521756
Beschreibung
Karteikarten von heidi.depner, aktualisiert more than 1 year ago
|
|
Erstellt von heidi.depner
vor fast 11 Jahre
|
|
| Frage | Antworten |
| F14 Was ist eine Theorie? | - Sammlung von Ideen und Annahmen - schlägt eine vorläufige Antwort auf eine gestellte Frage vor. - sie macht Aussagen über Zusammenhänge und Ursache- Wirkungsbeziehungen - sie lässt sich jedoch kaum in ihrem vollen Umfang prüfen |
| F14 Was ist eine Hypothese? | - aus der Theorie abgeleitete Vorhersage - sind weniger umfangeich als Theorien. - haben die Form konkreter Aussagen - lassen sich überprüfen - sollten bestätigt werden können |
| F19 Nenne die Gütemerkmale von Hypothesen | 1. Verankerung in der Wissenschaft 2. Testbarkeit und Falsifizierbarkeit 3. Präzisierbarkeit 4. Morgan´s Canon bzw. Occam´s Razor |
| F19 Beschreibe das Gütemerkmal 1 von Hypothesen "Verankerung in der Wissenschaft" | Die Hypothesen wurden nach Lektüre der einschlägigen Fachliteratur aufgestellt und in deren Kontext eingeführt |
| F19 Beschreibe das Gütemerkmal 2 von Hypothesen "Testbarkeit und Falsifizierbarkeit" | Nur wenn eine Hypothese wissenschaftlich überprüft und falsifiziert werden kann, trägt sie zum Erkenntnisgewinn bei. Dieses Gütekriterium gilt als die eigentliche VORAUSSETZUNG für jegliche wissenschaftliche Relevant einer Hypothese |
| F19 Beschreibe das Gütemerkmal 3 von Hypothesen "Präzisierbarkeit" | Je präzser und informationsreicher Hypothesen formuliert sind, desto günstiger sind die Voraussetzungen für ihre Falsifikation. |
| F19 Beschreibe das Gütemerkmal 4 von Hypothesen "Morgan´s Canon bzw. Occam´s Razor" | Bei sonst gleichem Voraussagewert sind einfachere Grundlagen solchen vorzuziehen, die eine komplizierte und damit oft auch wohl spekulativere Basis der Hypothesenbildung zur Voraussetzung haben. M.C. = besagt, daß eine Handlung niemals als Ausdruck höheren psychischen Vermögens verstanden werden darf, wenn sie auch als Ergebnis der Tätigkeit eines rangniedrigeren psychischen Vermögens (z.B. eines Instinkts oder einer einfach gelernten Gewohnheit) interpretiert werden kann. |
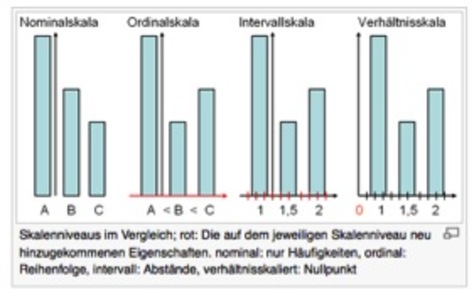
| F26 Skalenniveau |
Image:
Unbenannt (image/jpg)
|
| F26 Skalenniveau - Nominalskala - | - Unterschiede zwischen den Ausprägungen sind rein nominell - Ausprägungen haben keine unterschiedlichen Wertigkeiten - Bsp. Blutgruppen, Trikotnummern, Haarfarbe, Geschlecht - „VERSCHIEDENHEIT“ -kategorial |
| F26 Skalenniveau - Ordinalskala - | - Ausprägungen werden hinsichtlich ihrer Wertigkeit in eine Rangfolge gebracht - die Abstände zwischen den Rängen sind nicht definiert - Bsp. Podiumsplätze, Sterne für Hotel-Kategorie, Schulnoten, Tabellenplatz - „VERSCHIEDENHEIT & RANGORDNUNG“ - kategorial |
