintervall | 1. Vertrauenswahrscheinlichkeit festlegen 2. Stichprobe und Mittelwert erheben 3. Stichprobenverteilung konstruieren 4. Fläche der Vertrauenswahrscheinlichkeit markieren 5. Werte die über und unter der Fläche von 4. werden abgeschnitten |
| Festlegung der Vertrauenswahrscheinlichkeit | - Vertrauenswahrscheinlichkeit kann beliebig festgelegt werden, sollte aber nicht zu hoch sein, da sonst die Aussage ihren Wert verliert Normal: 90, 95, selten 99 % |
| Vorteil des Konfidenzintervalls | - Wahrscheinlichkeit der Güte einer Schätzung ist vorstellbar Aber: nur Aussage über die Wahrscheinlichkeit der Korrektheit des Intervalls möglich |
| Alternative Möglichkeit zur Erstellung der Konfidenzintervalle | - große Stichprobe (ab 30 P.): Standardnormalverteilung - kleine Stichprobe: t-Verteilung |
| t-Verteilung | - Mittelwert 0 - Streuung 1 - Form ist abhängig von der Stichprobengröße - symmetrische Verteilung |
| Notwendige Werte für die t-Verteilung | - Freiheitsgrade |
| Freiheitsgrade (df) | = Werte, die in einem statistischen Ausdruck frei variieren können |
| Berechnung der oberen und unteren Grenze des Konfidenzintervalls mittels der t-Verteilung bei Mittelwerten | |
| Vorteil von größeren Stichproben bei Konfidenzintervallen | - informativer Aussage, da die Grenzen des Intervalls näher zusammen rücken |
| Standardfehler bei Anteilen | 1. Stichprobenverteilung bestimmen --> Binomialverteilung (bei zwei Ausprägungen) 2. Standardabweichung bestimmen (definiert durch n und Wahrscheinlichkeit p) |
| Risiken bei Hypothesentesten | - Verallgemeinerung auf die Population - Effekte entstanden durch Zufall -> nicht übertragbar auf Population |
| vertrauensvolle Verallgemeinerung | - Berechnung von Standardfehler - Berechnung von Konfidenzintervallen - Durchführung von Signifikanztests |
| Abhängige Messungen | - Messwiederholungen: within-subject-design: Personen durchlaufen beide Tests - gepaarte Stichproben: matching: Versuchsgruppen werden konstant gehalten, d.h. vergleichbare Personen in Gruppe 1 und 2 |
| unabhängige Messungen | = jede Messung wird in jeweiliger Stichprobe vorgenommen - Between-subject-Design: Teilnehmer werden randomisiert und so den verschiedenen Versuchsgruppen zugeordnet |
| Art der Messung bei Zusammenhangshypothesen | abhängige Messung --> es müssen beide Variablen an beiden Gruppen untersucht werden um Messwerte beiden Variablen zuordnen zu können und Streudiagramm erstellen zu können |
| Standardfehler - s(e) - bei Hypothesentesten (Zusammenhänge & Unterschiede) | ist nicht alleine aussagekräftig! Zusätzlich noch Konfidenzintervall und Signifikanztest weil: es geht um Entscheidungen treffen, und da ist s(e) alleine nicht ausreichend |
| Standardfehler für Mittelwertsunterschiede bei unabhängigen Messungen | = berechnet aus der Streuung der einzelnen Stichproben Berücksichtigt werden muss die Streuung jeder Stichprobe |
| Gesamtstreuung (Standardfehler für Mittelwertsunterschied bei unabhängigen Messungen) | = Fehlerstreuung + systematische Streuung |