| F26 Skalenniveau - Intervallskala - | - Intervalle zwischen den einzelnen Abstufungen sind gleichmäßig verteilt - „VERSCHIEDENHEIT & RANGORDNUNG & DIFFERENZEN“ - metrisch - Nullpunkt ist willkürlich gesetzt - Bsp. IQ, Zeitrechnung |
| F26 Skalenniveau - Verhältnisskala - | - wie Intervallskala, ABER: - absoluter Nullpunkt ist gegeben Bsp. Körpergröße, Alter - VERSCHIEDENHEIT & RANGORDNUNG & DIFFERENZEN & VERHÄLTNISSE“ - metrisch |
| F32 Objektivität, Reliabilität und Validität - Allgemein - | Reliabilität, Validität und Objektivitä sind entscheidende Aspekte für wissenschaftliche Aussagen, da sie die Basis für zuverlässige, verwertbare und eindeutige Auswertungen sind. |
| F32 Reliabilität | Die Reliabilität ist die Zuverlässigkeit einer Messung, d.h. die Angabe, ob ein Messergebnis bei einem erneuten Versuch bzw. einer erneuten Befragung unter den gleichen Umständen stabil ist. |
| F32 Validität | Die Validität gibt die Eignung eines Messverfahrens oder einer Frage bezüglich ihrer Zielsetzung an. Eine Messung oder Befragung ist valide, wenn die erhobenen Werte geeignete Kennzahlen für die zu untersuchende Fragestellung liefern. |
| F32 Objektivität | Die Objektivität von Fragen oder Messverfahren ist gegeben, wenn die Antworten bzw. Messwerte unabhängig vom Interviewer bzw. Prüfer sind. |
| F36 Korrelation | - Die Korrelation ist eine Beziehung zwischen zwei oder mehr Ereignissen - Es gibt positive und negative Korrelationen. - Beispiel positive Korrelation (je mehr desto mehr): Je mehr Futter desto dickere Kühe. - Beispiel negative Korrelation (je mehr desto weniger): Je mehr Verkauf von Regenschirmen desto weniger Verkauf von Sonnencreme. - Die Korrelation beschreibt nicht unbedingt eine Ursache-Wirkungs-Beziehung: - Beispiele für Korrelationen ohne Kausalzusammenhang (Scheinkorrelation): • Anzahl von Störchen und der Geburtenrate. • Einkommen und Schuhgröße • Anzahl der Feuerwehrleute bei einem Brand und Größe des Schadens - Ziel ist es, zu prüfen, ob sich der Wert einer Variable erhöht, sinkt oder gleich bleibt, wenn sich gleichzeitig der Wert einer anderen Variable erhöht. - Dieser Zusammenhang wird dargestellt durch die Produkt-Moment-Korrelation (Pearson‘s r) - Die Werte liegen zwischen -1 (negativer Zusammenhang) und 1 (positiver Zusammenhang). |
| F58 Maße der Zentralen Tendenz - Arithmethisches Mittel - | •(= Mittelwert/ Durchschnittswert) Wenn wir von Durchschnitt sprechen, meinen wir i.d.R. das arithm. Mittel • Wird berechnet aus der Summe aller Einzelwerte geteilt durch die Anzahl der Werte • Verwendbar ab intervallskalierten Daten • Ausreißer werden auch berücksichtigt und verfälschen eventuell den Durchschnittswert |
| F59 Maße der Zentralen Tendenz - Median - | „Vogelgewicht“ ROBUSTHEIT Beschreibt den mittleren Wert einer Verteilung (bei ungeradem n) Bei geradem n werden die beiden mittleren Werte genommen und das arithmetische Mittel aus ihnen gebildet. Verwendbar ab ordinalskalierten Daten. → Das arithmetische Mittel wird durch jeden Wert der Verteilung beeinflusst (insb. durch Extremwerte). Der Median hingegen ist relativ robust. |
| F67 - Varianz | Die Varianz ist die durchschnittliche quadrierte Abweichung zwischen dem Mittelwert und den gemessenen Werten. Die durchschnittliche Abweichung für die Population berechnet man durch Dividieren der Summe der quadrierten Abweichungen durch (n-1). Das Quadrat der Ursprungseinheiten (z.B. Stück oder Knöpfe) ist schwer zu interpretieren! In der Praxis wir eher die Standardabweichung herangezogen Eine kleine Standardabweichung (in Relation zum Mittelwert) indiziert, dass die gemessenen Werte nahe dem Mittelwert liegen. Eine große Standardabweichung (in Relation zum Mittelwert) indiziert dagegen, dass die gemessenen Werte weit um den Mittelwert streuen. |
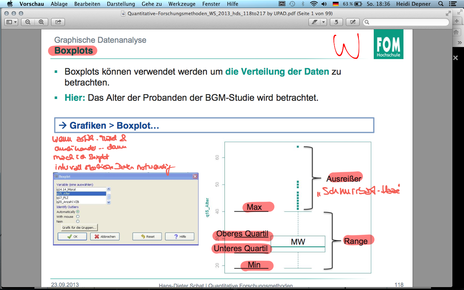
| F118 Boxplots | |
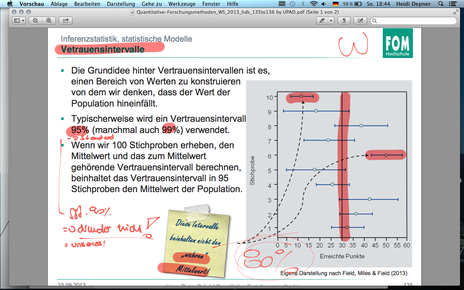
| F131 Standardfehler | - werden mehrere Stichproben aus einer Population gezogen, variieren die Ergebnisse leicht. Es muss also geprüft werden, wie gut die jeweilige Stichprobe die Population repräsentiert. Hierzu wird der Standardfehler genutzt. - Der Standardfehler ist die Standardabweichung der Stichprobenmittelwerte. |
| F131 kleiner Standardfehler | - Ein kleiner Standardfehler (im Vergleich zum Stichprobenmittelwert) bedeutet, dass die Mittelwerte der verschiedenen Stichproben nur gering variieren. Die gezogene Stichprobe ist somit wahrscheinlich repräsentativ für die Population. |
| F131 großer Standardfehler | Ein großer Standardfehler (im Vgl. zum Stichprobenmittelwert) bedeutet, dass die Mittelwerte der verschiedenen Stichproben stark variieren. Die gezogene Stichprobe könnte somit nicht repräsentativ für die Population sein. |
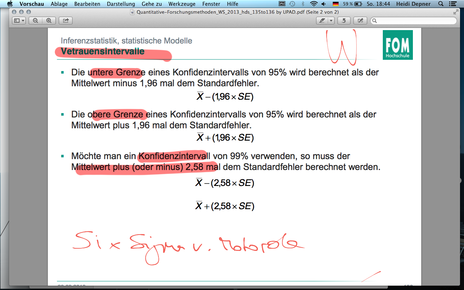
| F135 - Vertrauensintervalle 1/2 | |
| F135 - Vertrauensintervalle 2/2 | |
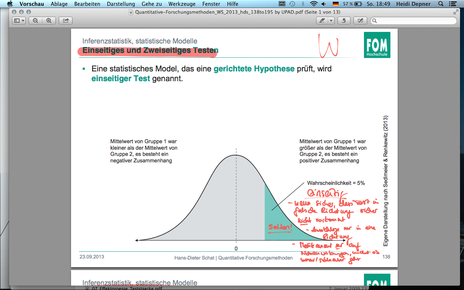
| F138 Einseitiges und Zweiseitiges Testen | |
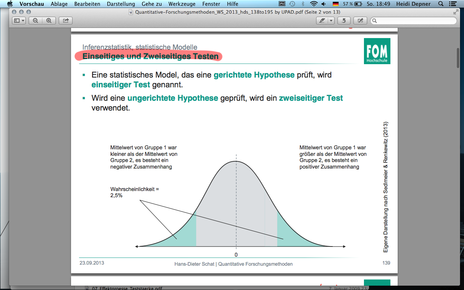
| F139 Einseitiges und Zweiseitiges Testen | |
| F139 Einseitiges und Zweiseitiges Testen | Ein statistisches Model, das eine gerichtete Hypothese prüft, wird einseitiger Test genannt. Wird eine ungerichtete Hypothese geprüft, wird ein zweiseitiger Test verwendet. |
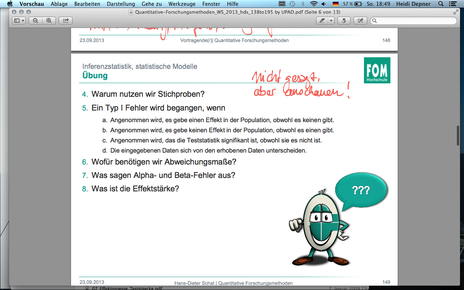