| Fehlerstreuung (Standardfehler für Mittelwertsunterschied bei unabhängigen Messungen) | = Streuung ohne erkennbaren / systematischen Grund, die die Messwerte variieren lässt --> schmälert Bedeutsamkeit des gefundenen Effekts (bei großer Fehlerstreuung kann Mittelwertsunterschied auch zufällig entstanden sein) = Streuung innerhalb der Gruppe |
| systematische Streuung (Standardfehler für Mittelwertsunterschied bei unabhängigen Messungen) | = Streuung zwischen den Gruppen = ergibt sich durch den Mittelwertsunterschied = interessanter Effekt |
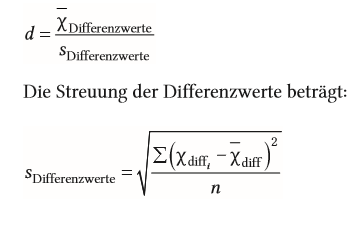
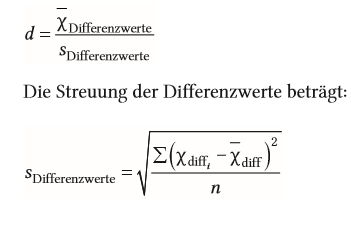
| Standardfehler für Mittelwertsunterschiede bei abhängigen Messungen | Differenz der Messwerte relevant = Streuung innerhalb der Person --> Durchschnitt aller Differenzen über alle Personen hinaus Differenz ist entscheidend |
| Streuung der Differenz (Standardfehler für Mittelwertsunterschiede bei abhängigen Messungen) | |
| Fehlerstreuung (Standardfehler für Mittelwertsunterschiede bei abhängigen Messungen) | besteht nur in der Streuung der Differenz --> Differenzen sollten gleich groß und gleiche Richtung haben. wenn nicht: Vergrößerung der Fehlervarianz --> gefundener Effekt weniger bedeutsam |
| Korrelationskoeffizient bei Zusammenhänge | beschreibt die Enge des Zusammenhangs (r = groß --> Streuung klein) |
| Standardfehler für Korrelationskoeffizient bei Zusammenhänge | r nahe 1 /-1 führt zu Standardfehler nahe 0 |
| Regressionsgewicht | = beschreibt den relativen Einfluss einer Variable auf die andere = beschreibt den Anstieg der Regressionsgeraden aus einzelnem Regressionsgewicht kann nicht die Güte abgeleitet werden |
| Standardschätzfehler bei der Regression | wie stark streuen die Werte um die Regressionsgrade - beschreibt Ungenauigkeit wenn man Y-Werte aus X-Werte mithilfe der Regressiongeraden schätzt = Gütemaß für die Vorhersage |
| Berechnung des Standardfehler aus dem Regressionskoeffizienten (also aus dem Standardschätzfehler) | Bezeichnung: SE |
| Vorteile von Konfidenzintervalle | - leicht verständliche Angabe, ob Effekt durch Zufall entstand oder statistischer Bedeutung hat |
| Konfidenzintervalle für Mittelwertsunterschiede bei unabhängigen Stichproben | - Verwendung der Stichprobenverteilung von Mittelwertsunterschieden oder die t-Verteilung |
| Der Wert 0 beim Konfidenzintervall für Mittelwertsunterschiede bei unabhängigen Stichproben | es gibt keinen Mittelwertsunterschied in der Population --> Hypothese verwerfen Gründe: - zu hohe Vertrauenswahrscheinlichkeit - Mittelwert nahe 0 (je kleiner der Effekt desto eher wird 0 Bestandteil des Konfidenzintervalls sein) |
| Konfidenzintervall für Mittelwertsunterschiede bei abhängigen Stichproben | Andere Formel, gleiche Interpretation wie bei unabhängigen Stichproben |
| Besonderheit des Korrelationskoeffizient bei Zusammenhänge | t-Verteilung ist nur symmetrisch, wenn r=0 --> r > 0 -> t-Verteilung unbrauchbar, da unsymmetrische Darstellung --> Nutzung der z-Verteilung |
| Konfidenzintervalle für Korrelationskoeffizienten bei Zusammenhänge | werden meist nicht berechnet, wenn über z-Verteilung Ablauf: Korrelationskoeffizient in z-Wert umrechnen -> kritischer Wert für Intervallgrenzen ablesen --> Grenzen berechnen (siehe Formel) --> Umrechnung auf Korrelationskoeffizient |