| F141 Alpha und Beta Fehler | In der Wissenschaft können immer nur Stichproben getestet werden. Die Verteilung der Variablen in der Grundgesamtheit ist jedoch nie bekannt. So gibt es immer eine gewisse Wahrscheinlichkeit, mit der man sich bei der Verallgemeinerung von Untersuchungsergebnissen auf die Grundgesamtheit irren kann. Hier wird zwischen zwei Arten des "Irrens" unterschieden: 1. Man nimmt die Alternativhypothese (H1) an, obwohl die Nullhypothese (H0) gilt (α-Fehler oder Typ I Fehler). 2. Man nimmt die Nullhypothese (H0) an, obwohl die Alternativhypothese (H1) gilt (β-Fehler oder Typ II Fehler). |
| F143 Teststärke / Effektstärke / Power | Ist ein Effekt in der Population relativ klein, so besteht (auch bei wiederholter Messung) die Gefahr, den Effekt in den Stichproben nicht zu entdecken. Bei sehr großen Stichproben können auch schon kleinste Effekte zu signifikanten Ergebnissen führen. Um dies zu minimieren, kann man die Teststärke bestimmen. In der empirischen Forschung interessiert nicht nur, ob ein Effekt vorhanden ist (Ablehnung der Nullhypothese) oder nicht (Annahme der Nullhypothese), sondern auch wie groß der Effekt ist. Die Effektstärke ist ein standardisiertes statistisches Maß, das die relative Größe eines Effektes angibt. Ein Effekt liegt vor, wenn in einem statistischen Test die Nullhypothese (=kein Effekt) abgelehnt wird. Die Effektstärke gibt dann Auskunft über die Größe des Effekts. Sie dient damit auch zur Verdeutlichung der praktischen Relevanz von signifikanten Ergebnissen. Nicht nur die statistische Signifikanz ist für die Bedeutsamkeit eines Ergebnisses ausschlaggebend. Die Größe und Richtung eines Effektes (z.B. Mittelwertsunterschied, Zusammenhang) sind inhaltlich ebenfalls relevant. Die APA (American Psychological Association) empfiehlt das Berichten von Effektgrößen zusätzlich zu den Ergebnissen statistischer Tests zur Veranschaulichung der inhaltlichen Bedeutsamkeit eines Ergebnisses. Die Effektstärke ist ein objektives und standardisiertes Maß der Größe von beobachteten Effekten. Die Standardisierung ermöglicht den Vergleich von Effektstärken aus verschiedenen Studien. Zum Beispiel: Produkt-Moment-Korrelation (r) |
| F148 Übung - Welche Aussage über eine 95% Konfidenzintervall ist wahr? | a.95 von 100 Stichprobenmittelwerte befinden sich innerhalb des Konfidenzintervalls b.Es gibt eine 95%-ige Wahrscheinlichkeit, dass die Population sich innerhalb des Konfidenzintervalls befindet c.95 von 100 Konfidenzintervallen enthalten den Mittelwert der Population d.Es gibt eine 5%-ige Wahrscheinlichkeit, dass der Mittelwert der Population innerhalb des Konfidenzintervalls liegt. --> c |
| F 148 Übung - Der Grad, mit dem ein statistisches Modell die erhobenen Daten abbildet, nennt man: | a) Fit b) Homogenität c) Reliabilität d) Validität |