| Berechnung des Konfidenzintervall für Regressionsgewicht β bei unsymmetrischer Verteilung | |
| Signifikanztests | Entscheidungshilfe bei Hypothesen es werden Hypothesen gegeneinander getestet lässt keine Aussage über Wahrscheinlichkeit einer Hypothese zu! |
| Grundlage der Signifikanztests | Stichprobenverteilungen (Verteilungen, die aus theoretischen Überlegungen erwachsen) |
| Nullhypothese (H0) | = Forschungshypothese = behauptet es gibt keinen Effekt in der Population Gegenteil: Alternativhypothese (H1) --> Achtung bei Berechnung und Interpretation |
| Stichprobenverteilung bei der Nullhypothese | Mittelwert = 0 |
| p-Wert | = Wahrscheinlichkeit des gefundenen Effekts unter der Annahme dass die Nullhypothese gilt |
| Irrtumswahrscheinlichkeit α / Signifikanzniveau / Alpha-Niveau | = entspricht Wert bei p, ab dem man die Nullhypothese nicht mehr akzeptiert - kleinere Werte = signifikant -> Ablehnung der Nullhypothese |
| Alpha-Fehler | = legt das Niveau der Irrtumswahrscheinlichkeit fest = Risiko die Nullhypothese fälschlicherweise abzulehnen p < α Ergebnis ist signifikant = Ablehnung der Nullhypothese |
| "Entstehung" des p-Wertes | t-Werte der Stichprobe = Mittelwert = 0 --> entspricht Verteilung der Nullhypothese --> p-Wert aus Verteilung ablesen |
| Prüfverteilungen | - z-Verteilung (ist einzelner Wert signifikant) - t-Verteilung (bei Mittelwertsunterschieden, Korrelationskoeffizienten und Regressionsgewichten) |
| einseitige Tests | = Hypothese geht nur in eine Richtung - Effekt ist auf der rechten Seite der Nullhypothese zu finden schließen Alpha-Fehler auf der linken Seite aus --> müssen keinen Signifikanztest machen, wenn Kontrollgruppe höhere Werte erzielt, da Hypothese bereits widerlegt ist |
| zweiseitige Tests | = Richtung des Effekts ist unbekannt - Effekt kann auf beiden Seiten der t-Verteilung liegen --> Alpha-Fehler muss auf beide Seiten gleich aufgeteilt werden, dadurch wird es schwerer ein signifikantes Ergebnis zu erzielen |
| Alternativhypothese | = unterscheidet sich um die Größe des erwarteten Effekts von H0 |
| Verteilung der Alternativhypothese | theoretische Verteilung bestimmbar durch: - Größe des interessanten Mindesteffekts - Effekte aus bereits durchgeführten Studien Überschneidung mit H0 |
| Fehler erster Art | = Alpha-Fehler Nullhypothese wird fälschlicherweise verworfen / in der Population gilt H0 Interessante Teil der Verteilung: rechter Überschneidungsbereich |
| Fehler zweiter Art | = Beta-Fehler Alternativhypothese wird fälschlicherweise abgelehnt / in der Population gilt H1 Interessante Teil der Verteilung: linker Überschneidungsbereich |
| Abwägung von Alpha- und Beta-Fehler | Abhängig von der Fragestellung, relevant wenn Verteilungen sich stark überschneiden |
| Minimierung der Alpha- und Beta-Fehler | - Effekt in der Population ist groß - größere Stichprobe -> Verteilung wird schmaler, geringe Überlappung |
| Ablauf der Signifikanztest unter Berücksichtigung der Alternativhypothese | |
| Hybrid-Vorgehensweise | = Alternativhypothese und Abwägung der Fehler erster und zweiter Art wird nicht gemacht wenn Ergebnis nicht signifikant -> H0 stimmt |
| Einflussgrößen auf Signifikanztests | - Größe des Populationseffekts - Stichprobengröße - Alpha-Niveau |
| Kritik an Signifikanztests | - die Größe eines Effektes in der Population kann nicht geschätzt werden --> inhaltliche Bedeutung ebenfalls nicht erkennbar - |
| Zusätzlich notwendige Angaben zu Signifikanztests | - Konfidenzintervalle - Effektgrößen |
| Effektgröße | = standardisierte Effekte, welche die Stichprobengröße berücksichtigen --> sind über Stichproben und Themenbereiche hinweg vergleichbar |
| Möglichkeiten der Berechnung der Effektgrößen | - aus Rohdaten - aus anderen Effektgrößen - aus Signifikanztestergebnissen |
| Effektgrößen aus Rohdaten | - bei unabhängigen Messungen - bei abhängigen Messungen - für Zusammenhänge (Korrelationskoeffizient) |
| Abstandsmaß d (bei unabhängigen Messungen) | repräsentieren den Abstand der Mittelwerte --> Effektgröße erhöht sich, wenn Streuung kleiner wird |
| Streuung für Abstandsmaß nach Cohens (bei unabhängigen Messungen) | Stichproben-streuung |
| Alternative zum Abstandsmaß (bei unabhängigen Messungen) | = Hedges' (g) aus Populationsstreuung liefert exaktere Schätzungen als d |
| Berechnung von Hedges bei unabhängigen Messungen | Populationsstreuung bestimmen |
| Abstandsmaß d bei abhängigen Messungen | |
| Hedges g bei abhängigen Messungen | |
| Überführung Unterschieds- und Zusammenhangsfragen bei Effektgrößen | n = ist Gesamtstichprobe Freiheitsgrade = n - k (Anzahl der Gruppen) |
| Berechnung Korrelation aus Abstandsmaßen | nur bei gleicher Stichprobengröße |
| Berechnung Abstandsmaße aus Korrelation | |
| Effektgröße aus Signifikanztestergebnissen | Signifikanztestergebnis = Prüfgröße Größe der Studie = mithilfe der Freiheitsgrade |
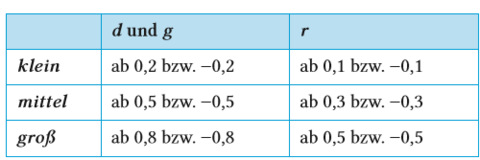
| Interpretation von Effektgrößen | - Abhängig von der Fragestellung - Anwendung von Konventionen |
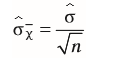{kind=link}
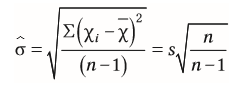{kind=link}
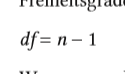{kind=link}
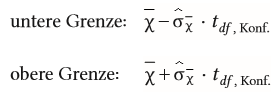{kind=link}
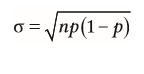{kind=link}
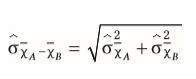{kind=link}
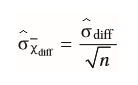{kind=link}
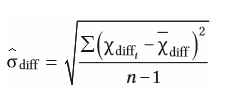{kind=link}
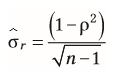{kind=link}
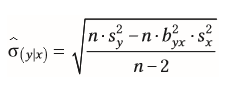{kind=link}
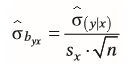{kind=link}
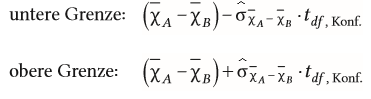{kind=link}
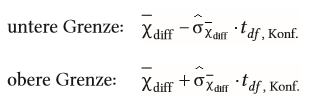{kind=link}
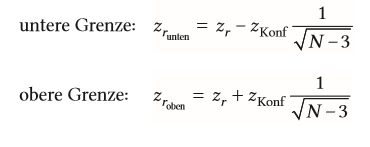{kind=link}
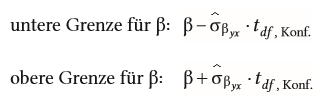{kind=link}
{kind=link}
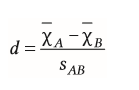{kind=link}
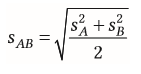{kind=link}
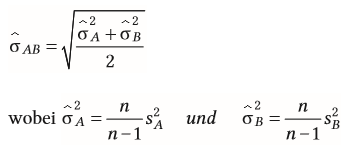{kind=link}
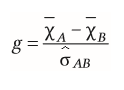{kind=link}
{kind=link}
{kind=link}
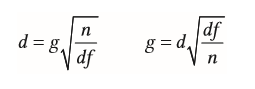{kind=link}
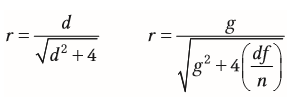{kind=link}
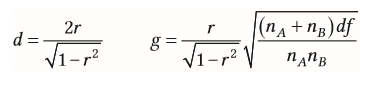{kind=link}
{kind=link}
{kind=link}
¿Quieres crear tus propias Fichas gratiscon GoConqr? Más información.