| F149 - Übung | |
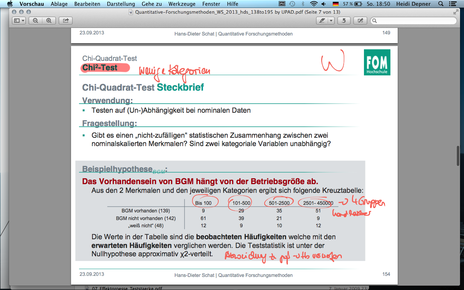
| F154 Chi2 Test | Testen auf (Un-)Abhängigkeit bei nominalen Daten Gibt es einen „nicht-zufälligen“ statistischen Zusammenhang zwischen zwei nominalskalierten Merkmalen? Sind zwei kategoriale (Nominal & Ordinalskalen) Variablen unabhängig? Bsp. Besteht ein Zusammenhang zwischen Geschlecht und Alter? → Chi² Test möglich |
| F154 Chi2 Test | |
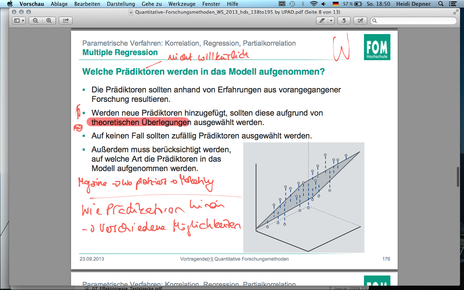
| F176 Multiple Regression | |
| F185/ F186 Wahl der Regressionsmethode | 1. Hierarchisch 2. Forced Entry 3. Schrittweise 4. All-Subsets Methode |
| F185/ F186 Wahl der Regressionsmethode - Hierarchisch - | Bei einer hierarchischen Regression werden zunächst bereits bekannte Prädiktoren ausgewählt und schrittweise, in der Reihenfolge ihrer vermuteten Wichtigkeit, in das Modell aufgenommen. Im nächsten Schritt werden weitere (vermutete) Prädiktoren schrittweise in das Modell aufgenommen. |
| F185/ F186 Wahl der Regressionsmethode - Forced Entry - | Es werden alle Prädiktoren simultan in das Modell aufgenommen. Die Reihenfolge der Aufnahme spielt dabei keine Rolle. |
| F185/ F186 Wahl der Regressionsmethode - Schrittweise - | Bei einer schrittweisen Regression wird die Reihenfolge, in der die Prädiktoren in das Modell aufgenommen werden, mathematisch bestimmt. Bei der vorwärts gerichteten, schrittweisen Regression wird geprüft, welcher Prädiktor am höchsten mit der Kriteriumsvariable korreliert. Dieser Prädiktor wird in das Modell aufgenommen. Der zweite Prädiktor wird danach ausgewählt wie viel zusätzliche Varianz er zum ersten Prädiktor aufklärt. Dies wird solange fortgeführt, bis ein neuer Prädiktor die Qualität des Modells nicht weiter verbessert. Bei der rückwärts gerichteten schrittweisen Regression wird genau umgekehrt vorgegangen. Es werden zunächst alle Prädiktoren aufgenommen und solange Prädiktoren entfernt, bis die Qualität des Modells nicht weiter verbessert wird. Es ist auch möglich in beide Richtungen vorzugehen. Dabei wird vorwärts gerichtet begonnen und mit der Aufnahme eines neuen Prädiktors wird geprüft, ob die Entfernung des |
| F185/ F186 Wahl der Regressionsmethode - All-Subsets Methode - | Es werden alle möglichen Kombinationen von Prädiktoren ausprobiert und geprüft, welche Kombination den besten Fit ergibt. |
| F193 Konzept des t-Tests | |
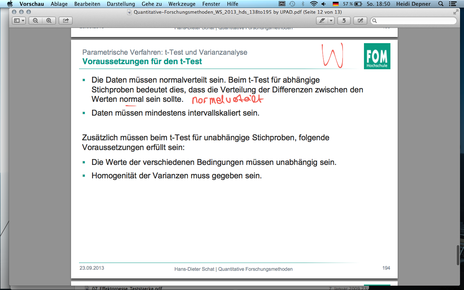
| F194 - Voraussetzungen für den t-Test | |
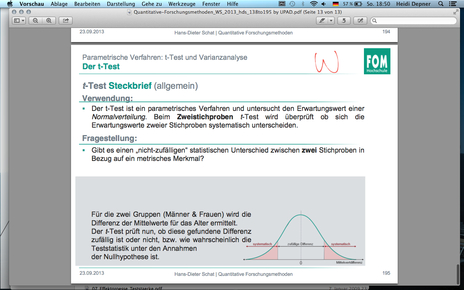
| F195 Der t-Test - Steckbrief (allgemein) |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Möchten Sie mit GoConqr kostenlos Ihre eigenen Karteikarten erstellen? Mehr erfahren.